
To get started with dbt, learn the command line and Git, how dbt connects to your warehouse, how it organizes data into layers, and the modeling concepts behind your tables.
You don't have to master any of it first. You just need to know it exists and why it matters.
Plenty of teams still run their transformations as stored procedures or a homegrown framework someone wrote years ago. The logic grows into thousands of lines spread across procedures and scripts, nobody can see how one piece connects to the next, and a change in one place quietly breaks something three steps downstream. You find out when a stakeholder asks why their numbers look wrong. When the person who built it leaves, the knowledge walks out with them.
dbt brings software engineering discipline to your transformations. Every model is version-controlled SQL the whole team can read. Dependencies are explicit through ref() and source(), so you get lineage for free instead of reverse-engineering it. Tests run automatically, and changes ship through pull requests like any other code. That's the shift analysts make when they move into analytics engineering, and it's why dbt is worth learning.
dbt replaces stored procedures and custom frameworks with version-controlled SQL, automatic lineage, and tests that run in CI.
Stored procedures and custom frameworks compared with dbt.
Here's the short list, roughly in the order it tends to come up.
Command line basics. dbt runs from the terminal, so get comfortable there before anything else. You'll spend your day with cd, ls, mkdir, and the dbt commands themselves. If the terminal is new to you, Terminal Tutor builds the muscle memory quickly, and the dbt cheat sheet covers the dbt commands and selectors you'll reach for most.
Git fundamentals. Git is its own skill, separate from the command line, and it's how real dbt work ships. Learn clone, add, commit, push, and pull first, then move on to branching and pull requests, since that's how every team reviews and merges changes. The official Git tutorials and this walkthrough will get you there.
Profiles. Your profile tells dbt how to connect to your warehouse. If it's misconfigured, nothing runs, so it's worth getting right early and then you can mostly forget about it.
Keep profiles.yml in ~/.dbt, not in your project folder, and never commit it, since it holds your credentials (dbt docs on connection profiles). Datacoves and dbt Cloud both handle this part for you. The dbt terminology post breaks down how targets and outputs work inside the file.
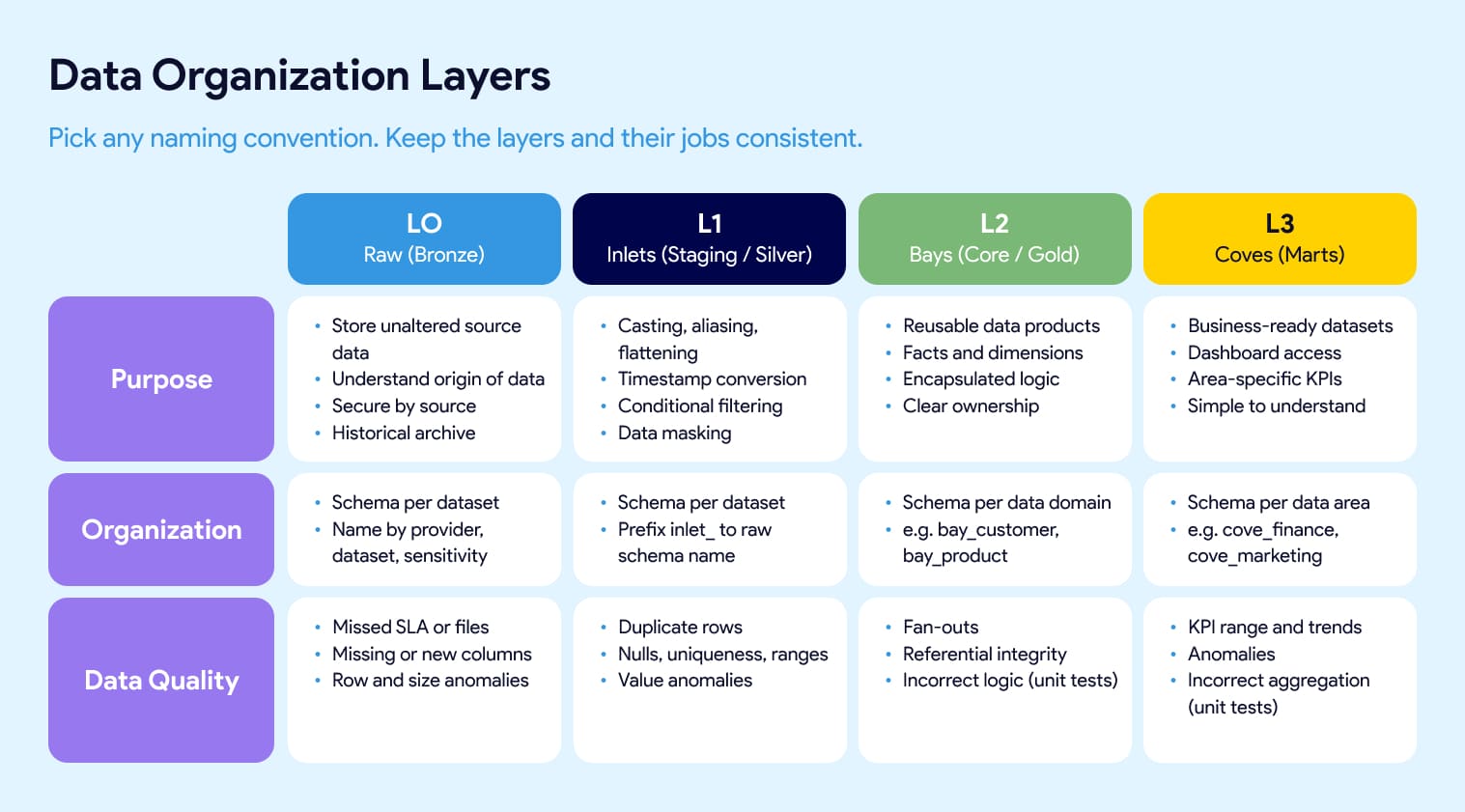
Data layers. Most dbt projects organize models into layers: raw, staging, core, and marts. You'll also hear bronze, silver, and gold. At Datacoves we use inlets, bays, and coves. They all map to the same idea. Raw lands untouched so you can trace origin and keep history. Staging does light cleanup like casting, aliasing, and flattening. Core is where reusable facts and dimensions get built. Marts are the business-facing models people actually query. Treat the names as an interchangeable convention. The part that affects your project is consistency: agree as a team on where facts and dims live, what each layer is responsible for, and which tests belong at each level. Our inlets, bays, and coves guide shows one way to define that.
Data layer names like staging, silver, and inlets are interchangeable conventions; the thing that affects your project is whether your team uses them consistently.
Ref vs source. This distinction tells you whether you actually understand lineage.
Use source() to reference raw tables loaded outside dbt and ref() to reference other dbt models.
Get them right and dbt builds your dependency graph for you. The dbt Jinja functions cheat sheet has the syntax.
Data modeling concepts. Before you write a model, learn the basics of dimensional modeling. Start with Kimball and the star schema, since it's still the most widely used approach (Kimball Group's dimensional modeling techniques). Primary keys, foreign keys, composite keys, and surrogate keys all live here, and they're what keep your data trustworthy once it's joined. This video is a quick tour of the main modeling approaches, and dbt-utils gives you generate_surrogate_key so you don't hand-roll them (see the dbt-utils cheat sheet).
Macros. Macros are reusable pieces of SQL logic, written with Jinja. Once they click, you'll wonder how you wrote SQL without them. Keep them in folders organized by purpose instead of dumping everything into one file, or your macros directory turns into a junk drawer fast. The dbt Jinja cheat sheet covers the syntax.
Seeds. Seeds are small static CSVs that dbt loads into your warehouse. Use them for cross-reference and lookup files, things like country codes or account mappings, not for loading real data. Keep them stable, since changing a seed means a code release. When the file's columns change, reload it with dbt seed --full-refresh. There's more in the dbt terminology post.
YML files. YML files hold your documentation, tests, and config. Don't pile everything into one giant sources.yml or models.yml. Use one file per source or model folder, prefixed with an underscore like _google_analytics.yml, so it sorts to the top of the folder and lives right next to what it describes. Small, focused files are far easier to find and review.
dbt tests. Tests catch problems before they reach a dashboard. dbt ships with generic tests like unique and not_null, you can write your own singular tests as plain SQL, and packages like dbt-expectations and dbt-utils add more. Start simple and add coverage where it hurts. Our overview of dbt testing options lays out when to use each.
Snapshots. Snapshots capture how a record changed over time, which is dbt's answer to slowly changing dimensions. You'll want this the first time someone asks what a customer's status was three months ago. The dbt docs on snapshots are the place to start.
Incremental models. When full refreshes start hurting, incremental models are what save you. Instead of rebuilding a table from scratch on every run, dbt only processes new or changed rows. You won't need this on day one, but you'll be glad you know it exists when a table gets big. The analytics glossary has a quick definition.
A few resources worth bookmarking as you go:

You'll pick up most of this on the job. The point of the list is that when these concepts show up, and they will, you'll recognize them instead of getting stuck. That's the individual side of dbt.
Running dbt across a team is a bigger job. Someone has to settle your Git repository structure and branching strategy, decide how many environments and schemas you need, set dbt development standards and approve the packages and macros people can use, stand up CI/CD and Slim CI, write the documentation and SQL linting rules, build the Airflow orchestration, and handle PII masking and warehouse roles. Those choices are the foundation a mature stack sits on, and reversing them later is painful.
Datacoves manages the platform and sets up the foundational DataOps and security decisions, so teams go from zero to a mature data stack in weeks.
That's where Datacoves comes in, on both fronts. We manage the platform, so your team isn't maintaining dbt, Airflow, and CI/CD on Kubernetes. And our Data Architecture Foundation engagement sets those decisions up with you, from Git and environment design to CI/CD, documentation and linting standards, orchestration, and PII handling, so a team can go from zero to a mature stack in weeks. If that's where you're headed, a free architecture review is a good place to start.

Managing Snowflake infrastructure is harder than it should be. The tools that exist either weren’t built for Snowflake specifically, cover only part of what you need to manage, or come with a permission model so opinionated it stops fitting your org somewhere around the second business unit. Most teams end up with a mix: one tool for grants, a script for provisioning, manual clicks for everything else. It works for a while, but doesn't scale well.
Snowcap is an open-source tool built to manage the whole thing in one place.
If you prefer a quick walkthrough, watch the video below.
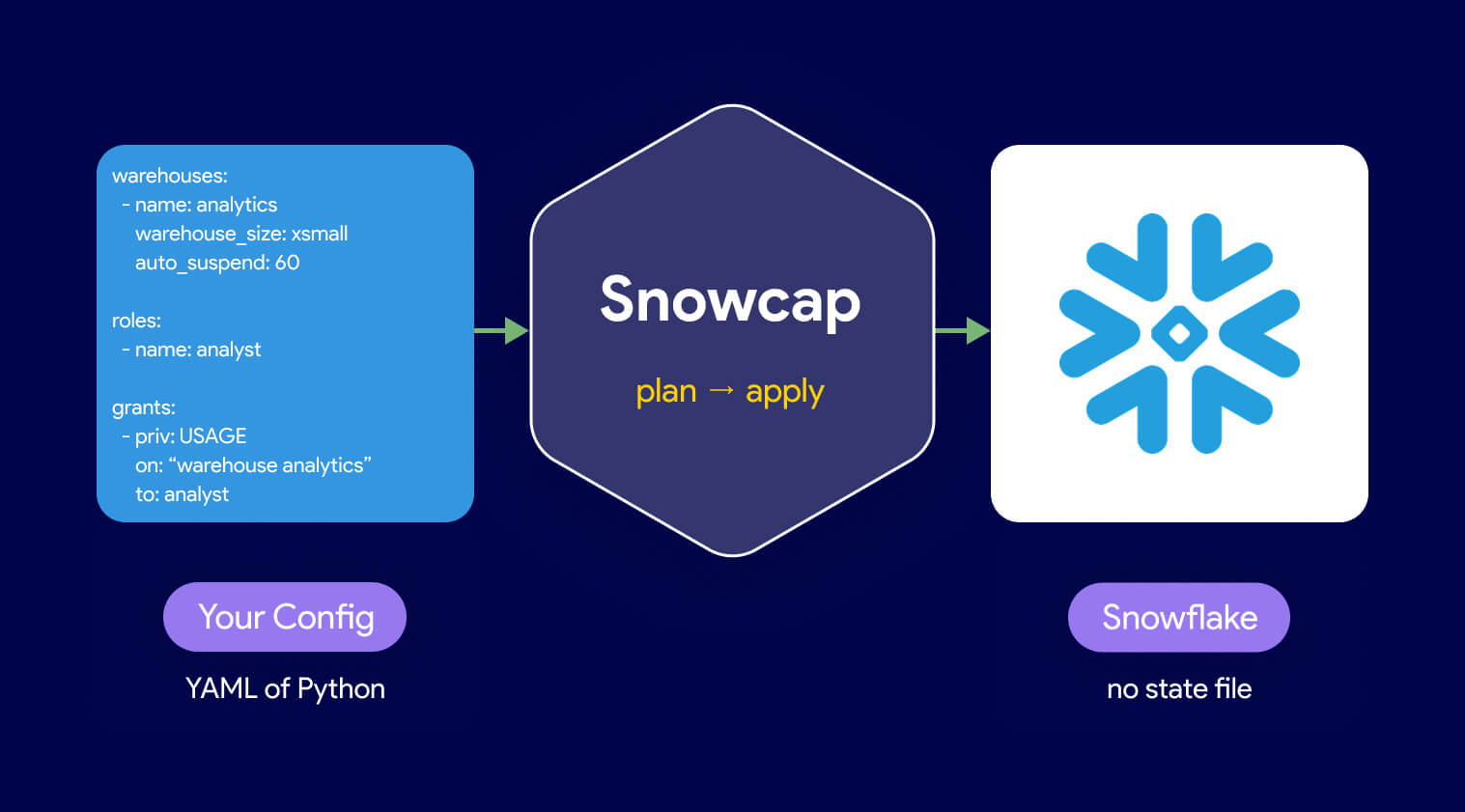
Snowcap is a Snowflake-native infrastructure as code tool, open source and maintained by Datacoves. You define your Snowflake resources in YAML or Python, run snowcap plan to see what would change, and run snowcap apply to make it happen. That’s the loop.
Pro-Tip: if you are using Snowcap against an existing Snowflake account DO NOT sync resources as that will override anything in your account with what is defined in your Snowcap configs. We also advise you always run snowcap plan and validate all snowflake changes before applying them.There’s no state file. Instead of tracking your infrastructure in a local or remote file that drifts the moment someone makes a change outside the tool, Snowcap queries Snowflake directly on every run. It compares your config against what’s actually in the account and generates the SQL to make them match. If an admin creates a warehouse through the UI, Snowcap knows about it the next time you run. Nothing to reconcile.
Most IaC tools for Snowflake manage one slice of your account. Snowcap manages the full surface area: warehouses, databases, schemas, roles, users, grants, dynamic tables, hybrid tables, masking policies, row access policies, stages, pipes, streams, tasks, stored procedures, UDFs, integrations, and more. Over 60 resource types in total.
Configuration scales with your needs. For simple setups, a single YAML file is enough. For complex environments with dozens of business units or regional role variants, Snowcap supports templating: define a pattern once and apply it across a list. What used to mean copy-pasting a config block forty times becomes a single definition.
Snowcap is available now. The full documentation is at snowcap.datacoves.com. If you have an existing Snowflake account and want to see what your current setup would look like as config, snowcap export generates it for you, but this may need optimization if you have a Snowflake account with a lot of objects.
The next post in this series covers installation, authentication, and your first real config from scratch.
Snowcap is how we manage Datacoves deployments. To see how it fits into the full stack, visit datacoves.com/snowflake.

Most enterprise data platform projects don't fail because of the tools. They fail because nobody in the room, not IT, not the consulting firm, not the vendor, had ever seen what a well-built platform actually looks like. So decisions get made by people delegating to other people who are also delegating. Enterprise standards get followed without being questioned. And two years later, you have a platform that works well enough to demo, moves too slowly to trust, and can only be changed by the team that built it. That's a predictable outcome of a broken process.
Most enterprise data platform projects don't fail because of the tools. They fail because nobody in the room had ever seen what a well-built platform looks like.
This article explains why it happens, what the warning signs look like from the outside, and what you should demand before you hand the keys to anyone again.
Two years ago, you had a problem. Your data was slow to get to, hard to trust, and impossible to act on. You brought it to IT. IT brought it to a consulting firm with the right logos and the right industry experience. Contracts were signed. A roadmap was presented. Everyone nodded.
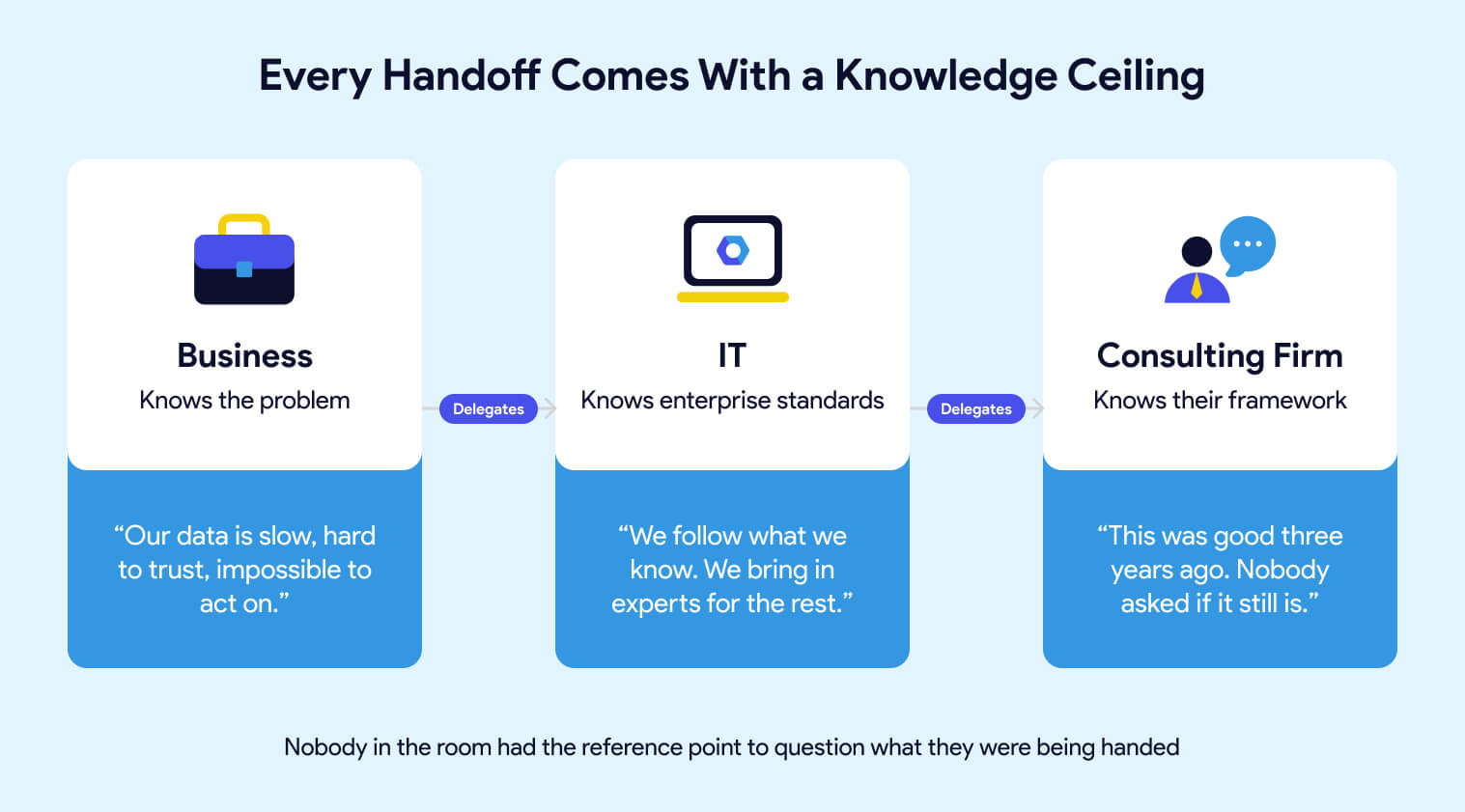
What nobody said out loud is that each handoff in that chain came with a knowledge ceiling. You knew the business problem but not the technical solution. IT knew their enterprise standards but not necessarily what best-in-class data engineering looks like. The consulting firm knew their framework, the one they'd been building for years, the one that was genuinely good when they built it. Whether it was still the right answer for where the industry is today was a question nobody asked, because nobody in the room had the reference point to ask it.
This isn't about blame. The system worked exactly as designed. It just wasn't designed to produce what you actually needed.
You don't need to understand the architecture to recognize that something is wrong. You've seen it in other ways.
Reports that take three sprints to change. Business users have stopped asking for new metrics because the process is too slow. Analysts who still use Excel because the data in the platform doesn't match what they expect. A go-live that keeps moving. Issues that surface in final testing, never earlier. A data team that spends more time firefighting than building.

These aren't symptoms of a tool problem. They're symptoms of a platform that was built to pass a demo, not to operate at scale. The foundation looked solid in the PowerPoint. Then one corner started sinking. Someone ran outside, propped it up, called it good enough, and everyone went back inside to talk about the drapes. Until the next corner started sinking.
The business lives with the consequences of decisions that were never explained to them. That's the part that should make you uncomfortable. Not because anyone was careless, but because the people making the technical decisions had never been asked to connect them back to your actual business problem.
Consulting firms sell services. The migration is the engagement. They have every incentive to deliver something that looks complete at handoff, and very little incentive to think about what happens eighteen months later when your team needs to extend it, upgrade it, or adapt it to something they didn't anticipate. If you're evaluating migration partners, here's what to look for.
That's just the business model. A platform built on open-source tools with documented conventions, enforced by the system rather than by people remembering to follow a process, doesn't generate the same ongoing billing as one that requires the original team to come back every time something needs to change. Someone who built one of these frameworks told me it was "good three years ago." That's a telling phrase. Good three years ago means it was already aging when it was delivered.
dbt, Airflow, SQLFluff, and the open-source ecosystem around them move fast because there are thousands of contributors and companies whose entire existence depends on making them better. A proprietary consulting framework moves at the pace of whoever owns it, if it moves at all.
The gap compounds. New Airflow capabilities require the consulting firm to schedule an upgrade. Framework changes require them to build it. Every month that passes, the distance between what's possible and what your team can actually access gets wider. Your engineers know it. They read the release notes. They see what other teams are doing. They just can't do it themselves because the platform wasn't built to be owned by them.
The teams that don't have this problem didn't get lucky. They built on a foundation that was designed to evolve, with tools maintained by communities that have no interest in keeping anyone dependent.
Every business leader has a GenAI mandate right now. Boards want it. CEOs are asking about it. And the instinct is to treat it as a separate initiative, something you layer on top of what you already have.
That's the mistake.
Think about your power grid. Nobody questions whether the lights will turn on when they flip the switch. That reliability exists because someone built generation, transmission, and distribution correctly before anyone thought about what to plug in. You're being asked to build a smart home on a grid that browns out every Tuesday.

AI is only as reliable as the data underneath it. If your data has no lineage, inconsistent definitions, and no documentation, your AI initiative will produce outputs nobody trusts, at scale, faster than you've ever produced untrustworthy outputs before.
According to Gartner, organizations will abandon 60% of AI projects unsupported by AI-ready data by 2026.
The data quality problems that were always there don't disappear under a GenAI layer. They get amplified and made visible in the worst possible moment, in front of the stakeholders you most need to impress.
The foundation isn't a data engineering problem. It's the prerequisite to the most important initiative on your roadmap. Getting it right isn't IT's job to delegate. It's your decision to make.

A well-built platform doesn't rely on people following the process correctly every time. It makes the wrong action difficult.
The difference between a platform that scales and one that doesn't usually isn't visible in a demo. It shows up six months after go-live, when the team doubles, when a consultant rolls off, when someone new joins, and has to figure out how things work by reading documentation that may or may not exist.
A well-built platform doesn't rely on people following the process correctly every time. It makes the wrong action difficult. Automated checks run before anything can merge, so code quality doesn't depend on a reviewer having a good day. Naming conventions live in the tooling itself, not in a document that gets read once during onboarding. Pipeline dependencies are declared explicitly and validated automatically, so a missed configuration doesn't quietly cause a downstream failure three sprints later. A new engineer who joins the team inherits those guardrails on day one without reading a document or asking anyone how things work. The knowledge is in the system, not in the heads of the people who built it.
Good data engineering is a thought-out combination of tools that work well together, each maintained by a community that cares about making it better. The people improving dbt, Airflow, and SQLFluff aren't doing it on a consulting firm's project timeline. They're doing it because their companies depend on those tools getting better continuously.
dbt-coves automates the tedious parts of dbt development. dbt-checkpoint enforces data quality standards at commit time, before bad code ever reaches a pipeline. SQLFluff keeps SQL consistent across every engineer on the team. Snowcap manages Snowflake infrastructure as code, the thing that's perpetually "on the roadmap" in consulting-built platforms but never quite arrives.
None of these tools is the answer on its own. The answer is that someone chose them deliberately, integrated them carefully, and built a platform where they work together. That's the difference between a workshop that was designed and one that just accumulated tools over time.
It also means your platform can adapt. When a better approach emerges, you adopt it. Your engineers can use Claude Code, GitHub Copilot, Snowflake Cortex, or any other AI tool that fits their workflow. They're not waiting for a vendor to build an integration or a consulting firm to schedule a framework update. Some platforms give you one AI tool and call it done. That's a product decision masquerading as a strategy.
If you're about to start a data platform engagement with a consulting firm, a platform vendor, or anyone else, these are the questions worth asking before you sign.
Can you show me a client whose team ships on their own cadence, without your firm in the critical path for day-to-day decisions? Managing infrastructure is a legitimate service. What you want to avoid is a vendor who ends up managing your decisions, your roadmap, and your team's ability to move without them. That relationship tends to get more expensive over time, not less.
What open-source tools does your framework use, and how do you handle upgrades when new versions are released? A proprietary framework that wraps open-source tools is only as current as whoever maintains the wrapper. Find out who that is and how often it happens.
What happens if a business user needs a new metric? Walk me through the process end-to-end, including who approves it, how long it takes, and what the business user can do themselves. The answer will tell you whether they're building you an industrial kitchen or planning to cook everything for you. Business users are smart enough to use a knife. A platform built on that assumption looks very different from one built on the assumption that they aren't.
Who on our team will own the business logic, the models, and the deployment process? Not the infrastructure, the work. A good partner manages the complexity underneath so your engineers can focus on delivering. If the answer to ownership is vague, the engagement was designed around their continuity, not yours.
How do you handle the Snowflake security model, and can you show me examples? This one is worth asking even if you don't fully understand the answer. Pay attention to whether they answer with confidence and specificity, or whether they say "this came directly from Snowflake" as if that settles it. It doesn't. A recommendation from a Snowflake account team is a starting point, not an architecture.
Most leaders assume that doing things right means slowing down. That getting the foundation in place before starting to deliver means months of invisible work before anyone sees results. That's not how this works.

The Datacoves Foundation's engagement takes less than two months.
In that time, you get:
The goal is to move slowly to move fast. Not slow forever. Slow for eight weeks, so your team isn't spending the next three years propping up corners. Skip the foundation, and you move fast for the first six months, then spend the next three years explaining why everything takes so long. Get it right and your team ships twice a week without being afraid of what they might break.
Guitar Center onboarded in days, not months. Johnson and Johnson described it as a framework accelerator. A team at DataDrive saved over 200 hours annually by replacing a fragile self-built pipeline with something that actually held up at scale. None of them spent 18 months waiting to find out if it would work.
Without a solid foundation, your GenAI initiative will surface data problems at the worst possible moment. Your business users will keep working around the platform instead of in it. And your engineers will keep moving carefully instead of moving fast.
You shouldn't have to build this from scratch. Most teams already paid someone to do it. They just didn't get it.

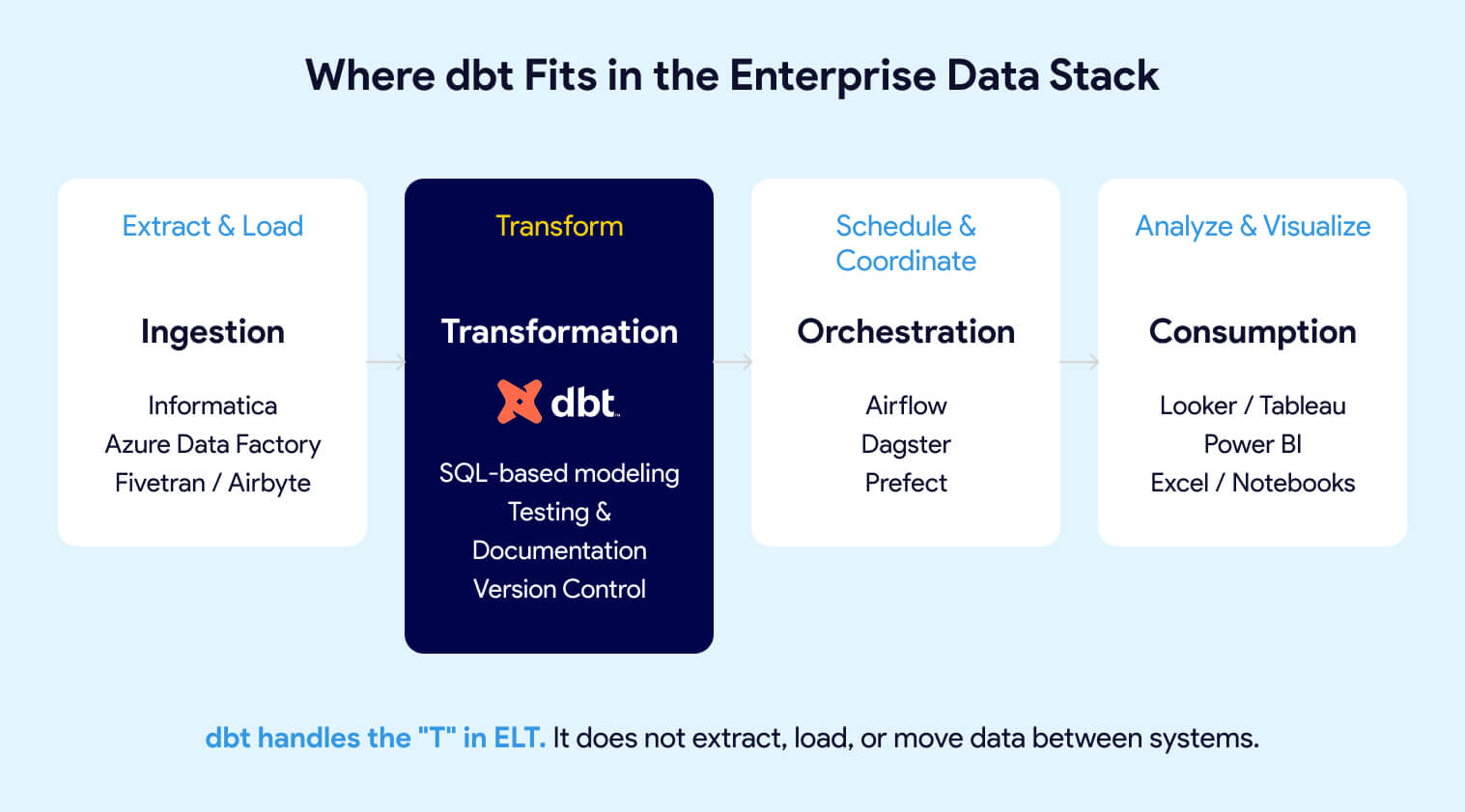
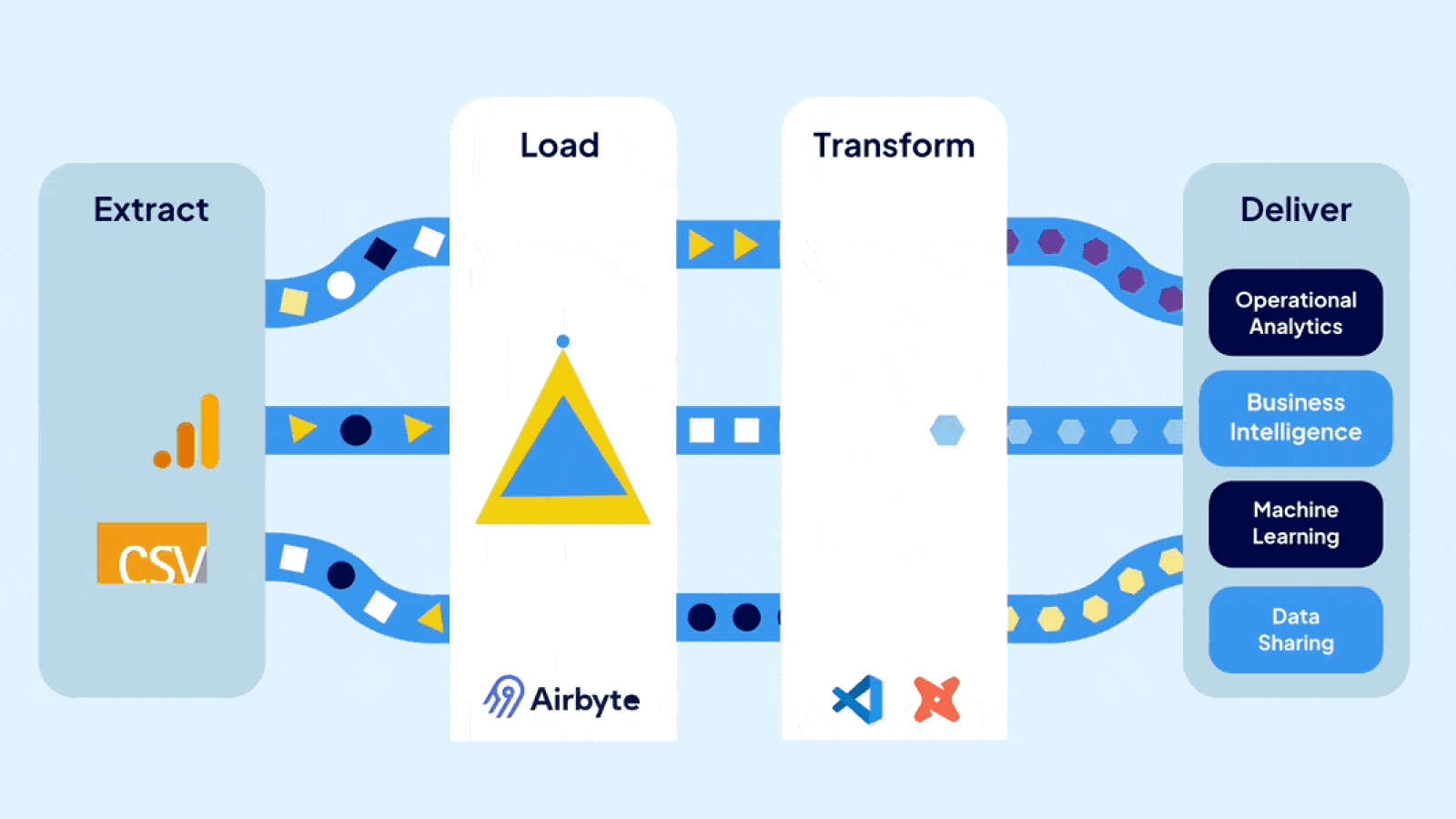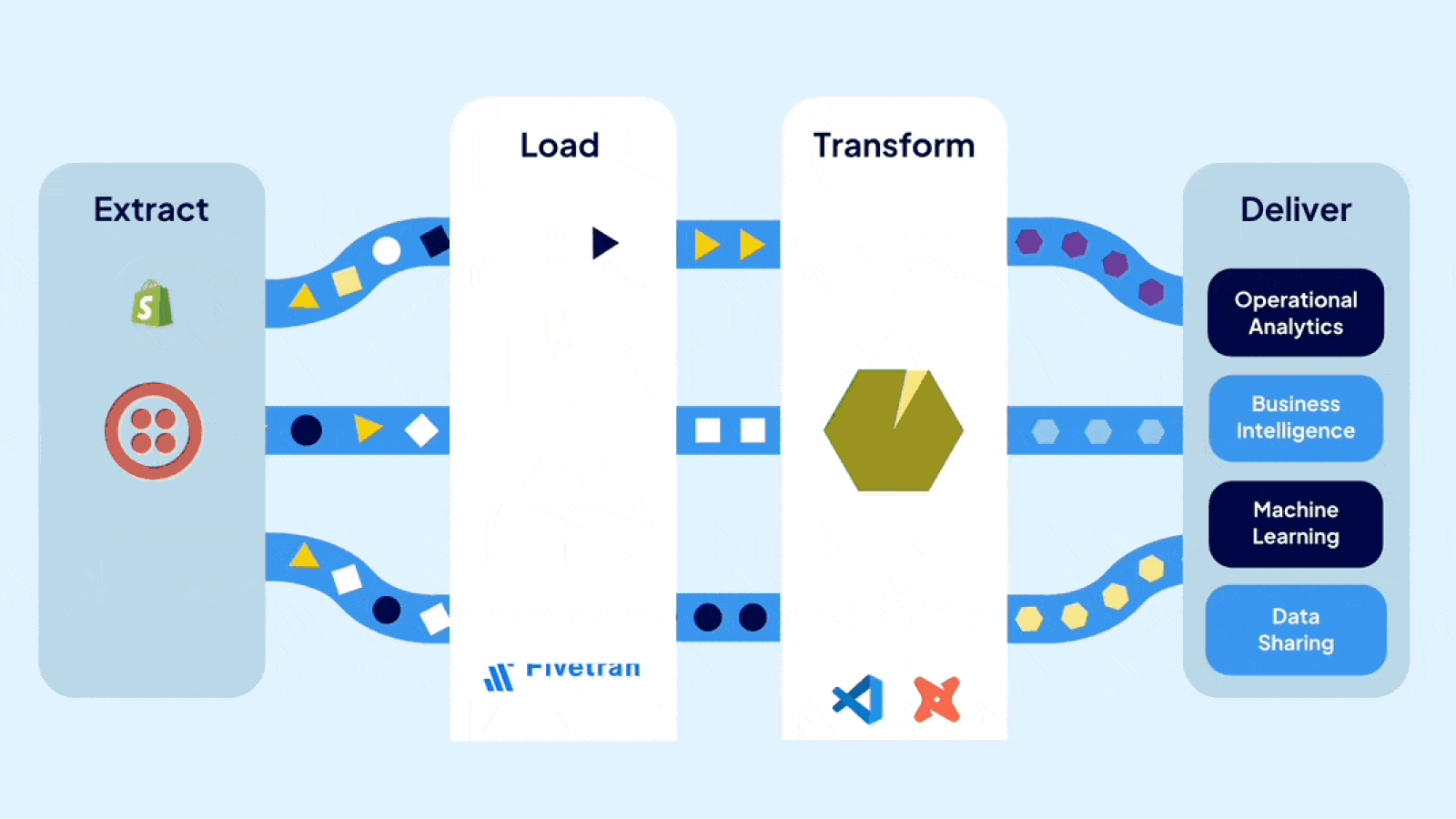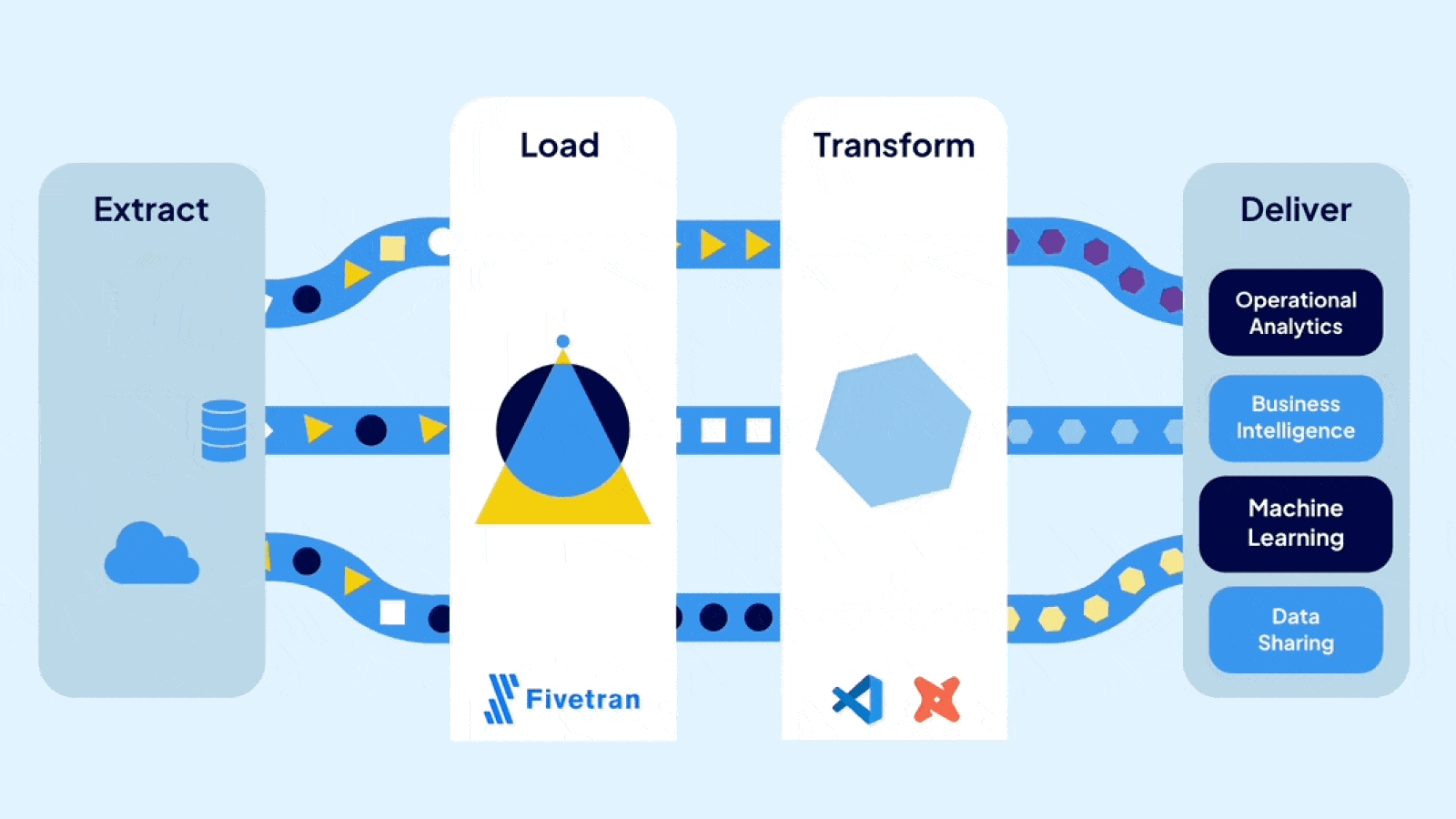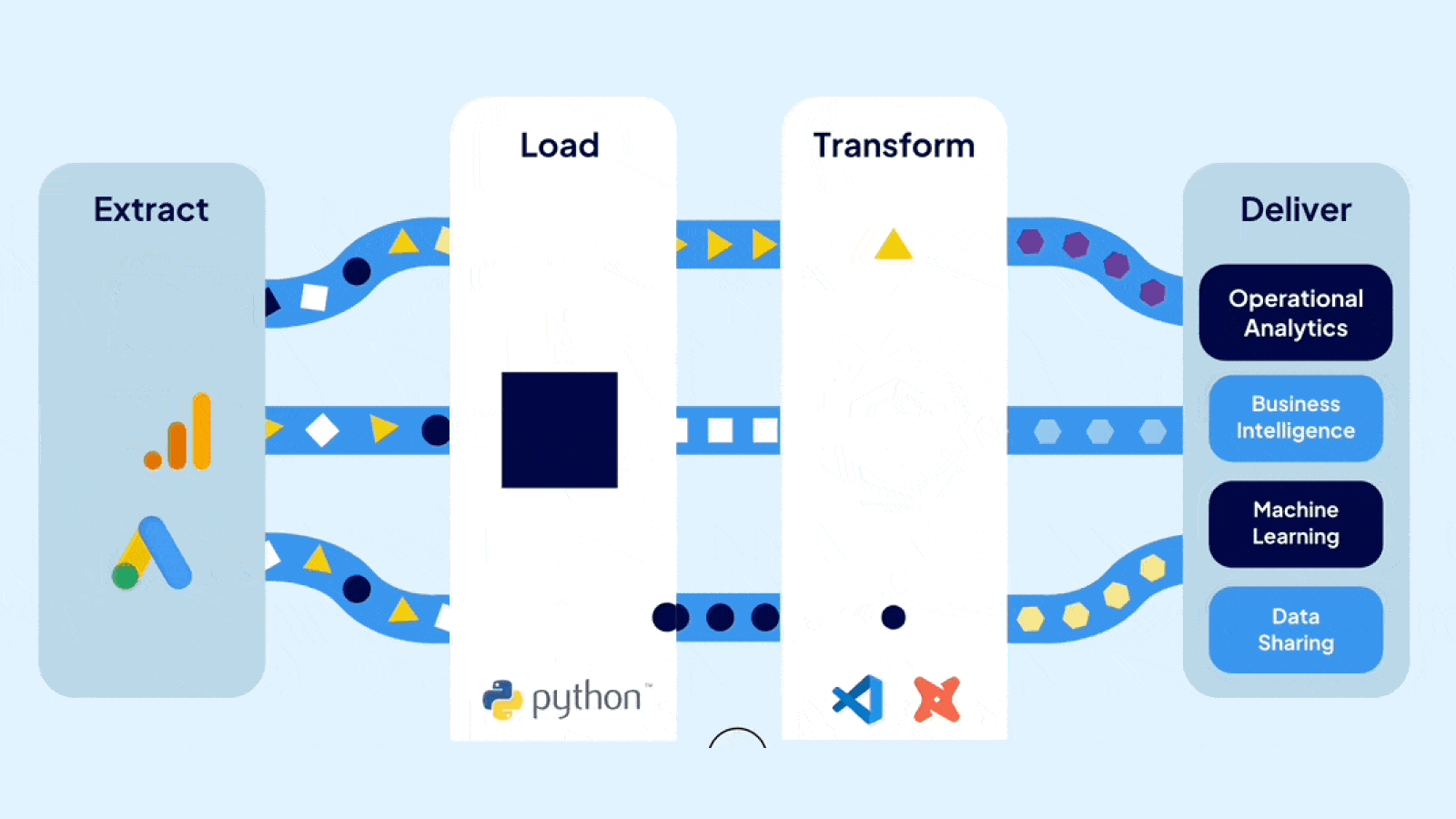
dbt (data build tool) is a SQL-based transformation framework that turns raw data into trusted, analytics-ready datasets directly inside your data warehouse. It brings software engineering discipline to analytics: version control, automated testing, CI/CD, and auto-generated documentation. dbt handles the "T" in ELT. It does not extract, load, or move data.
dbt focuses exclusively on the transformation layer of ELT (Extract, Load, Transform). Unlike traditional ETL tools that handle the entire pipeline, dbt assumes data already exists in your warehouse. Ingestion tools like Informatica, Azure Data Factory, or Fivetran load the raw data. dbt transforms it into trusted, analytics-ready datasets.
A dbt project consists of SQL files called models. Each model is a SELECT statement that defines a transformation. When you run dbt, it compiles these models, resolves dependencies, and executes the SQL directly in your warehouse. The results materialize as tables or views. Data never leaves your warehouse.
Example: A Simple dbt Model (models/marts/orders_summary.sql)
SELECT
customer_id,
COUNT(*) AS total_orders,
SUM(order_amount) AS lifetime_value,
MIN(order_date) AS first_order_date
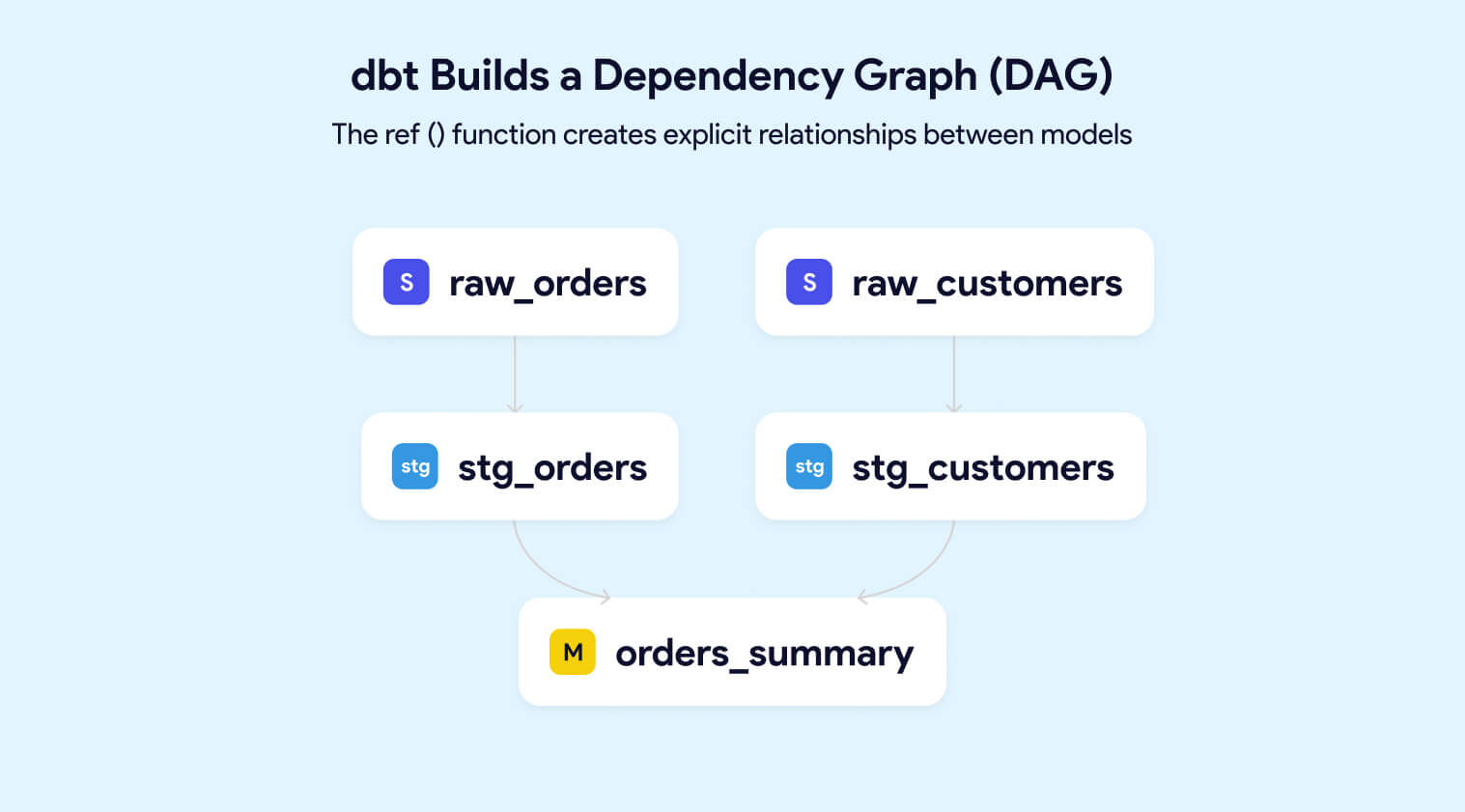
FROM {{ ref('stg_orders') }}
GROUP BY customer_idThe {{ref('stg_orders')}} syntax creates an explicit dependency. dbt uses these references to build a dependency graph (DAG) of your entire pipeline, ensuring models run in the correct order.
For large datasets, dbt supports incremental models that process only new or changed data. This keeps pipelines fast and warehouse costs controlled as data volumes grow.
With dbt, teams can:
dbt handles the "T" in ELT. It does not extract, load, or move data between systems.
Misaligned expectations are a primary cause of failed dbt implementations. Knowing what dbt does not do matters as much as knowing what it does.
This separation of concerns is intentional. By focusing exclusively on transformation, dbt allows enterprises to evolve their ingestion, orchestration, and visualization layers independently. You can swap Informatica for Azure Data Factory or migrate from Redshift to Snowflake without rewriting your business logic.
dbt is a tool, not a strategy. Organizations with unclear data ownership, no governance framework, or misaligned incentives will not solve those problems by adopting dbt. They will simply have the same problems with versioned SQL.
For a deeper comparison, see dbt vs Airflow: Which data tool is best for your organization?
Over 30,000+ companies use dbt weekly, including JetBlue, HubSpot, Roche, J&J, Block, and Nasdaq dbt Labs, 2024 State of Analytics Engineering
Enterprise adoption of dbt has accelerated because it solves problems that emerge specifically at scale. Small teams can manage transformation logic in spreadsheets and ad hoc scripts. At enterprise scale, that approach creates compounding risk.
dbt has moved well beyond startups into regulated, enterprise environments:
Life Sciences: Roche, Johnson & Johnson (See how J&J modernized their data stack with dbt), and pharmaceutical companies with strict compliance requirements
These are not proof-of-concept deployments. These are production systems powering executive dashboards, regulatory reporting, and customer-facing analytics.
Without a standardized transformation layer, enterprise analytics fails in predictable ways:
Organizations report 45% of analyst time is spent finding, understanding, and fixing data quality issues Gartner Data Quality Market Survey, 2023
dbt addresses these problems by treating transformation logic as production code:

One of the most underappreciated reasons enterprises adopt dbt is leverage. dbt is not just a transformation framework. It sits at the center of a broad ecosystem that reduces implementation risk and accelerates delivery.
dbt packages are reusable projects available at hub.getdbt.com. They provide pre-built tests, macros, and modeling patterns that let teams leverage proven approaches instead of building from scratch.
Popular packages include:
Using packages signals operational maturity. It reflects a preference for shared, tested patterns over bespoke solutions that create maintenance burden. Mature organizations also create internal packages they can share across teams to leverage learnings across the company.
dbt integrates with the broader data stack through its rich metadata (lineage, tests, documentation):
Because dbt produces machine-readable metadata, it acts as a foundation that other tools build on. This makes dbt a natural anchor point for enterprise data platforms.
The dbt Slack community has 100,000+ members sharing patterns, answering questions, and debugging issues dbt Labs Community Stats, 2024
For enterprises, community size matters because:
When you adopt dbt, you are not just adopting a tool. You are joining an ecosystem with momentum.
A typical dbt workflow follows software engineering practices familiar to any developer:
models:
- name: orders_summary
description: "Customer-level order aggregations"
columns:
- name: customer_id
description: "Primary key from source system"
tests:
- unique
- not_null
- name: lifetime_value
description: "Sum of all order amounts in USD" For executives and data leaders, dbt is less about SQL syntax and more about risk reduction and operational efficiency.
Organizations implementing dbt with proper DataOps practices report:
dbt supports enterprise governance requirements by making transformations explicit and auditable:
The question for enterprise leaders is not "Should we use dbt?" The question is "How do we operate dbt as production infrastructure?"
dbt Core is open source, and many teams start by running it on a laptop. But open source looks free the way a free puppy looks free. The cost is not in the acquisition. The cost is in the care and feeding.
For a detailed comparison, see Build vs Buy Analytics Platform: Hosting Open-Source Tools.
The hard part is not installing dbt. The complexity comes from everything around it:
Building your own dbt platform is like wiring your own home: possible, but very few teams should. Most enterprises find that building and maintaining this infrastructure becomes a distraction from their core mission of delivering data products.
dbt delivers value when supported by clear architecture, testing standards, CI/CD automation, and a platform that enables teams to work safely at scale.
Skip the Infrastructure. Start Delivering.
Datacoves provides managed dbt and Airflow deployed in your private cloud, with pre-built CI/CD, VS Code environments, and best-practice architecture out of the box. Your data never leaves your network. No VPC peering required.
Learn more about Managed dbt + Airflow
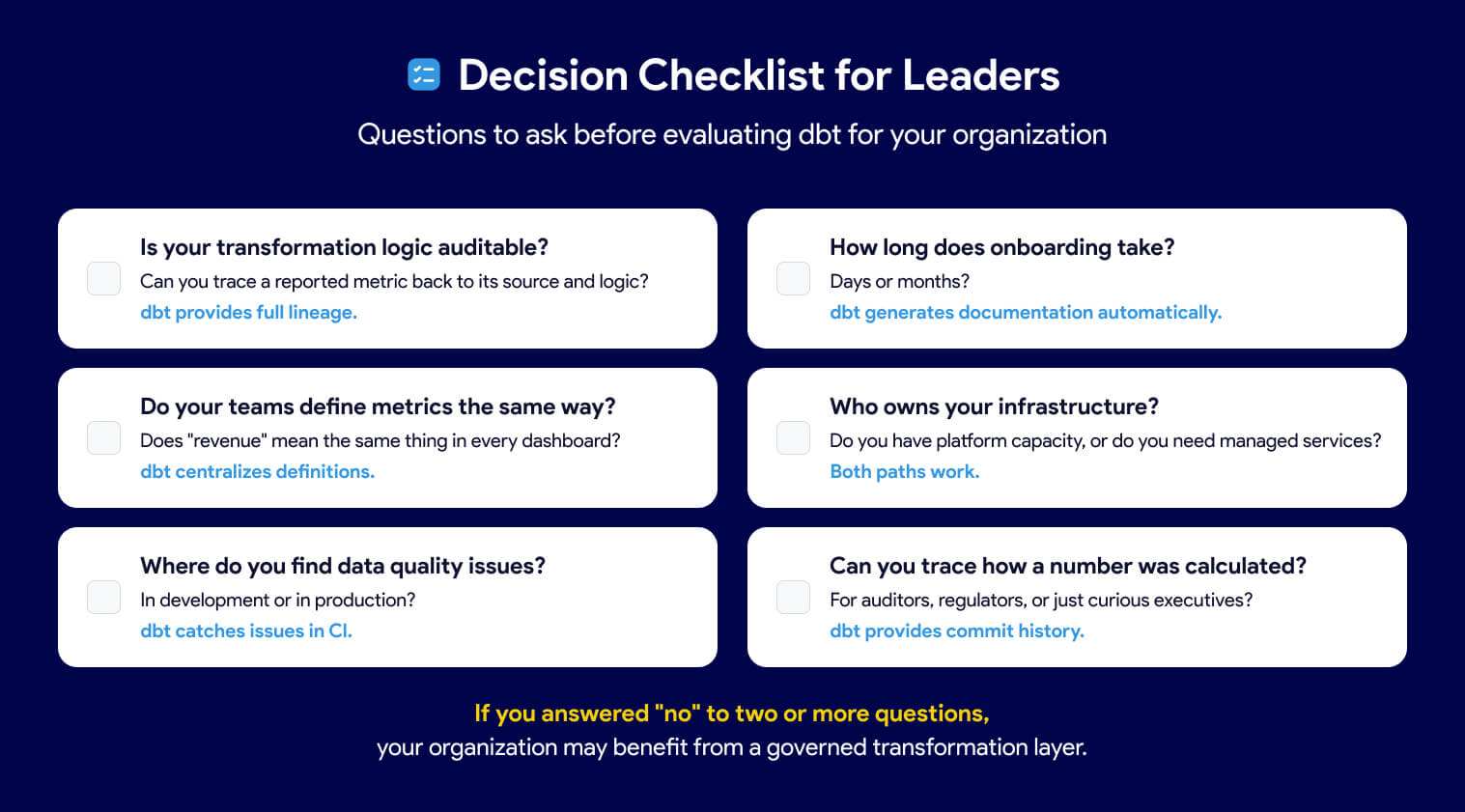
Before adopting or expanding dbt, leaders should ask:
Is your transformation logic auditable? If business rules live in dashboards, stored procedures, or tribal knowledge, the answer is no. dbt makes every transformation visible, version-controlled, and traceable.
Do your teams define metrics the same way? If "revenue" or "active user" means different things to different teams, you have metric drift. dbt centralizes definitions in code so everyone works from a single source of truth.
Where do you find data quality issues? If problems surface in executive dashboards instead of daily data quality check, you lack automated testing. dbt runs tests on every build, catching issues before they reach end users.
How long does onboarding take? If new analysts spend weeks decoding tribal knowledge, your codebase is not self-documenting. dbt generates documentation and lineage automatically from code.
Who owns your infrastructure? Decide whether your engineers should be building platforms or building models. Operating dbt at scale requires CI/CD, orchestration, environments, and security. That work must live somewhere.
Can you trace how a number was calculated? If auditors or regulators ask how a reported figure was derived, you need full lineage from source to dashboard. dbt provides that traceability by design.
dbt has become the standard for enterprise data transformation because it makes business logic visible, testable, and auditable. But the tool alone is not the strategy. Organizations that treat dbt as production infrastructure, with proper orchestration, CI/CD, and governance, unlock its full value. Those who skip the foundation often find themselves rebuilding later.
Ready to skip the infrastructure complexity? See how Datacoves helps enterprises operate dbt at scale

A lean analytics stack built with dlt, DuckDB, DuckLake, and dbt delivers fast insights without the cost or complexity of a traditional cloud data warehouse. For teams prioritizing speed, simplicity, and control, this architecture provides a practical path from raw data to production-ready analytics.
In practice, teams run this stack using Datacoves to standardize environments, manage workflows, and apply production guardrails without adding operational overhead.
A lean analytics stack built with dlt, DuckDB, DuckLake, and dbt delivers fast, production-ready insights without the cost or complexity of a traditional cloud data warehouse.
A lean analytics stack works when each tool has a clear responsibility. In this architecture, ingestion, storage, and transformation are intentionally separated so the system stays fast, simple, and flexible.
Together, these tools form a modern lakehouse-style stack without the operational cost of a traditional cloud data warehouse.
Running DuckDB locally is easy. Running it consistently across machines, environments, and teams is not. This is where MotherDuck matters.
MotherDuck provides a managed control plane for DuckDB and DuckLake, handling authentication, metadata coordination, and cloud-backed storage without changing how DuckDB works. You still query DuckDB. You just stop worrying about where it runs.
To get started:
MOTHERDUCK_TOKEN).This single token is used by dlt, DuckDB, and dbt to authenticate securely with MotherDuck. No additional credentials or service accounts are required.
At this point, you have:
That consistency is what makes the rest of the stack reliable.
In a lean data stack, ingestion should be reliable, repeatable, and boring. That is exactly what dlt is designed to do.
dlt loads raw data into DuckDB with strong defaults for schema handling, incremental loads, and metadata tracking. It removes the need for custom ingestion frameworks while remaining flexible enough for real-world data sources.
In this example, dlt ingests a CSV file and loads it into a DuckDB database hosted in MotherDuck. The same pattern works for APIs, databases, and file-based sources.
To keep dependencies lightweight and avoid manual environment setup, we use uv to run the ingestion script with inline dependencies.
pip install uv
touch us_populations.py
chmod +x us_populations.pyThe script below uses dlt’s MotherDuck destination. Authentication is handled through the MOTHERDUCK_TOKEN environment variable, and data is written to a raw schema in DuckDB.
#!/usr/bin/env -S uv run
# /// script
# dependencies = [
# "dlt[motherduck]==1.16.0",
# "psutil",
# "pandas",
# "duckdb==1.3.0"
# ]
# ///
"""Loads a CSV file to MotherDuck"""
import dlt
import pandas as pd
from utils.datacoves_utils import pipelines_dir
@dlt.resource(write_disposition="replace")
def us_population():
url = "https://raw.githubusercontent.com/dataprofessor/dashboard-v3/master/data/us-population-2010-2019.csv"
df = pd.read_csv(url)
yield df
@dlt.source
def us_population_source():
return [us_population()]
if __name__ == "__main__":
# Configure MotherDuck destination with explicit credentials
motherduck_destination = dlt.destinations.motherduck(
destination_name="motherduck",
credentials={
"database": "raw",
"motherduck_token": dlt.secrets.get("MOTHERDUCK_TOKEN")
}
)
pipeline = dlt.pipeline(
progress = "log",
pipeline_name = "us_population_data",
destination = motherduck_destination,
pipelines_dir = pipelines_dir,
# dataset_name is the target schema name in the "raw" database
dataset_name="us_population"
)
load_info = pipeline.run([
us_population_source()
])
print(load_info)Running the script loads the data into DuckDB:
./us_populations.pyAt this point, raw data is available in DuckDB and ready for transformation. Ingestion is fully automated, reproducible, and versionable, without introducing a separate ingestion platform.
Once raw data is loaded into DuckDB, transformations should follow the same disciplined workflow teams already use elsewhere. This is where dbt fits naturally.
dbt provides version-controlled models, testing, documentation, and repeatable builds. The difference in this stack is not how dbt works, but where tables are materialized.
By enabling DuckLake, dbt materializes tables as Parquet files with centralized metadata instead of opaque DuckDB-only files. This turns DuckDB into a true lakehouse engine while keeping the developer experience unchanged.
To get started, install dbt and the DuckDB adapter:
pip install dbt-core==1.10.17
pip install dbt-duckdb==1.10.0
dbt initNext, configure your dbt profile to target DuckLake through MotherDuck:
default:
outputs:
dev:
type: duckdb
# This requires the environment var MOTHERDUCK_TOKEN to be set
path: 'md:datacoves_ducklake'
threads: 4
schema: dev # this will be the prefix used in the duckdb schema
is_ducklake: true
target: devThis configuration does a few important things:
MOTHERDUCK_TOKEN environment variableWith this in place, dbt models behave exactly as expected. Models materialized as tables are stored in DuckLake, while views and ephemeral models remain lightweight and fast.
From here, teams can:
This is the key advantage of the stack: modern analytics engineering practices, without the overhead of a traditional warehouse.
This lean stack is not trying to replace every enterprise data warehouse. It is designed for teams that value speed, simplicity, and cost control over heavyweight infrastructure.
This approach works especially well when:
The trade-offs are real and intentional. DuckDB and DuckLake excel at analytical workloads and developer productivity, but they are not designed for high-concurrency BI at massive scale. Teams with hundreds of dashboards and thousands of daily users may still need a traditional warehouse.
Where this stack shines is time to value. You can move from raw data to trusted analytics quickly, with minimal infrastructure, and without locking yourself into a platform that is expensive to unwind later.
In practice, many teams use this architecture as:
When paired with Datacoves, teams get the operational guardrails this stack needs to run reliably. Datacoves standardizes environments, integrates orchestration and CI/CD, and applies best practices so the simplicity of the stack does not turn into fragility over time.
Teams often run this stack with Datacoves to standardize environments, apply production guardrails, and avoid the operational drag of DIY platform management.
If you want to see this stack running end to end, watch the Datacoves + MotherDuck webinar. It walks through ingestion with dlt, transformations with dbt and DuckLake, and how teams operationalize the workflow with orchestration and governance.
The session also covers:

The merger of dbt Labs and Fivetran (which we refer to as dbt Fivetran for simplicity) represents a new era in enterprise analytics. The combined company is expected to create a streamlined, end-to-end data workflow consolidating data ingestion, transformation, and activation with the stated goal of reducing operational overhead and accelerating delivery. Yet, at the dbt Coalesce conference in October 2025 and in ongoing conversations with data leaders, many are voicing concerns about price uncertainty, reduced flexibility, and the long-term future of dbt Core.
As enterprises evaluate the implications of this merger, understanding both the opportunities and risks is critical for making informed decisions about their organization's long-term analytics strategy.
In this article, you’ll learn:
1. What benefits could the dbt Fivetran merger offer enterprise data teams
2. Key risks and lessons from past open-source acquisitions
3. How enterprises can manage risks and challenges
4. Practical steps dbt Fivetran can take to address community anxiety

For enterprise data teams, the dbt Fivetran merger may bring compelling opportunities:
1. Integrated Analytics Stack:
The combination of ingestion, transformation, and activation (reverse ETL) processes may enhance onboarding by streamlining contract management, security evaluations, and user training.
2. Resource Investment:
The merged company has the potential to speed up feature development across the data landscape. Open data standards like Iceberg could see increased adoption, fostering interoperability between platforms such as Snowflake and Databricks.
While these prospects are enticing, they are not guaranteed. The newly formed organization now faces the non-trivial task of merging various teams, including Fivetran, HVR (Oct 2021), Census (May 2025), SQLMesh/Tobiko (Sept 2025), and dbt Labs (Oct 2025). Successfully integrating their tools, development practices, and support functions will be crucial. To create a truly seamless, end-to-end platform, alignment of product roadmaps, engineering standards, and operational processes will be necessary. Enterprises should carefully assess the execution risks when considering the promised benefits of this merger, as these advantages hinge on Fivetran's ability to effectively integrate these technologies and teams.

The future openness and flexibility of dbt Core is being questioned, with significant consequences for enterprise data teams that rely on open-source tooling for agility, security, and control.
dbt’s rapid adoption, now exceeding 80,000 projects, was fueled by its permissive Apache License and a vibrant, collaborative community. This openness allowed organizations to deploy, customize, and extend dbt to fit their needs, and enabled companies like Datacoves to build complementary tools, sponsor open-source projects, and simplify enterprise data workflows.
However, recent moves by dbt Labs, accelerated by the Fivetran merger, signal a natural evolution toward monetization and enterprise alignment:
1. Licensing agreement with Snowflake
2. Rewriting dbt Core as dbt Fusion under a more restrictive ELv2 license
3. Introducing a “freemium” model for the dbt VS Code Extension, limiting free use to 15 registered users per organization

While these steps are understandable from a business perspective, they introduce uncertainty and anxiety within the data community. The risk is that the balance between open innovation and commercial control could tip, raising understandable questions about long-term flexibility that enterprises have come to expect from dbt Core.
dbt Labs and Fivetran have both stated that dbt Core's license would not change, and I believe them. The vast majority of dbt users are using dbt Core and changing the licenses risks fragmentation and loss of goodwill in the community. The future vision for dbt is not dbt Core, but instead dbt Fusion.
While I see a future for dbt Core, I don't feel the same about SQLMesh. There is little chance that the dbt Fivetran organization would continue to invest in two open-source projects. It is also unlikely that SQLMesh innovations would make their way into dbt Core, as that would directly compete with dbt Fusion.
Recent history offers important cautionary tales for enterprises. While not a direct parallel, it’s worth learning from:
1. Terraform: A license change led to fragmentation and the creation of OpenTofu, eroding trust in the original steward.
2. ElasticSearch: License restrictions resulted in the OpenSearch fork, dividing the community and increasing support risks.
3. Redis and MongoDB: Similar license shifts caused forks or migrations to alternative solutions, increasing risk and migration costs.
For enterprise data leaders, these precedents highlight the dangers of vendor fragmentation, increased migration costs, and uncertainty around long-term support. When foundational tools become less open, organizations may face difficult decisions about adapting, migrating, or seeking alternatives. If you're considering your options, check out our Platform Evaluation Worksheet.
On the other hand, there are successful models where open-source projects and commercial offerings coexist and thrive:
1. Airflow: Maintains a permissive license, with commercial providers offering managed services and enterprise features.
2. GitLab, Spark, and Kafka: Each has built a sustainable business around a robust open-source core, monetizing through value-added services and features.
These examples show that a healthy open-source core, supported by managed services and enterprise features, can benefit all stakeholders, provided the commitment to openness remains.
To navigate the evolving landscape, enterprises should:
1. Monitor licensing and governance changes closely.
2. Engage in community and governance discussions to advocate for transparency.
3. Plan for contingencies, including potential migration or multi-vendor strategies.
4. Diversify by avoiding over-reliance on a single vendor or platform.
Avoid Vendor Lock-In:
1. Continue to leverage multiple tools for data ingestion and orchestration (e.g., Airflow) instead of relying solely on a single vendor’s stack.
2. Why? This preserves your ability to adapt as technology and vendor priorities evolve. While tighter tool integration is a potential promise of consolidation, options exist to reduce the burden of a multi-tool architecture.
For instance, Datacoves is built to help enterprises maintain governance, reliability, and freedom of choice to deploy securely in their own network, specifically supporting multi-tool architectures and open standards to minimize vendor lock-in risk.
Demand Roadmap Transparency:
1. Engage with your vendors about their product direction and advocate for community-driven development.
2. Why? Transparency helps align vendor decisions with your business needs and reduces the risk of disruptive surprises.
Participate in Open-Source Communities:
1. Contribute to and help maintain the open-source projects that underpin your data platform.
2. Why? Active participation ensures your requirements are heard and helps sustain the projects you depend on.
Attend and Sponsor Diverse Conferences:
1. Support and participate in community-driven events (such as Airflow Summit) to foster innovation and avoid concentration of influence.
2. Why? Exposure to a variety of perspectives leads to stronger solutions and a healthier ecosystem.
Support OSS Creators Financially and Through Advocacy:
1. Sponsor projects or directly support maintainers of critical open-source tools.
2. Why? Sustainable funding and engagement are vital for the health and reliability of the open-source ecosystem.
Encourage Openness and Diversity
1. Champion Diversity in OSS Governance: Advocate for broad, meritocratic project leadership and a diverse contributor base.
2. Why? Diverse stewardship drives innovation, resilience, and reduces the risk of any one entity dominating the project’s direction.
Long-term analytics success isn’t just about technology selection. It’s about actively shaping the ecosystem through strategic diversification, transparent vendor engagement, and meaningful support of open standards and communities. Enterprises that invest in these areas will be best equipped to thrive, no matter how the vendor landscape evolves.
While both dbt Labs and Fivetran have stated that the dbt Core license would remain permissive, to preserve trust and innovation in the data community, dbt Fivetran should commit to neutral governance and open standards for dbt Core, ensuring it remains a true foundation for collaboration, not fragmentation.
It is common knowledge that the dbt community has powered a remarkable flywheel of innovation, career growth, and ecosystem expansion. Disrupting this momentum risks technical fragmentation and loss of goodwill, outcomes that benefit no one in the analytics landscape.
To maintain community trust and momentum, dbt Fivetran should:
1. Establish Neutral Governance:
Place dbt Core under independent oversight, where its roadmap is shaped by a diverse set of contributors, not just a single commercial entity. Projects like Iceberg have shown that broad-based governance sustains engagement and innovation, compared to more vendor-driven models like Delta Lake.
2. Consider Neutral Stewardship Models:
One possible long-term approach that has been seen in projects like Iceberg and OpenTelemetry is to place an open-source core under neutral foundation governance (for example, the Linux Foundation or Apache Software Foundation).
While dbt Labs and Fivetran have both reaffirmed their commitment to keeping dbt Core open, exploring such models in the future could further strengthen community trust and ensure continued neutrality as the platform evolves.
3. Encourage Meritocratic Development: Empower a core team representing the broader community to guide dbt Core’s future. This approach minimizes the risk of forks and fragmentation and ensures that innovation is driven by real-world needs.
4. Apply Lessons from MetricFlow: When dbt Labs acquired MetricFlow and changed its license to BSL, it led to further fragmentation in the semantic layer space. Now, with MetricFlow relicensed as Apache and governed by the Open Semantic Interchange (OSI) initiative (including dbt Labs, Snowflake, and Tableau), the project is positioned as a vendor-neutral standard. This kind of model should be considered for dbt Core as well.
1. Technical teams: By ensuring continued access to an open, extensible framework, and reducing the risk of disruptive migration.
2. Business leaders: By protecting investments in analytics workflows and minimizing vendor lock-in or unexpected costs.
Solidifying dbt Core as a true open standard benefits the entire ecosystem, including dbt Fivetran, which is building its future, dbt Fusion, on this foundation. Taking these steps would not only calm community anxiety but also position dbt Fivetran as a trusted leader for the next era of enterprise analytics.
The dbt Fivetran merger represents a defining moment for the modern data stack, promising streamlined workflows while simultaneously raising critical questions about vendor lock-in, open-source governance, and long-term flexibility. Successfully navigating this shift requires a proactive, diversified strategy, one that champions open standards and avoids over-reliance on any single vendor. Enterprises that invest in active community engagement and robust contingency planning will be best equipped to maintain control and unlock maximum value from their analytics platforms.
If your organization is looking for a way to mitigate these risks and secure your workflows with enterprise-grade governance and multi-tool architecture, Datacoves offers a managed platform designed for maximum flexibility and control. For a deeper look, find out what Datacoves has to offer.
Ready to take control of your data future? Contact us today to explore how Datacoves allows organizations to take control while still simplifying platform management and tool integration.

Data orchestration is the foundation that ensures every step in your data value chain runs in the correct order, with the right dependencies, and with full visibility. Without it, even the best tools such as dbt, Airflow, Snowflake, or your BI platform operate in silos. This disconnect creates delays, data fires, and unreliable insights.
For executives, data orchestration is not optional. It prevents fragmented workflows, reduces operational risk, and helps teams deliver trusted insights quickly and consistently. When orchestration is built into the data platform from the start, organizations eliminate hidden technical debt, scale more confidently, and avoid the costly rework that slows innovation.
In short, data orchestration is how modern data teams deliver reliable, end-to-end value without surprises.
In today’s fast-paced business environment, executives are under increased pressure to deliver quick wins and measurable results. However, one capability that is often overlooked is data orchestration.
This oversight can sabotage progress as the promise of data modernization efforts fails to deliver expected outcomes in terms of ROI and improved efficiencies.
In this article, we will explain what data orchestration is, the risks of not implementing proper data orchestration, and how executives benefit from end-to-end data orchestration.
Data orchestration ensures every step in your data value chain runs in the right order, with the right dependencies, and with full visibility.
Data orchestration is the practice of coordinating all the steps in your organization’s data processes so they run smoothly, in the right order, and without surprises. Think of it as the conductor ensuring each instrument plays at the right time to create beautiful music.
Generating insights is a multi-tool process. What’s the problem with this setup? Each of these tools may include its own scheduler, and they will each run in a silo. Even if an upstream step fails or is delayed, the subsequent steps will run. This disconnect leads to surprises for executives expecting trusted insights. This in turn, leads to delays and data fires, which are disruptive and inefficient for the organization.
Imagine you are baking a chocolate cake. You would need a recipe, all the ingredients, and a functioning oven. However, you wouldn’t turn on the oven before buying the ingredients and mixing the batter if your milk had spoiled. Not having someone orchestrating all the steps in the right sequence would lead to a disorganized process that is inefficient and wasteful. You also know not to continue if there is a critical issue, such as spoiled milk.
Data orchestration solves the problem of having siloed tools by connecting all the steps in the data value chain. This way, if one step is delayed or fails, subsequent steps do not run. With a data orchestration tool, we can also notify someone to resolve the issue so they can act quickly, reducing fires and providing visibility to the entire process.
ETL (Extract, Transform, and Load) focuses on moving and transforming data, but data orchestration is about making sure everything happens in the right sequence across all tools and systems. It’s the difference between just having the pieces of a puzzle and putting them together into a clear picture.
Without data orchestration, even the best tools operate in silos, creating delays, data fires, and unreliable insights.
Executives make many decisions but rarely have the time to dive into technical details. They delegate research and expect quick wins, which often leads to mixed messaging. Leaders want resilient, scalable, future-proof solutions, yet they also pressure teams to deliver “something now.” Vendors exploit this tension. They sell tools that solve one slice of the data value chain but rarely explain that their product won't fix the underlying fragmentation. Quick wins may ship, but the systemic problems remain.
Data orchestration removes this friction. When workflows are unified, adding steps to the data flow is straightforward, pipelines are predictable, and teams deliver high-quality data products faster and with far fewer surprises.
A major Datacoves customer summarized the difference clearly:
“Before, we had many data fires disrupting the organization. Now issues still occur, but we catch them immediately and prevent bad data from reaching stakeholders.”
Without orchestration, each new tool adds another blind spot. Teams don’t see failures until they hit downstream systems or show up in dashboards. This reactive posture creates endless rework, late-night outages, and a reputation problem with stakeholders.
With orchestration, failures surface early. Dependencies, quality checks, and execution paths are clear. Teams prevent incidents instead of reacting to them.
Data orchestration isn’t just about automation; it’s about governance.
It ensures:
This visibility dramatically improves trust. Stakeholders no longer get “chocolate cake” made with spoiled milk. A new tool may bake faster, but if upstream data is broken, the final product is still compromised.
Orchestration ensures the entire value chain is healthy, not just one ingredient.
Modern data teams rely heavily on tools like dbt and Airflow, but these tools do not magically align themselves. Without orchestration:
With orchestration in place, ingestion, dbt scheduling, and activation become reliable, governed, and transparent, ensuring every step runs at the right time, in the right order, with the right dependencies. Learn more in our guide on the difference between dbt Cloud vs dbt Core.
For more details on how dbt schedules and runs models, see the official dbt documentation.
To learn how Airflow manages task dependencies and scheduling, visit the official Apache Airflow documentation.
It is tempting to postpone data orchestration until the weight of data problems makes it unavoidable. Even the best tools and talented teams can struggle without a clear orchestration strategy. When data processes aren’t coordinated, organizations face inefficiencies, errors, and lost opportunities.
Implementing data orchestration early reduces hidden technical debt, prevents rework, and helps teams deliver trusted insights faster.
When data pipelines rely on multiple systems that don’t communicate well, teams spend extra time manually moving data, reconciling errors, and firefighting issues. This slows decision-making and increases operational costs.
Common symptoms of fragmented tools include:
Many organizations focus on a “quick wins” approach only to discover that the cost of moving fast was long-term lack of agility and technical debt. This approach may deliver immediate results but leads to technical debt, wasted spend, and fragile data processes that are hard to scale. A great example is Data Drive’s journey, before adding data orchestration, when issues occurred, they had to spend time debugging each step of their disconnected process. Now it is clear where an issue has occurred, enabling them to resolve issues faster for their stakeholders.
As organizations grow, the absence of orchestration forces teams to revisit and fix processes repeatedly. Embedding orchestration from the start avoids repeated firefighting, accelerates innovation, and makes scaling smoother. Improving one step alone cannot deliver the desired outcome, just like a single egg cannot make a cake.
Organizations without data orchestration are effectively flying blind. Disconnected processes run out of order and issues are discovered by frustrated stakeholders. Resource-constrained data teams spend their time firefighting instead of delivering new insights. The result is delays in decision-making, higher operating costs, and an erosion of trust in data. Embedding orchestration from the start avoids repeated firefighting, accelerates innovation, and makes scaling smoother.

If data orchestration is so important, why do organizations go without it? We often hear some common objections:
Many organizations have not heard of data orchestration and tool vendors rarely highlight this need. It’s only after a painful experience that they realize this essential need.
It’s true that data orchestration adds another layer, but without it, you have disconnected, siloed processes. The real cost comes from chaos, not from coordination.
Vendor sprawl can indeed introduce additional risks, that’s why all-in-one platforms like Datacoves reduce integration overhead by bundling enterprise-grade orchestration, like Airflow, without increasing vendor lock-in. Explore Datacoves’ Integrated Orchestration Platform.
Data value chains are inherently complex, with multiple data sources, ingestion processes, transformations, and data consumers. Data orchestration does not introduce complexity; it provides visibility and control over this complexity.
It may seem reasonable to postpone data orchestration in the short term. But every mature data organization, both large and small, eventually needs to scale. By building-in data orchestration into the data platform from the start, you set up your teams for success, reduce firefighting, and avoid costly and time-consuming rework. Most importantly, the business receives trustworthy insights faster.
Implementing data orchestration doesn’t have to be complicated. The key is to approach it strategically, ensuring that every process is aligned, visible, and scalable.
Begin by mapping your existing data processes and identifying where inefficiencies or risks exist. Knowing exactly how data flows across teams and tools allows you to prioritize the areas that will benefit most from orchestration.
Key outcomes:
Focus first on automating repetitive and error-prone steps such as data collection, cleaning, and routing. Automation reduces manual effort, frees up your team for higher-value work, and ensures processes run consistently.
Key outcomes:
Implement dashboards or monitoring tools that provide executives and teams with real-time visibility into data flows. Early detection of errors prevents costly mistakes and increases confidence in the insights being delivered.
Key outcomes:
Start small with high-impact processes and expand orchestration across more workflows over time. Scaling gradually ensures that teams adopt the changes effectively and that processes remain manageable as data volume grows.
Key outcomes:
Select tools that integrate well with your existing systems, and provide flexibility for future growth. Popular orchestration tools include dbt and Airflow, but the best choice depends on your organization’s specific workflows and needs. Explore how these capabilities come packaged in the Datacoves Platform Features overview.
Key outcomes:
Investing in data orchestration delivers tangible business value. Organizations that implement orchestration gain efficiency, reliability, and confidence in their decision-making.
Data orchestration reduces manual work, prevents duplicated efforts, and streamlines processes. Teams can focus on higher-value initiatives instead of firefighting data issues.
With coordinated workflows and monitoring, executives and stakeholders can trust the data they rely on. Decisions are backed by accurate, timely, and actionable insights.
By embedding data orchestration early, organizations avoid expensive rework, reduce errors, and prevent the accumulation of technical debt from ad hoc solutions.
Data orchestration ensures that data pipelines scale smoothly as the organization grows. Teams can launch new analytics initiatives faster, confident that their underlying processes are robust and repeatable.
Executives gain a clear view of the entire data lifecycle, enabling better oversight, risk management, and strategic planning.
Data orchestration should not be seen as a “nice to have” feature that can be postponed. Mature organizations understand that it is the foundation needed to deliver trusted insights faster. Without it, companies risk setting up siloed tools, increased data firefighting, and eroding trust in both the data and the data team. With it, organizations gain visibility, agility, and the confidence that insights fueling decisions are accurate.
The real question for strategic leaders is whether to try to piece together disconnected solutions, focusing only on short-term wins, or invest in data orchestration early and unlock the full potential of a connected ecosystem.
For executives, prioritizing data orchestration will mean fewer data fires, accelerated innovation, and an environment where trusted insights flow as reliably as the business demands.
To see how orchestration is built into the Datacoves platform, visit our Integrated Orchestration page.
Don’t wait until complexity forces your hand. Your team deserves to move faster and fight fewer fires.
Book a personalized demo to see how data orchestration with Datacoves helps leaders unlock value from day one.

The Databricks AI Summit 2025 revealed a major shift toward simpler, AI-ready, and governed data platforms. From no-code analytics to serverless OLTP and agentic workflows, the announcements show Databricks is building for a unified future.
In this post, we break down the six most impactful features announced at the summit and what they mean for the future of data teams.
Databricks One (currently in private preview) introduces a no-code analytics platform aimed at democratizing access to insights across the organization. Powered by Genie, users can now interact with business data through natural language Q&A, no SQL or dashboards required. By lowering the barrier to entry, tools like Genie can drive better, faster decision-making across all functions.
Datacoves Take: As with any AI we have used to date, having a solid foundation is key. AI can not solve ambiguous metrics and a lack of knowledge. As we have mentioned, there are some dangers in trusting AI, and these caveats still exist.
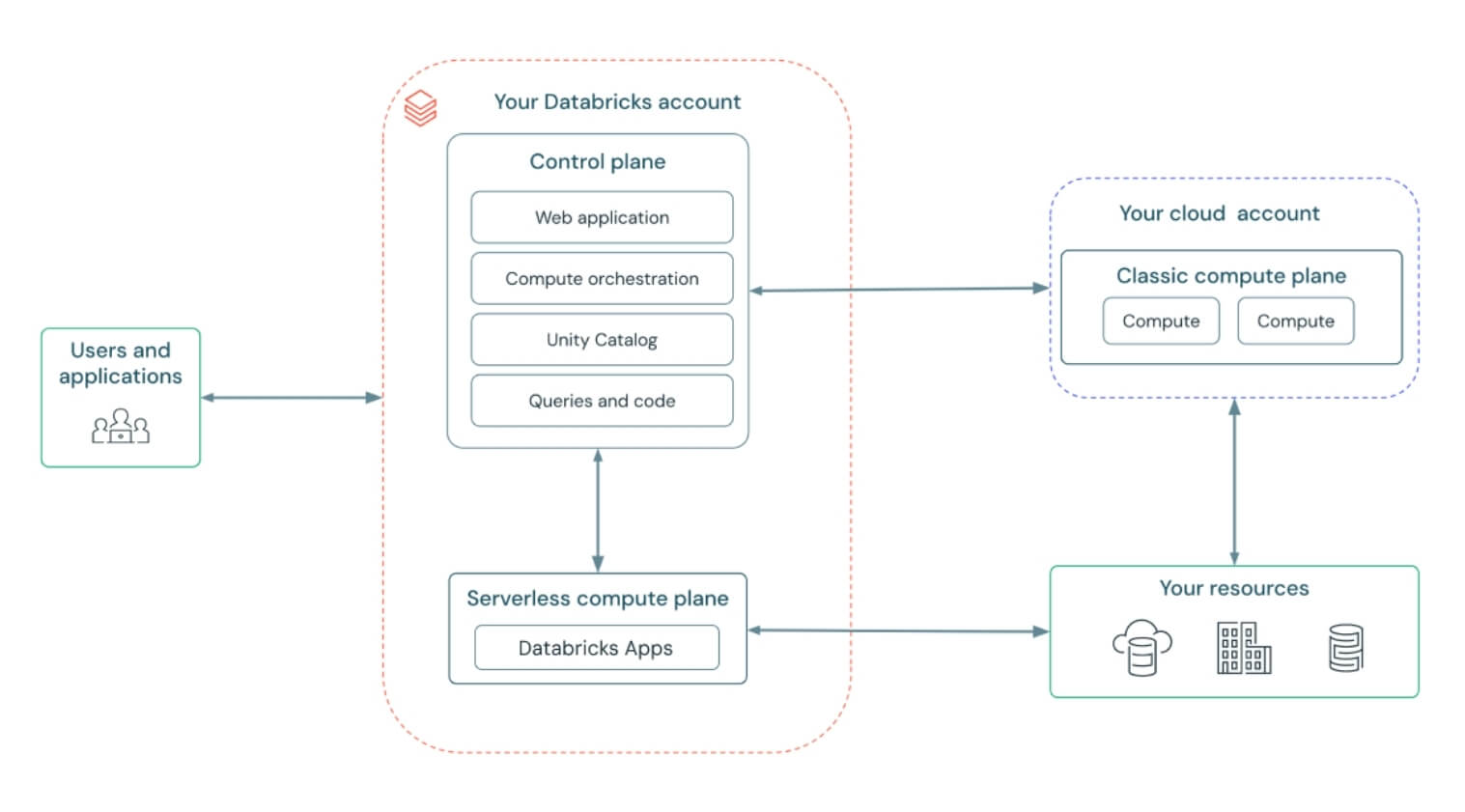
In a bold move, Databricks launched Lakebase, a Postgres-compatible, serverless OLTP database natively integrated into the lakehouse. Built atop the foundations laid by the NeonDB acquisition, Lakebase reimagines transactional workloads within the unified lakehouse architecture. This is more than just a database release; it’s a structural shift that brings transactional (OLTP) and analytical (OLAP) workloads together, unlocking powerful agentic and AI use cases without architectural sprawl.
Datacoves Take: We see both Databricks and Snowflake integrating Postgres into their offering. Ducklake is also demonstrating a simpler future for Iceberg catalogs. Postgres has a strong future ahead, and the unification of OLAP and OLTP seems certain.
With the introduction of Agent Bricks, Databricks is making it easier to build, evaluate, and operationalize agents for AI-driven workflows. What sets this apart is the use of built-in “judges” - LLMs that automatically assess agent quality and performance. This moves agents from hackathon demos into the enterprise spotlight, giving teams a foundation to develop production-grade AI assistants grounded in company data and governance frameworks.
Datacoves Take: This looks interesting, and the key here still lies in having a strong data foundation with good processes. Reproducibility is also key. Testing and proving that the right actions are performed will be important for any organization implementing this feature.
Databricks introduced Databricks Apps, allowing developers to build custom user interfaces that automatically respect Unity Catalog permissions and metadata. A standout demo showed glossary terms appearing inline inside Chrome, giving business users governed definitions directly in the tools they use every day. This bridges the gap between data consumers and governed metadata, making governance feel less like overhead and more like embedded intelligence.
Datacoves Take: Metadata and catalogs are important for AI, so we see both Databricks and Snowflake investing in this area. As with any of these changes, technology is not the only change needed in the organization. Change management is also important. Without proper stewardship, ownership, and review processes, apps can’t provide the experience promised.
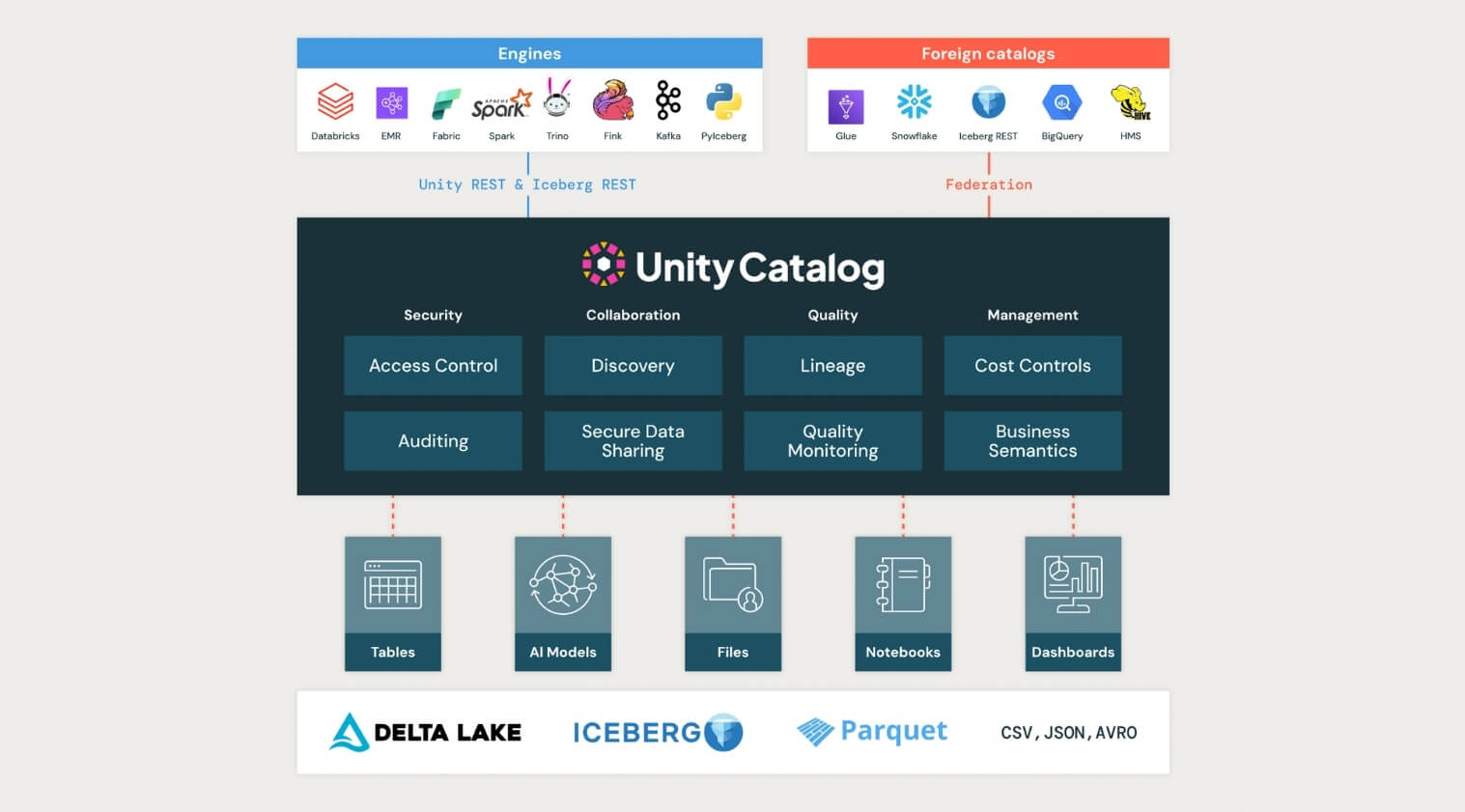
Unity Catalog took a major step forward at the Databricks AI Summit 2025, now supporting managed Apache Iceberg tables, cross-engine interoperability, and introducing Unity Catalog Metrics to define and track business logic across the organization.
This kind of standardization is critical for teams navigating increasingly complex data landscapes. By supporting both Iceberg and Delta formats, enabling two-way sync, and contributing to the open-source ecosystem, Unity Catalog is positioning itself as the true backbone for open, interoperable governance.
Datacoves Take: The Iceberg data format has the momentum behind it; now it is up to the platforms to enable true interoperability. Organizations are expecting a future where a table can be written and read from any platform. DuckLake is also getting in the game, simplifying how metadata is managed, and multi-table transactions are enabled. It will be interesting to see if Unity and Polaris take some of the DuckLake learnings and integrate them in the next few years.
In a community-building move, Databricks introduced a forever-free edition of the platform and committed $100 million toward AI and data training. This massive investment creates a pipeline of talent ready to use and govern AI responsibly. For organizations thinking long-term, this is a wake-up call: governance, security, and education need to scale with AI adoption, not follow behind.
Datacoves Take: This feels like a good way to get more people to try Databricks without a big commitment. Hopefully, competitors take note and do the same. This will benefit the entire data community.
Read the full post from Databricks here:
https://www.databricks.com/blog/summary-dais-2025-announcements-through-lens-games
With tools like Databricks One and Genie enabling no-code, natural language analytics, data leaders must prioritize making insights accessible beyond technical teams to drive faster, data-informed decisions at every level.
Lakebase’s integration of transactional and analytical workloads signals a move toward simpler, more efficient data stacks. Leaders should rethink their architectures to reduce complexity and support real-time, AI-driven applications.
Agent Bricks and built-in AI judges highlight the shift from experimental AI agents to production-ready, measurable workflows. Data leaders need to invest in frameworks and governance to safely scale AI agents across use cases.
Unity Catalog’s expanded support for Iceberg, Delta, and cross-engine interoperability emphasizes the need for unified governance frameworks that handle diverse data formats while maintaining business logic and compliance.
The launch of a free tier and $100M training fund underscores the growing demand for skilled data and AI practitioners. Data leaders should plan for talent development and operational readiness to fully leverage evolving platforms.
The Databricks AI Summit 2025 signals a fundamental shift: from scattered tools and isolated workflows to unified, governed, and AI-native platforms. It’s not just about building smarter systems; it’s about making those systems accessible, efficient, and scalable for the entire organization.
While these innovations are promising, putting them into practice takes more than vision; it requires infrastructure that balances speed, control, and usability.
That’s where Datacoves comes in.
Our platform accelerates the adoption of modern tools like dbt, Airflow, and emerging AI workflows, without the overhead of managing complex environments. We help teams operationalize best practices from day one, reducing total cost of ownership while enabling faster delivery, tighter governance, and AI readiness at scale. Datacoves supports Databricks, Snowflake, BigQuery, and any data platform with a dbt adapter. We believe in an open and interoperable feature where tools are integrated without increasing vendor lock-in. Talk to us to find out more.
Want to learn more? Book a demo with Datacoves.

Large Language Models (LLMs) like ChatGPT and Claude are becoming common in modern data workflows. From writing SQL queries to summarizing dashboards, they offer speed and support across both technical and non-technical teams. But as organizations begin to rely more heavily on these tools, the risks start to surface.
The dangers of AI are not in what it cannot do, but in what it does too confidently. LLMs are built to sound convincing, even when the information they generate is inaccurate or incomplete. In the context of data analytics, this can lead to hallucinated metrics, missed context, and decisions based on misleading outputs. Without human oversight, these issues can erode trust, waste time, and create costly setbacks.
This article explores where LLMs tend to go wrong in analytics workflows and why human involvement remains essential. Drawing from current industry perspectives and real-world examples, we will look at how to use LLMs effectively without sacrificing accuracy, accountability, or completeness.

LLMs like ChatGPT and Claude are excellent at sounding smart. That’s the problem.
They’re built to generate natural-sounding language, not truth. So, while they may give you a SQL query or dashboard summary in seconds, that doesn’t mean it’s accurate. In fact, many LLMs can hallucinate metrics, invent dimensions, or produce outputs that seem plausible but are completely wrong.
You wouldn’t hand over your revenue targets to someone who “sounds confident,” right? So why are so many teams doing that with AI?
Here's the challenge. Even experienced data professionals can be fooled. The more fluent the output, the easier it is to miss the flaws underneath.
This isn’t just theory, Castor warns that “most AI-generated queries will work, but they won’t always be right.” That tiny gap between function and accuracy is where risk lives.
If you’re leading a data-driven team or making decisions based on LLM-generated outputs, these are the real risks you need to watch out for.
LLMs can fabricate filters, columns, and logic that don’t exist. In the moment, you might not notice but if those false insights inform a slide for board meeting or product decision, the damage is done.

Here is an example where an image was provided to ChatGPT and asked to point out the three differences between the two pictures as illustrated below:

Here is the output from ChatGPT:
Here are the 3 differences between the two images:
Let me know if you want these highlighted visually!
When asked to highlight the differences, ChatGPT produced the following image:

As you can see, ChatGPT skewed the information and exaggerated the differences in the image. Only one (the shirt stripe) out of the three was correct, while it missed the differences with the sock, the hair, and it even changed the author in the copyright!
AI doesn’t know your KPIs, fiscal calendars, or market pressures. Business context still requires a human lens to interpret properly. Without that, you risk misreading what the data is trying to say.
AI doesn’t give sources or confidence scores. You often can’t tell where a number came from. Secoda notes that teams still need to double-check model outputs before trusting them in critical workflows.
One of the great things about LLMs is how accessible they are. But that also means anyone can generate analytics even if they don’t understand the data underneath. This creates a gap between surface-level insight and actual understanding.
Over-relying on LLMs can create more cleanup work than if a skilled analyst had just done it from the start. Over-relying on automation often creates cleanup work that slows teams down. As we noted in Modern Data Stack Acceleration, true speed comes from workflows designed with governance and best practices.
If you’ve ever skimmed an LLM-generated response and thought, “That’s not quite right,” you already know the value of human oversight.
AI is fast, but it doesn’t understand what matters to your stakeholders. It can’t distinguish between a seasonal dip and a business-critical loss. And it won’t ask follow-up questions when something looks off.
Think of LLMs like smart interns. They can help you move faster, but they still need supervision. Your team’s expertise, your mental model of how data maps to outcomes, is irreplaceable. Tools like Datacoves embed governance throughout the data journey to ensure humans stay in the loop. Or as Scott Schlesinger says, “AI is the accelerator, not the driver.” It’s a reminder that human hands still need to stay on the wheel to ensure we’re heading in the right direction.
Datacoves helps teams enforce best practices around documentation, version control, and human-in-the-loop development. By giving analysts structure and control, Datacoves makes it easier to integrate AI tools without losing trust or accountability. Here are some examples where Datacoves’ integrated GenAI can boost productivity while keeping you in control.
Want to keep the speed of LLMs and the trust of your team? Here’s how to make that balance work.
AI can enhance analytics but should not be used blindly. LLMs bring speed, scale, and support, but without human oversight they can also introduce costly errors that undermine trust in decision-making.
Human judgment remains essential. It provides the reliability, context, and accountability that AI alone cannot deliver. Confidence doesn’t equal correctness, and sounding right isn’t the same as being right.
The best results come from collaboration between humans and AI. Use LLMs as powerful partners, not replacements. How is your team approaching this balance? Explore how platforms like Datacoves can help you create workflows that keep humans in the loop.

It is clear that Snowflake is positioning itself as an all-in-one platform—from data ingestion, to transformation, to AI. The announcements covered a wide range of topics, with AI mentioned over 60 times during the 2-hour keynote. While time will tell how much value organizations get from these features, one thing remains clear: a solid foundation and strong governance are essential to deliver on the promise of AI.
Conversational AI via natural language at ai.snowflake.com, powered by Anthropic/OpenAI LLMs and Cortex Agents, unifying insights across structured and unstructured data. Access is available through your account representative.
Datacoves Take: Companies with strong governance—including proper data modeling, clear documentation, and high data quality—will benefit most from this feature. AI cannot solve foundational issues, and organizations that skip governance will struggle to realize its full potential.
An AI companion for automating ML workflows—covering data prep, feature engineering, model training, and more.
Datacoves Take: This could be a valuable assistant for data scientists, augmenting rather than replacing their skills. As always, we'll be better able to assess its value once it's generally available.
Enables multimodal AI processing (like images, documents) within SQL syntax, plus enhanced Document AI and Cortex Search.
Datacoves Take: The potential here is exciting, especially for teams working with unstructured data. But given historical challenges with Document AI, we’ll be watching closely to see how this performs in real-world use cases.
No-code monitoring tools for generative AI apps, supporting LLMs from OpenAI (via Azure), Anthropic, Meta, Mistral, and others.
Datacoves Take: Observability and security are critical for LLM-based apps. We’re concerned that the current rush to AI could lead to technical debt and security risks. Organizations must establish monitoring and mitigation strategies now, before issues arise 12–18 months down the line.
Managed, extensible multimodal data ingestion service built on Apache NiFi with hundreds of connectors, simplifying ETL and change-data capture.
Datacoves Take: While this simplifies ingestion, GUI tools often hinder CI/CD and code reviews. We prefer code-first tools like DLT that align with modern software development practices. Note: Openflow requires additional AWS setup beyond Snowflake configuration.
Native dbt development, execution, monitoring with Git integration and AI-assisted code in Snowsight Workspaces.
Datacoves Take: While this makes dbt more accessible for newcomers, it’s not a full replacement for the flexibility and power of VS Code. Our customers rely on VS Code not just for dbt, but also for Python ingestion development, managing security as code, orchestration pipelines, and more. Datacoves provides an integrated environment that supports all of this—and more. See this walkthrough for details: https://www.youtube.com/watch?v=w7C7OkmYPFs
Read/write Iceberg tables via Open Catalog, dynamic pipelines, VARIANT support, and Merge-on-Read functionality.
Datacoves Take: Interoperability is key. Many of our customers use both Snowflake and Databricks, and Iceberg helps reduce vendor lock-in. Snowflake’s support for Iceberg with advanced features like VARIANT is a big step forward for the ecosystem.
Custom Git URLs, Terraform provider now GA, and Python 3.9 support in Snowflake Notebooks.
Datacoves Take: Python 3.9 is a good start, but we’d like to see support for newer versions. With PyPi integration, teams must carefully vet packages to manage security risks. Datacoves offers guardrails to help organizations scale Python workflows safely.
Define business metrics inside Snowflake for consistent, AI-friendly semantic modeling.
Datacoves Take: A semantic layer is only as good as the underlying data. Without solid governance, it becomes another failure point. Datacoves helps teams implement the foundations—testing, deployment, ownership—that make semantic layers effective.
Hardware and performance upgrades delivering ~2.1× faster analytics for updates, deletes, merges, and table scans.
Datacoves Take: Performance improvements are always welcome, especially when easy to adopt. Still, test carefully—these upgrades can increase costs, and in some cases existing warehouses may still be the better fit.
Free, automated migration of legacy data warehouses, BI systems, and ETL pipelines with code conversion and validation.
Datacoves Take: These tools are intriguing, but migrating platforms is a chance to rethink your approach—not just lift and shift legacy baggage. Datacoves helps organizations modernize with intention.
Enrich native apps with real-time content from publishers like USA TODAY, AP, Stack Overflow, and CB Insights.
Datacoves Take: Powerful in theory, but only effective if your core data is clean. Before enrichment, organizations must resolve entities and ensure quality.
Internal/external sharing of AI-ready datasets and models, with natural language access across providers.
Datacoves Take: Snowflake’s sharing capabilities are strong, but we see many organizations underutilizing them. Effective sharing starts with trust in the data—and that requires governance and clarity.
Developers can build and monetize Snowflake-native, agent-driven apps using Cortex APIs.
Datacoves Take: Snowflake has long promoted its app marketplace, but adoption has been limited. We’ll be watching to see if the agentic model drives broader use.
Versioning, permissions, app observability, and compliance badging enhancements.
Datacoves Take: We’re glad to see Snowflake adopting more software engineering best practices—versioning, observability, and security are all essential for scale.
Auto-scaling warehouses with intelligent routing for performance optimization without cost increases.
Datacoves Take: This feels like a move toward BigQuery’s simplicity model. We’ll wait to see how it performs at scale. As always, test before relying on this in production.
Enhanced governance across Iceberg tables, relational DBs, dashboards, with natural-language metadata assistance.
Datacoves Take: Governance is core to successful data strategy. While Horizon continues to improve, many teams already use mature catalogs. Datacoves focuses on integrating metadata, ownership, and lineage across tools—not locking you into one ecosystem.
Trust Center updates, new MFA methods, password protections, and account-level security improvements.
Datacoves Take: The move to enforce MFA and support for Passkeys is a great step. Snowflake is making it easier to stay secure—now organizations must implement these features effectively.
Upgrades to Snowflake Trail, telemetry for Openflow, and debug/monitor tools for Snowpark containers and GenAI agents/apps.
Datacoves Take: Observability is critical. Many of our customers build their own monitoring to manage costs and data issues. With these improvements, Snowflake is catching up—and Datacoves complements this with pipeline-level observability, including Airflow and dbt.
Read the full post from Snowflake here:
https://www.snowflake.com/en/blog/announcements-snowflake-summit-2025/
