


Legacy systems and procedures can often become barriers to innovation and efficiency in the fast-paced world of data management and analytics. Companies that do not evolve to a more modern data stack may find themselves struggling to keep up with the demands of the modern business landscape. In this article we will take a deeper look into J&J's journey of data stack transformation using Datacoves and dbt.
Where J&J's Data Team Started
J&J began an their data initiative named “Ensemble” in efforts to unlock the power of data and insights, so their healthcare professionals can make the best informed decisions.
These efforts realized Ensemble 1.0, initiated in 2018, which aimed to consolidate data sources and projects. However, with the fast-paced business expectations, Ensemble 1.0 encountered challenges, leading to its recognition as a legacy architecture.
Pain Points of Ensemble 1.0
- Low performance: The system often lagged, leading to increased processing times and inefficiencies.
- Absence of DataOps processes: There was a lack of streamlined operations for data, causing delays and inconsistencies.
- Limited flexibility in computing infrastructure: The infrastructure was rigid, making it difficult to scale or adapt to changing needs.
- Challenges with data accessibility: Users faced hurdles in accessing the data they needed, impeding their work.
- Governance issues: The system lacked proper data governance mechanisms, leading to concerns about data quality and integrity.
- Rigid self-service tools: The tools available for users were not intuitive, making it challenging for them to execute tasks without technical support.
- Complications in managing type 2/3 data: Handling this kind of data became cumbersome due to the need for parallel environments, complicating data management and operations.

Facing these challenges, J&J recognized the need for a comprehensive overhaul of their data infrastructure. Determined to be methodical in their approach, they outlined a set of clear objectives to guide their transformation journey.
Objectives of Ensemble 2.0
Recognizing these issues, Ensemble 2.0 was birthed with the intent to rectify the pain points. The key objectives included improved agility, federated data modeling, increased efficiency, and enhanced data quality.
Each pain point was mapped to an objective that the new system had to provide.
- Improved Agility: One of the primary goals was to enhance the system's responsiveness and adaptability to changing business needs.
- Federated Data Modeling: This approach aimed to provide a unified view of data across the organization, integrating different data sources without compromising on individual data silos.
- Increased Efficiency: By streamlining processes and eliminating redundancies, the goal was to boost the overall performance of the system.
- Enhanced Data Quality: With an emphasis on accuracy and consistency, measures were put in place to ensure the highest standards of data quality.
- Simplified Data Sharing: Making data accessible and easy to share was paramount, fostering collaboration across teams.
- Ensured Data Security: Keeping data secure was a top priority, with robust security protocols in place.
- User-Friendly Data: A significant objective was to present data in a way that was intuitive and easily comprehensible to users.
[case-cta]
J&J’s Modern Data Stack: Snowflake + dbt + Datacoves
The revamped architecture, tools, and accelerators were the pillars that made these objectives attainable. Ensemble 2.0 witnessed a 30% reduction in development effort, an impressive 98% data flows reliability, and a 70% slash in data flow refresh time.
Key Technologies Used
- Snowflake: With features like zero-copy cloning, decoupled compute and storage, and dynamic data masking, it was a game-changer.
- Datacoves: This DataOps framework accelerator streamlined processes. (We can add more here)
- dbt: Its SQL-based ecosystem, automated lineage, and documentation facilitated governance and simplified code reviews.

Realizing the potential of these technologies, J&J collaborated with Datacoves and SDG Group, transitioning from a 7-year-old BI setup to a state-of-the-art platform.
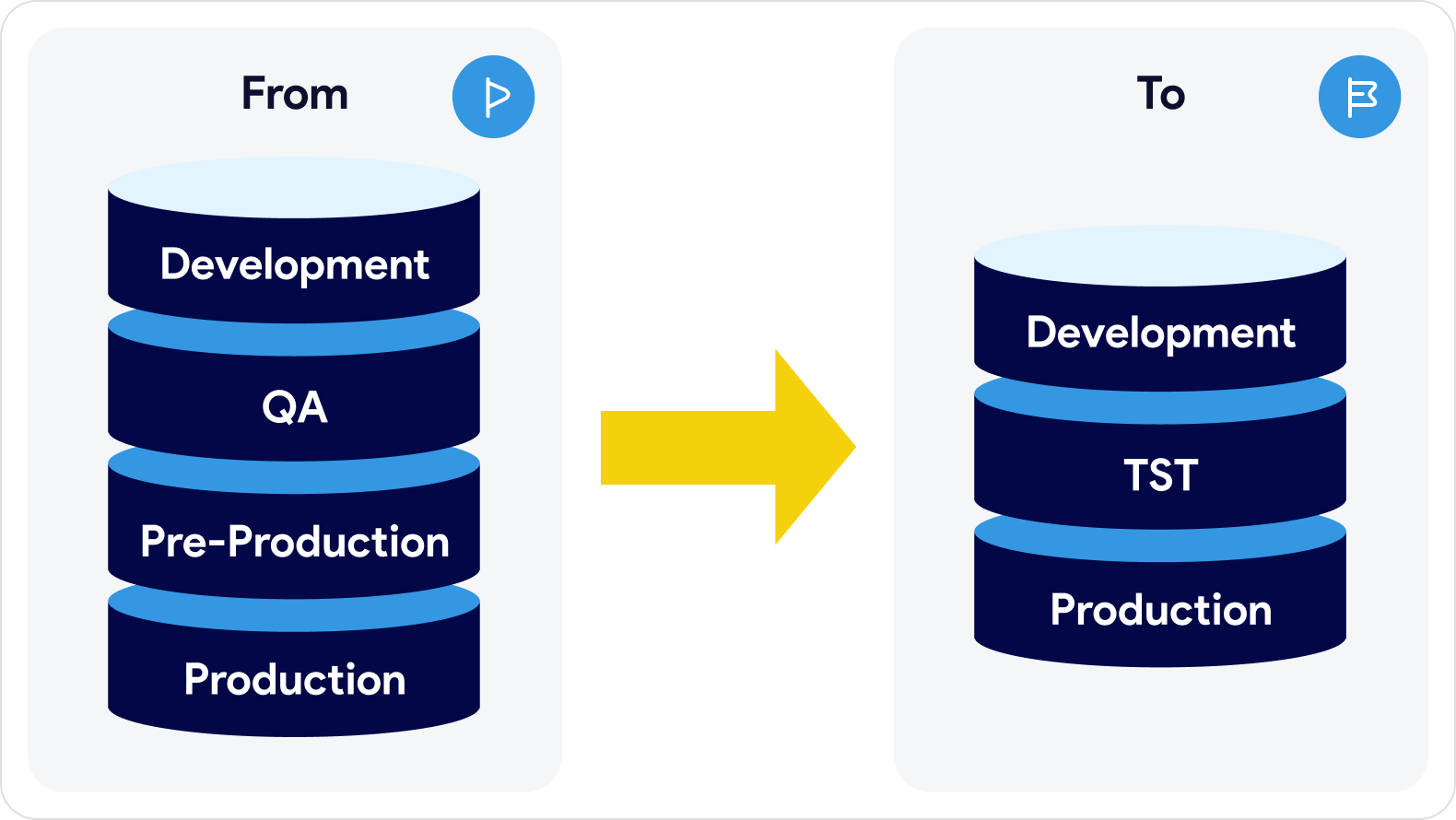
Comparison of the Old and New Data Architecture
One of the remarkable transformations was the shift from managing four environments to just three: Development, TST, and Production. Using Snowflake allowed for development against actual business data, enhancing efficiency and reducing complexities.
Orchestration
- Complex DAGs: Managing intricate DAGs has always been challenging. The solution? A significant move towards simplification. Orchestration became more straightforward by separating EL Pipelines and T Pipelines. Sources were treated as isolated data pipelines, simplifying additions and modifications.
- Isolated Data Pipelines: Sources can now be treated as independent pipelines. Adding a new source? It's as straightforward as a single line of code.
- Transformation DAG: Simplified with commands like "dbt build", allowing teams to easily subscribe to a schedule. The workflow involves local development and testing, and once ready, teams can transition to production with a simple schedule subscription. The result? Higher data quality and streamlined development.
Security
- Source Code Centric: Security in Ensemble 2.0 revolves around source code. This ensures systematic management, with capabilities for detailed reporting and configuration fetching.
- Row Access & Data Masking: Product teams are now empowered with dynamic data masking and row access policies, all while maintaining rigorous governance. With dbt automation, configuring data masking for a column automatically updates it in a YML file.
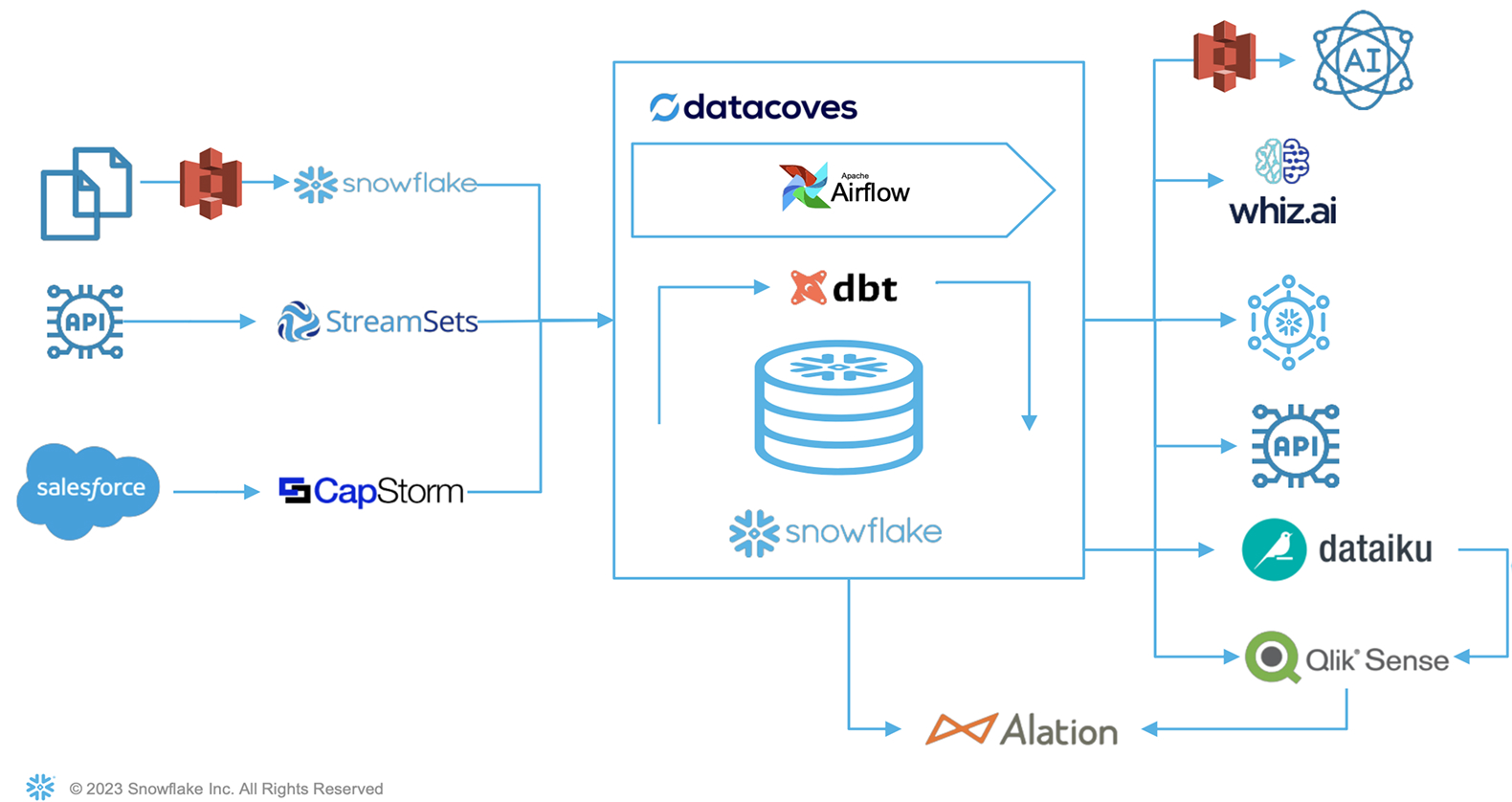
J&J’s End-To-End Data Architecture: ELT and Consumption
EL Segment:
- Files: Transition from s3 to Snowflake.
- Database API: Managed using StreamSets.
- Salesforce: CapStorm synchronizes data, accommodating formula fields.
T Segment:
- Datacoves: Enhances flexibility and efficiency.
- Tech Integration: Seamless collaboration between Airflow, dbt, and Snowflake.
Consumption:
- Diverse Tools: From Qlik Sense, Dataiku, to Whiz.ai, there's a tool for every need.
- Snowflake: All transformations reside here, making it the undisputed source of truth. Regardless of the tool, Snowflake is the go-to for data retrieval, ensuring consistency and reliability.
How J&J Structure their Snowflake Layers Using Datacoves
Datacoves gets its name from its innovative structure and naming conventions for the Data Warehouse: Inlets, Bays and Coves. J&J made use of Snowflake's architecture which is designed to provide users with structured access to data, ensuring clarity in roles, stages, and data access permissions.
Here's a breakdown:
Raw Layer:
- Description: This layer maintains a one-to-one relationship with the source. It's the unaltered representation of the incoming data, serving as the base foundation for all subsequent layers.
- Access: Due to its raw nature, access might be restricted to specific teams or roles to prevent misuse of unprocessed data.
Inlets:
- Description: Like the Raw layer, the Inlet layer retains a one-to-one relationship with the source. However, it undergoes minimal cleansing. This includes converting to appropriate data types, standardizing time zones, renaming ambiguous columns for clarity, and implementing security measures such as data masking and row access limitations. It's organized similarly to the Raw layer but uses the "inlet_" prefix for differentiation.
- Access: Given its enhanced clarity and security measures, this layer might be accessible to a broader audience than the Raw layer, but still with certain restrictions.
Bays:
- Description: The Bay layer is the first to deviate from source-centric organization. Instead, it categorizes data based on what the data represents, rather than its origin. This results in reusable and interconnected data sets, managed by dedicated teams responsible for data quality and integrity. For instance, data domains might be divided into categories like "Account" or "Interaction".
- Access: With its organized structure, this layer is likely accessible to teams or roles that need a more abstracted view of the data, focusing on its type and content rather than its origin.
Coves:
- Description: The Cove layer is designed with end-users in mind. It's where data products are utilized to produce specific analytical results. Coves are user-centric zones tailored for in-depth analyses, ad-hoc querying, and prototyping of new data solutions. Typically, Coves are structured in models to streamline the analysis process.
- Access: Power users, analysts, and those involved in data-driven decision-making are the primary consumers of this layer. They leverage the Cove layer's structured and user-friendly format for their analytic needs.
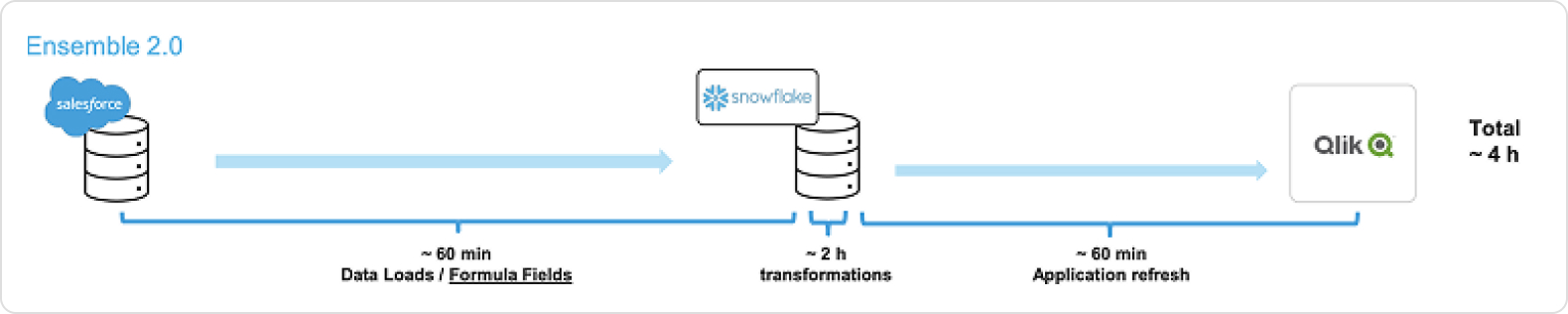
Results
When comparing Ensemble 1.0 to Ensemble 2.0, significant improvements are evident as seen below in the Salesforce Pipeline comparison.

Previously, with Ensemble 1.0, the pipeline would take an extensive 12 hours to process. However, with the introduction of Ensemble 2.0, the same task is now accomplished in just 4 hours. This marks a substantial 66% reduction in processing time, greatly enhancing data availability and operational efficiency.
Conclusion
J&J's transition from Ensemble 1.0 to Ensemble 2.0 is a testament to the importance of continuous innovation in the data realm. By collaborating with experts, adopting cutting-edge technologies, and addressing pain points head-on, J&J has set a benchmark for data management and analytics. While J&J adopted new tools, they internalized the reality that adopting these innovative technologies requires a fresh mindset. The goal isn't just to use new tools but to redefine processes, ensuring modern and efficient results. Because of that the were able to achieve new heights with their data.
Prefer a video?
Watch the Snowflake Summit presentation





