
Snowflake is one of the best data warehouses available. But buying it doesn't give you a data platform. A working platform also requires an engineering environment where your team can develop consistently, orchestration to run and monitor pipelines, CI/CD to enforce quality before anything reaches production, and ways of working that make the whole thing maintainable as your team grows. Most Snowflake implementations deliver the warehouse. The platform layer around it, and the practices underneath it, are usually left for your team to figure out after the SI rolls off. That gap is where most implementations quietly fail.
Buying Snowflake gives you a warehouse. A working data platform requires an engineering environment, orchestration, CI/CD, and ways of working that don't come with the warehouse contract.
What a Data Platform Actually Requires
A data warehouse stores and processes data. That's what it was designed to do, and Snowflake does it exceptionally well.
A data platform does something different. It's the environment where your team develops, tests, deploys, and monitors data products. It includes the tools, the conventions, and the ways of working that determine whether your data is trustworthy, usable, and maintainable at scale.
The distinction matters because most implementations are scoped around the warehouse. The platform layer gets treated as something that will sort itself out later. It rarely does.
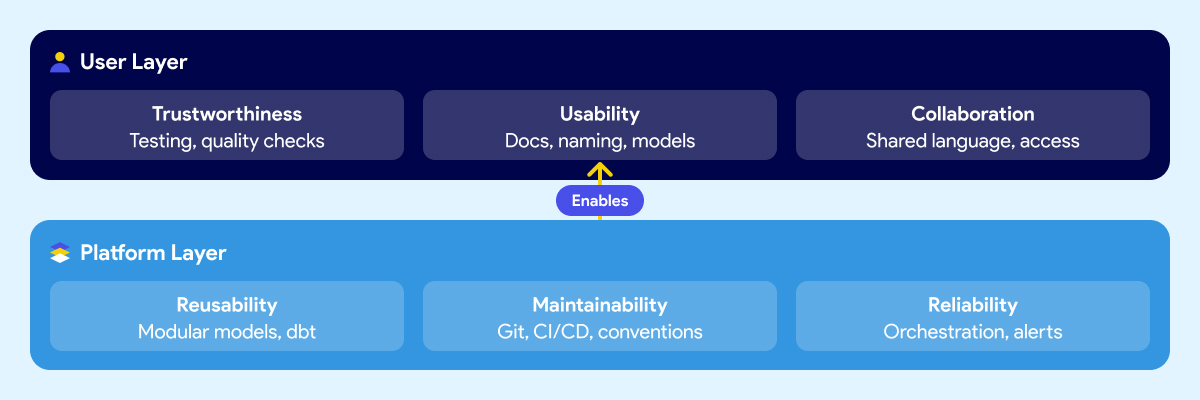
Think about it in two layers.
The first is what your users experience: whether they trust the data, whether they can find and understand it, and whether business and technical teams can communicate around it. This includes trustworthiness, usability, collaboration.
The second is what makes those outcomes possible at the platform level: whether data products can be reused without rebuilding from scratch, whether the system is maintainable when people leave or the team grows, and whether pipelines are reliable enough that failures get caught early instead of surfacing in a meeting. These include reusability, maintainability, reliability.
Most Snowflake implementations deliver storage and compute. The six outcomes above are what your business expected the platform to produce. They require deliberate work that sits outside the warehouse contract.
Why Snowflake Alone Doesn't Get You There
Snowflake is excellent at what it does. Fast queries, elastic scaling, clean separation of storage and compute, a strong security model. If your previous warehouse was on-prem or running on aging infrastructure, the difference is real and immediate.
The problem isn't Snowflake. The expectation that the warehouse is the platform is.
Snowflake handles storage, compute, and access control. It doesn't give your team a development environment. It doesn't orchestrate your pipelines or tell you when one failed and why. It doesn't enforce naming conventions, testing standards, or deployment rules. It doesn't document your data models or make them understandable to a business analyst who didn't build them. It doesn't define how your team reviews code, manages branches, or promotes changes from development to production.
Those things aren't gaps in Snowflake's product. They were never Snowflake's job.
But when leaders evaluate a warehouse and sign a contract, the scope of what they're buying rarely gets articulated clearly. The demos show fast queries and a clean UI. The pitch covers performance benchmarks and cost savings versus the legacy system. Nobody walks through the engineering environment your team will need to build on top of it, because that's not what the vendor is selling.
So teams buy a best-in-class warehouse and then spend the next six months discovering everything else they need. Some figure it out. Some don't. And most take a long time to get there.
How Leaders End Up With a Warehouse and Not Much Else
There are three common paths to a Snowflake implementation. Each one has real strengths. Each one has a predictable blind spot that leads to the same outcome: a warehouse that works, but fails to deliver the expected results.
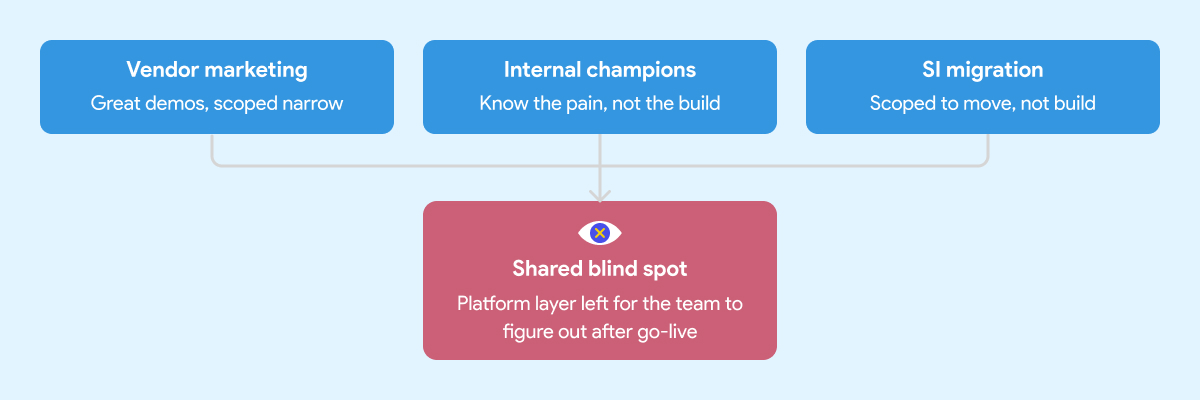
The Vendor Marketing Problem
Snowflake's marketing is good. That's not a criticism, it's an observation. The positioning is clear, the case studies are compelling, and the product genuinely delivers on the core promise.
What the marketing doesn't cover is everything that sits around the warehouse. That's not Snowflake's job. Their job is to sell Snowflake. The implicit message, though, is that the hard problem is the warehouse. Once that's solved, everything else follows.
It doesn't. Leaders who build their implementation strategy around the vendor pitch tend to underscope the project from the start. The warehouse gets stood up on time and on budget. The data engineering environment, the orchestration layer, the governance foundation, those get deferred. Sometimes indefinitely.
The Internal Enthusiasm Problem
Every organization has at least one person who comes back from a Snowflake conference ready to modernize everything. That enthusiasm is valuable. It's also frequently mis-channeled.
Internal champions know the business problem well. They've seen the pain. What they often don't have is deep experience building and operating a production data platform from scratch. They know what good outcomes look like. They haven't necessarily seen what a well-built foundation looks like underneath those outcomes.
So the implementation gets shaped around what they know: the warehouse, the transformation tool, maybe a basic orchestration setup. The harder questions around developer environments, CI/CD, testing standards, secrets management, and deployment conventions don't get asked because nobody in the room has been burned by skipping them before.
The SI Migration Problem
A migration is not a platform implementation. The SI's job is to get your data into Snowflake. Whether the environment your team inherits is maintainable and built on sound engineering practices is usually outside the engagement scope.
System integrators are good at migrations. Moving data from point A to point B, replicating existing logic in a new tool, hitting a go-live date. That's what most of them are scoped and incentivized to deliver.
It's not that SIs cut corners. It's that "build a production-grade data engineering platform with sustainable ways of working" wasn't in the statement of work.
What gets handed off is a warehouse with some tables, some transformation logic, and documentation that will be out of date within a month. The team that inherits it then spends the next year figuring out how to operate it at scale.
If you're evaluating implementation partners, here's what to look for before you sign.
What Gets Skipped When You Rush the Foundation
When the implementation is scoped around the warehouse and the migration, a predictable set of things gets deferred. Not because anyone decided they didn't matter, but because they weren't on the project plan.
Here's what that looks like in practice six to twelve months later.
Snowflake costs start climbing. Without well-structured data models, query optimization standards, and sensible clustering strategies, warehouses burn credits fast. Teams that skipped the engineering foundation often spend the first year optimizing for cost rather than delivering new capabilities. The savings from migrating off the legacy system quietly get absorbed by an inefficient Snowflake setup.
Business users don't trust the data. When there are no testing standards, no documentation conventions, and no consistent naming across models, analysts spend more time validating numbers than using them. The platform gets a reputation for being unreliable. People go back to Excel because nobody built the layer that makes data understandable and trustworthy.
The team can't move fast. Without CI/CD pipelines, code reviews, and deployment guardrails, every change is a risk. Engineers slow down because they're afraid of breaking something. Onboarding a new team member takes weeks because the knowledge lives in people's heads, not in the system.
Pipelines break in ways nobody sees coming. Without orchestration that handles dependencies, retries, and failure alerts, pipeline failures surface downstream. A business user notices the numbers are wrong before the data team does. That erodes trust fast and is hard to rebuild.
The foundation debt compounds. Every week that passes without fixing the underlying structure makes it harder to fix. New models get built on top of a shaky base. Refactoring becomes expensive. The team that was supposed to be delivering new data products spends its time maintaining what already exists.
This is the real cost of the quick win approach. Six months of fast progress followed by years of slow, careful, expensive work to undo the shortcuts.
We've documented what that looks like in practice here.
Tools and Ways of Working Have to Go Together
Most implementation conversations focus on the tool stack. Which warehouse, which transformation framework, which orchestrator. Those are real decisions and they matter.
But the teams that deliver reliable data products consistently aren't just using the right tools. They're using them the same way across every engineer on the team.
That's the ways of working problem. And it's the part nobody puts in the project plan.
A team with Snowflake and dbt but no agreed branching strategy, no code review process, no testing standards, and no deployment conventions is still fragile. One engineer builds models one way. Another builds them differently. A third inherits both and must figure out which approach is "correct" before they can extend anything. The system never enforced a consistent approach.
The same applies to orchestration. Airflow is powerful. An Airflow environment where every engineer writes DAGs differently, secrets are managed inconsistently, and there's no standard for how pipeline failures get handled is not an asset. It's a maintenance problem waiting to get worse.
Good data engineering is a thought-out combination of tools and conventions that work together. The conventions are what make the tools scale beyond the person who set them up.
This is why the two-layer framework matters in practice. Trustworthiness, usability, and collaboration aren't outcomes you get from buying the right tools. They're outcomes you get when the platform layer underneath, the reusability, maintainability, and reliability, is built deliberately. With both the right tooling and the right ways of working enforced by the system itself, not by people remembering to follow a document.
The teams that figure this out usually do it the hard way. They run into the problems first, then back into the conventions that would have prevented them. That process can take years and a lot of frustration. Getting the ways of working right from the start compresses that timeline significantly.
Doing It Right Upfront Is the Fast Path
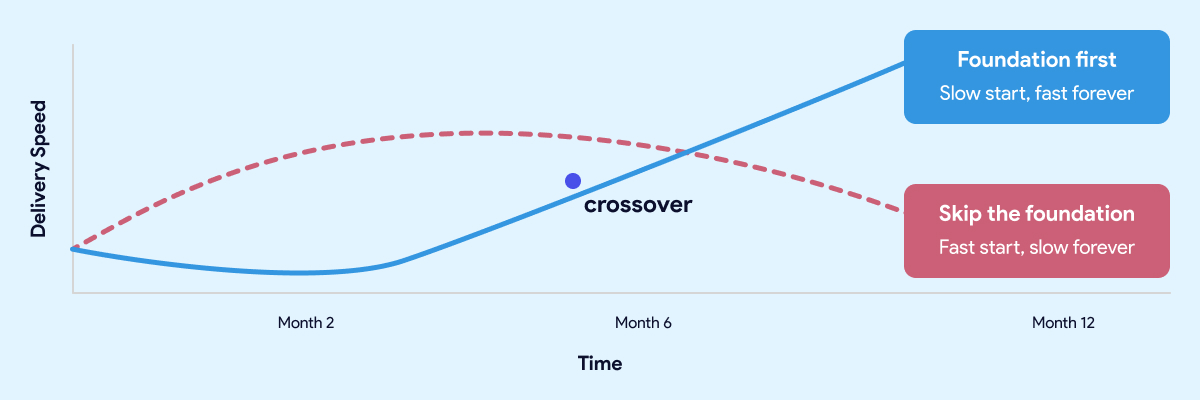
The teams that move fastest twelve months in are almost always the ones who slowed down at the start.
The most common objection to investing in the foundation is time. Leaders have stakeholders who want results. Boards want dashboards. The business wants answers. Spending eight weeks building an engineering environment and establishing conventions feels like the opposite of moving fast.
That instinct is understandable. It's also wrong.
The teams that move fastest twelve months in are almost always the ones who slowed down at the start. Not forever. For a few weeks. Long enough to get the development environment right, establish the conventions, wire up CI/CD, and make sure the orchestration layer is solid before anyone builds on top of it.
The teams that skipped that work aren't moving fast. They're managing debt. Every new model gets built carefully because nobody is sure what it might break. Every pipeline change requires manual testing because the automated checks were never put in place. Every new hire takes weeks to get productive because the knowledge lives in people, not in the system.
A quick start that skips the foundation isn't free. It's a loan at a high interest rate. The payments start small and get larger every month.
The same logic applies here. A quick start that skips the foundation isn't free. It's a loan at a high interest rate. The payments start small and get larger every month.
Getting the foundation right upfront doesn't mean months of invisible infrastructure work before anyone sees results. Done well, it takes weeks, not quarters. And what you get on the other side is a team that ships twice a week without being afraid of what they might break, data that business users trust, and a platform that gets easier to extend as it grows rather than harder.
That's not slow. That's the fast path.
Before you sign with anyone, there's a specific set of questions worth asking your SI or platform vendor. We covered them in detail here.
How Datacoves Compresses the Foundation Work
Most teams face a choice at the start of a data platform project. Build the foundation properly and accept that it takes time. Or skip it and move fast now, knowing you'll pay for it later.
Datacoves is built around the idea that you shouldn't have to make that trade-off.
It's an enterprise data engineering platform that runs inside your private cloud and comes with the foundation pre-built. Managed dbt and Airflow, a VS Code development environment your engineers can open on day one, CI/CD pipelines that enforce quality before anything reaches production, and an architecture built on best practices that your team inherits rather than invents.
The conventions, the guardrails, the deployment workflows, the secrets management, the testing framework. None of that gets figured out after the fact. It's already there.
That's what compresses the timeline. Not shortcuts. Not skipping steps. The foundation work is done, and your team starts from a position that most organizations spend a year trying to reach on their own.
The result is a team that ships consistently from early on, data that business users trust because quality is enforced by the system rather than by people remembering to check, and a platform that gets easier to extend as it grows.
Guitar Center onboarded in days. Johnson and Johnson described it as a framework accelerator. Those outcomes aren't the result of moving fast and fixing problems later. They're the result of starting with a foundation that didn't need to be fixed.
Snowflake is a great warehouse. The teams that get the most out of it aren't the ones who bought it and figured out the rest later. They're the ones who treated the platform layer as part of the project from the start. The tool doesn't build the platform. That part is still your decision to make.
FAQ:
Does building a proper data foundation slow you down?
Short term, slightly. Long term, the opposite. Teams that invest a few weeks getting the foundation right ship consistently for years afterward. Teams that skip it move fast for six months and then spend years managing the debt. The foundation isn't the slow path. Skipping it is.
How long does it take to set up a proper data platform foundation?
Done well, the foundation work takes weeks, not months. A managed platform like Datacoves compresses it further by providing the engineering environment, CI/CD, and orchestration pre-configured. The goal is to be writing and deploying production code within the first few weeks, not spending months on infrastructure setup before anything gets delivered.
Is Snowflake good for small data teams?
Snowflake works well for teams of any size. The warehouse scales up or down cleanly. What doesn't scale automatically is the platform layer around it. Small teams have more to gain from getting the foundation right early, because they have fewer people to absorb the cost of a messy setup. A two-person team drowning in pipeline fires has no one left to build new things.
What does a Snowflake implementation include?
A Snowflake implementation typically covers deploying the warehouse, migrating existing data, and setting up basic access controls. What it usually doesn't include is the engineering environment your team needs to develop consistently, orchestration to run and monitor pipelines, CI/CD to enforce quality, or the conventions that make the platform maintainable over time. Those require deliberate work that sits outside most warehouse contracts.
What questions should I ask a Snowflake implementation partner before signing?
Before signing with any SI or platform vendor, ask: Can you show me a client whose team ships independently without your firm in the critical path? What open-source tools does your approach use and how are upgrades handled? Who on our team will own the models and deployment process after you roll off? How is data quality enforced, and where in the pipeline does it happen? The answers will tell you whether they're building you a platform your team can operate or a system only they can maintain. For a full breakdown, see our data migration partner guide.
What should a data platform include beyond the warehouse?
A working data platform requires a development environment where engineers can work consistently, an orchestration layer to run and monitor pipelines, CI/CD pipelines that enforce quality before anything reaches production, testing and documentation standards, secrets management, and deployment conventions that the whole team follows. The warehouse handles storage and compute. Everything else is the platform layer.
What's the difference between a data migration and a data platform implementation?
A data migration moves data from one system to another. A data platform implementation builds the environment your team uses to develop, test, deploy, and monitor data products going forward. Most SI engagements are scoped around the migration. The platform layer is a different project, and it's often the one nobody planned for.
Why do business users still not trust the data after a Snowflake migration?
Data trust is a product of testing standards, documentation conventions, and consistent naming across models. None of those come with the warehouse. When the implementation skips the engineering foundation, analysts spend more time validating numbers than using them. The platform gets a reputation for being unreliable regardless of how fast the underlying queries run.
Why is my Snowflake bill higher than expected?
Snowflake costs scale with compute usage. Without well-structured data models, query optimization standards, and sensible clustering strategies, credits burn fast. A single unoptimized full table scan on a large table can consume more credits in one run than a well-structured incremental model consumes in a week. Teams that skip the engineering foundation often spend their first year optimizing for cost rather than delivering new capabilities. The savings from migrating off the legacy system quietly get absorbed by an inefficient setup.

-Photoroom.jpg)




