
A Data Operating Model is the set of decisions that define how a company delivers value from data. It covers ownership, team topology, workflows, standards, SLAs, governance, and the platform layer underneath all of it. The tools sit inside the operating model, not above it.
Most enterprises invest heavily in the tool layer and leave the operating model to emerge on its own during the build. That's the pattern behind nearly every frustrated data leader I talk to: the warehouse works, the transformation tool runs, the SI delivered on the statement of work, and the business still isn't getting what it expected. The absence of a defined operating model before the build started is the usual cause.
This article explains what a Data Operating Model is, what it includes, why foundational gaps compound instead of resolving themselves, and what to do if you're already mid-build and seeing the symptoms.
What a Data Operating Model Actually Is
A Data Operating Model is the blueprint for how your organization turns data into business value. It defines who owns what, how work moves through the system, what standards apply, what "good" looks like, and what the platform underneath must enforce. It sits above the tools and above the architecture. The tools exist to serve the operating model, not the other way around.
Most executives have never been shown a Data Operating Model in concrete terms, so the concept stays abstract. It shouldn't. An operating model is a finite set of decisions that can be written down, agreed on, and enforced. The reason most enterprises don't have one isn't that it's hard to build. It's that it wasn’t scoped and nobody owned the outcome.

The components of a Data Operating Model
A mature Data Operating Model answers seven questions: who owns what, how teams are structured, how work moves through the system, what standards apply, what SLAs the business expects, how governance is enforced, and what the platform layer underneath has to automate.
1. Ownership. Who owns each data product? Who owns each source? Who owns the model that joins them? When something breaks, who is accountable? When something needs to change, whose approval is required? Ownership isn't an org chart. It's the map of accountability across every data asset in the business.
2. Team topology. How do data teams align to the business? Do you have a central data team that services everyone, embedded analytics engineers inside each domain, or a hybrid mesh model? Which decisions are centralized and which are distributed? Team topology is the hardest component to change later, which is why it should be the first decision made.
3. Workflows. How does a request become a data product? How does a code change get from a developer's laptop to production? How do business users request a new metric? How do downstream teams get access to upstream data? These workflows should be documented, repeatable, and the same across every team. When every team invents their own, you get the naming drift, the cross-team gaps, and the late-surfacing issues that frustrate the business.
4. Standards. Naming conventions. Layering semantics. Documentation expectations. Testing requirements. Code review rules. Branching strategy. These are the things that make a platform legible to a new engineer on day one instead of week six. Standards that live only in a Confluence page are not standards. They're suggestions.
5. SLAs. What does the business expect for data freshness? How fast should a new KPI ship? How fast should a new source onboard? What's the acceptable recovery time when a pipeline fails? Without explicit SLAs, every request becomes a negotiation, and every failure becomes a fire drill.
6. Governance. Who can approve a production deployment? Who signs off on a new data product? How is access granted and reviewed? How are sensitive fields handled? Governance isn't a separate project to start next quarter. It's a dimension of every decision the operating model makes.
7. Platform layer. The infrastructure underneath all the above. Git workflows. CI/CD. Orchestration. Development environments. Secrets management. Deployment conventions. This layer exists to enforce the operating model automatically, so the team doesn't have to remember to follow the rules.
Every enterprise already has answers to these seven questions. The difference between a mature operating model and an immature one is whether those answers were decided deliberately, written down, and enforced by the system, or whether they emerged ad hoc as the build progressed.
How it differs from a data strategy, a platform, or an architecture
These terms get used interchangeably in executive conversations and they shouldn't be.
Why Most Enterprises Build Before the Operating Model Exists
If the operating model is this important, why don't enterprises start there? Because the path to a data platform almost never runs through the operating model. It runs through a tool purchase, a vendor pitch, or a business crisis that demands a fast answer. The operating model is the thing that gets skipped because nobody in the room knows to ask for it, and the people selling the build aren't incentivized to slow things down.
Three patterns show up repeatedly. Each one produces the same outcome: a platform that works technically but doesn't deliver on the business intent.
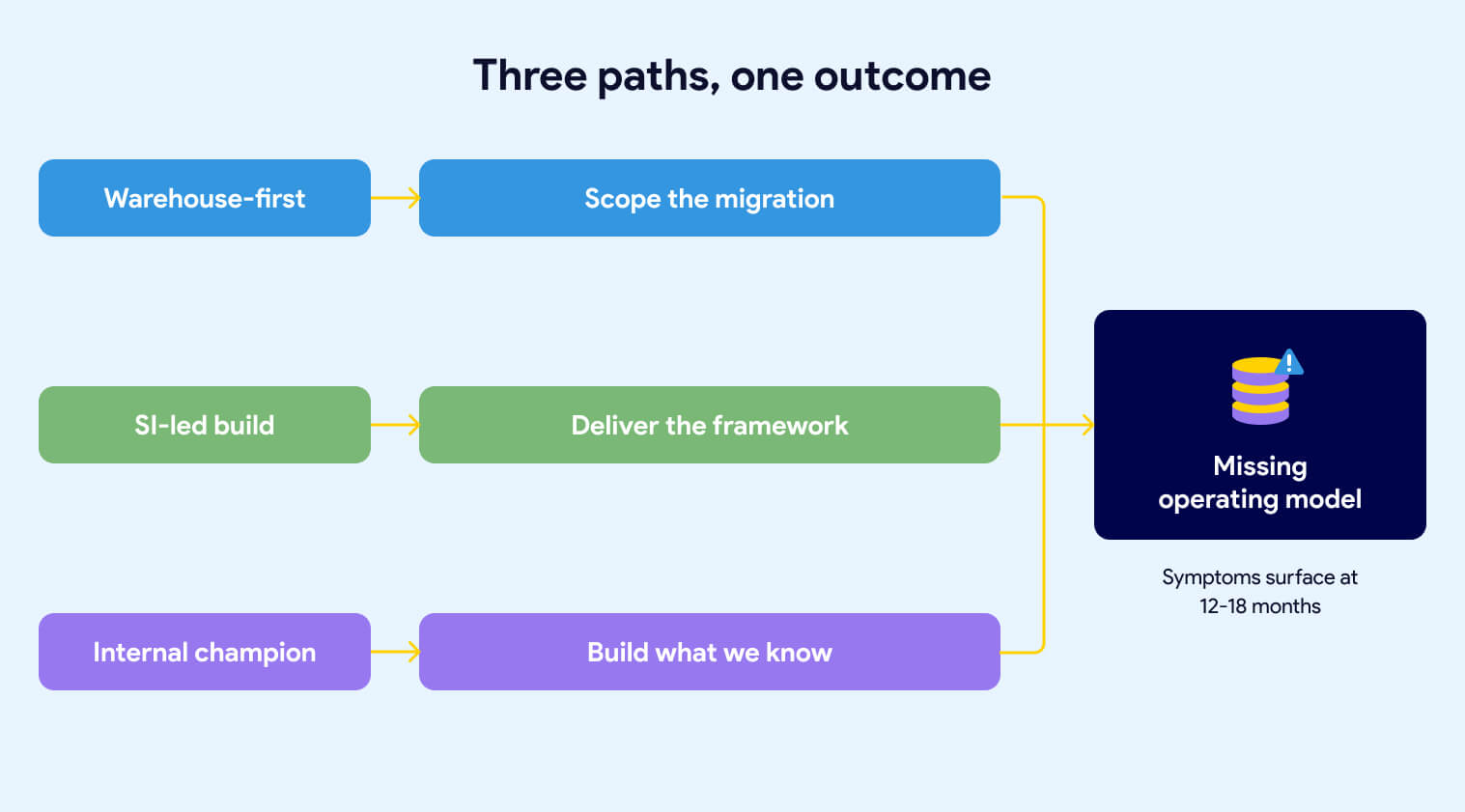
The warehouse-first trap
The first pattern starts with the warehouse. Leadership identifies that the current data infrastructure is too slow, too expensive, or too old. Someone comes back from a Snowflake conference. A decision gets made to modernize. The procurement process kicks off. Within a few months, Snowflake is signed and an implementation partner is scoped.
The scope is the migration. Move data from the legacy system into Snowflake. Replicate the existing transformation logic. Hit the go-live date. That's what the statement of work says, and that's what gets delivered.
What isn't in the scope: the operating model. Nobody wrote into the contract that the team would emerge from the engagement with agreed-upon naming conventions, a defined ownership map, documented SLAs, or a governance framework. The warehouse goes live on schedule. The operating model questions are still open eighteen months later, because nobody owned them and nobody was paid to answer them. We've covered what gets missed when the implementation is scoped around the warehouse in more depth.
The SI-led build
The second pattern hands the build to a systems integrator (SI) and watches them default to what they know. Every SI has a playbook. Some propose a custom metadata-driven framework. Some build their own Python-based orchestration layer. Some fall back on what they've shipped at ten other clients: heavy stored procedure logic, ELT patterns from a previous engagement, or a homegrown configuration system that mirrors whatever the team's senior architect built fifteen years ago.
The specific build doesn't matter as much as what the SI is focused on. They're focused on delivering the build. They're not focused on the business outcome the build is supposed to produce. We've seen this pattern documented in detail across enterprise implementations.
That distinction is the source of the problem.
When the engagement is scoped around the framework, the team's energy goes into framework decisions. How should the config tables be structured? What's the deployment mechanism? How do we handle environment promotion? Those are real questions, and they take real effort to answer. What doesn't get asked in the same meetings: Which business units are going to use this, and do they agree on naming? Who owns the data products once they're live? What SLAs is the business expecting? How will cross-team collaboration work when the second and third business units come online?
The framework ships. The first use cases deliver. The demo goes well. Then the symptoms start.
The internal team can read the framework but can't extend it without the SI. Framework changes require a new engagement. New capabilities that land in the open-source ecosystem, new Airflow features, new dbt patterns, new CI/CD tooling, don't land in the custom framework unless someone pays the SI to add them. The team is now operating on two clocks: the clock of the open-source world moving forward, and the clock of the custom build moving only when budget is available.
Meanwhile, the operating model gaps that existed before the SI arrived are still there. The SI wasn't asked to define naming conventions across business units, or to specify how cross-team collaboration should work, or to document who owns what. They were asked to build. So the build got built, the delivery team uses it, and the foundational questions remain unanswered. Now they're harder to address because the system is already in production and the vendor who understands it best is billing by the hour.
None of this is a critique of SIs as a category. Good SIs exist, and they can deliver real value inside a well-defined operating model. The problem is asking an SI to build a platform before the organization has decided what the platform is supposed to enforce. Under those conditions, the SI will default to what they know how to build. And what they know how to build will calcify around their way of working long after they've rolled off.
The internal champion's blind spot
The third pattern doesn't require an SI. It happens when an internal data leader, often passionate and well-intentioned, drives the modernization themselves. They know the business problem. They've seen the pain. They've done their research on the modern data stack. They build the business case and get the budget.
What they often don't have is deep production experience running a data platform at enterprise scale. They know what outcomes good platforms produce. They haven't necessarily been inside one long enough to see the operating model decisions that make those outcomes possible.
So the modernization gets shaped around what they know: the warehouse, the transformation tool, maybe a basic orchestration layer. The harder operating model questions, ownership, team topology, SLAs, standards enforcement, cross-team workflows, don't get asked because nobody in the room has been burned by skipping them before. The team inherits a modern tool stack and an immature operating model, and the symptoms start showing up twelve to eighteen months in.
Buying Snowflake, buying dbt, and hiring an SI does not give you a Data Operating Model. The tools sit inside the operating model, not above it. Starting the build before the operating model is defined, produces a platform that works technically but doesn't deliver on the business intent.
The common thread
All three patterns share the same structural problem. The build starts before the operating model is defined, and the operating model is expected to emerge on its own during delivery. It doesn't. Operating models don't emerge. They get decided, or they get compensated for.
The teams that end up with mature operating models aren't the ones who got lucky with their tool choices or their SI. They're the ones who treated the operating model as an explicit deliverable, owned by leadership, scoped at the start of the project, and refined over time as the business learned. That work is not glamorous. It doesn't show up in a conference talk. It's the difference between a platform the business trusts and a platform the business works around.
What It Looks Like When the Operating Model Is Missing
The symptoms of a missing operating model are concrete, repeatable, and visible without technical expertise. If your platform has any of them, the operating model is doing less work than the team thinks it is.
Naming drift across business units
The same concept gets six different names. CUSTOMER_ORDERS_MONTHLY_US, CUSTOMER_ORDERS_US_MONTHLY, CUSTOMER_ORDERS_MONTHLY_US_FINAL, CUSTOMER_ORDERS_US_MTHLY, and two more variations depending on which team built the model. Every variation is defensible in isolation. Together they make the platform illegible to a new engineer, impossible to govern, and fragile to extend. Naming is the most visible tell of a missing operating model because naming is decided by the operating model. When the operating model is absent, naming is decided by whoever gets there first.
Downstream teams unable to use the data products they need
A team needs to answer an ad-hoc question using data that exists in the platform but wasn't shaped for their use case. They can't use the curated layer, so they go upstream and query raw tables directly. They build parallel logic. They duplicate transformations. The platform was supposed to be the source of truth. It's now one of three sources, and the business users don't know which one to trust.
This is a cross-team workflow problem. The operating model was supposed to define how downstream teams extend the platform, how they request new data products, and what process turns an ad-hoc query into a curated asset. It didn't, so each team invented its own answer.
GenAI exposes what the operating model never enforced
Wide tables work reasonably well for operational reporting. A business analyst can find their way around a hundred-column table if they know what they're looking for. GenAI can't. Large language models answering business questions need narrow, purpose-built tables with clean column-level documentation, consistent naming, and traceable lineage. None of that comes from the warehouse. All of it comes from the operating model.
Enterprises that deferred documentation, skipped column-level descriptions, and let naming drift for three years are discovering that their AI initiative is surfacing every gap at once. The foundation they never built is now the thing blocking the board-mandated priority.
Unmet requirements surface at UAT, not in design
Requirements that should have been caught in the design phase land in UAT instead. The business user sees the data and says "that's not what I asked for." The team goes back to rework. The go-live date slips. The credibility of the delivery process erodes. Everyone agrees that requirements gathering needs to be better next time.
Requirements gathering isn't the problem. The problem is that the operating model never defined how business users participate in data product design, who validates the model before build starts, or what the acceptance criteria look like before UAT begins. Without that definition, the feedback loop closes at the wrong end of the project.
Governance deferred as a future project
The executive summary lists "governance" as a Q2 initiative, then a Q3 initiative, then a Q1-next-year initiative. It keeps getting pushed because nobody owns it, nobody scoped it, and it doesn't have a clear business sponsor. Meanwhile, the platform is live. Data products are shipping. Access is being granted through manual tickets. Metadata is being maintained by whoever remembers to maintain it.
Governance deferred is governance that never happens. The operating model defines governance as a dimension of every decision, not a separate project. When it lives in the future, it stays there.
Metadata, lineage, and column documentation missing by default
Nobody decided to skip documentation. It just wasn't on the project plan. Column-level descriptions don't exist because writing them wasn't part of anyone's definition of done. Lineage isn't captured because the framework doesn't surface it automatically and no one has time to maintain it manually. Business users asking "where does this number come from?" get an answer from whichever engineer built the model, if that engineer is still on the team.
Documentation that depends on discipline is documentation that degrades. The operating model is supposed to make documentation a byproduct of the build, not a deferred task.
Framework changes require the original builder
The internal team can use the platform but can't extend it. Every new data source, every new transformation pattern, every new capability requires going back to the SI or the original architect. This dependency was never called out explicitly, but it's now the single biggest constraint on the team's ability to move. And it gets more expensive every quarter.
Access assignment dependent on manual steps
A new table or view is created. Someone is supposed to configure it, so the right roles get access. Sometimes that step gets skipped. When it does, the object exists in the warehouse, but access doesn't propagate. Users can’t see the new object. Someone spends a morning figuring out why. The fix is trivial. The pattern repeats next month with a different table.
The operating model was supposed to decide whether access assignment happens through automation or through a manual checklist. Either answer is defensible. No answer, and automation happens when someone remembers it and breaks when they don't.
Lower environments drift from production
DEV is refreshed on an ad-hoc cadence. PRE-PROD is "closer" to PROD but still out of sync. A change passes testing, hits production, and behaves differently because the data shape in production isn't what the team tested against. The business finds out. Trust erodes.
Environment parity is an operating model decision. Without one, every team defaults to "good enough for today" and the divergence between environments becomes structural.
Dependencies managed by convention, not by the system
Pipeline dependencies live in configuration files that developers update as they remember. If an upstream dependency is missing from the config, the data quality checks are the last safety net. When DQ coverage has gaps, the pipeline runs on incomplete data and nobody notices until a downstream user raises a ticket.
The operating model should have decided whether dependencies are inferred from the code or declared in configuration, and whether a missed declaration fails the build or silently succeeds. Without that decision, the default is "silently succeeds," which is the failure mode nobody wants, and everybody ends up with.
If three or more of these are familiar, the root cause is a missing operating model. The symptoms are the system telling you so.
Checklist Control vs Platform Enforcement
The single most useful frame for diagnosing a data platform is whether the controls that matter are enforced by the system or by people remembering to follow a process. This distinction cuts through every conversation about tools, frameworks, and team maturity. It's also the fastest way to predict how a platform will behave under growth, turnover, and pressure.
Most enterprise data platforms are checklist-controlled and presented as if they were platform-enforced. The gap between the two is where the symptoms in the previous section come from.
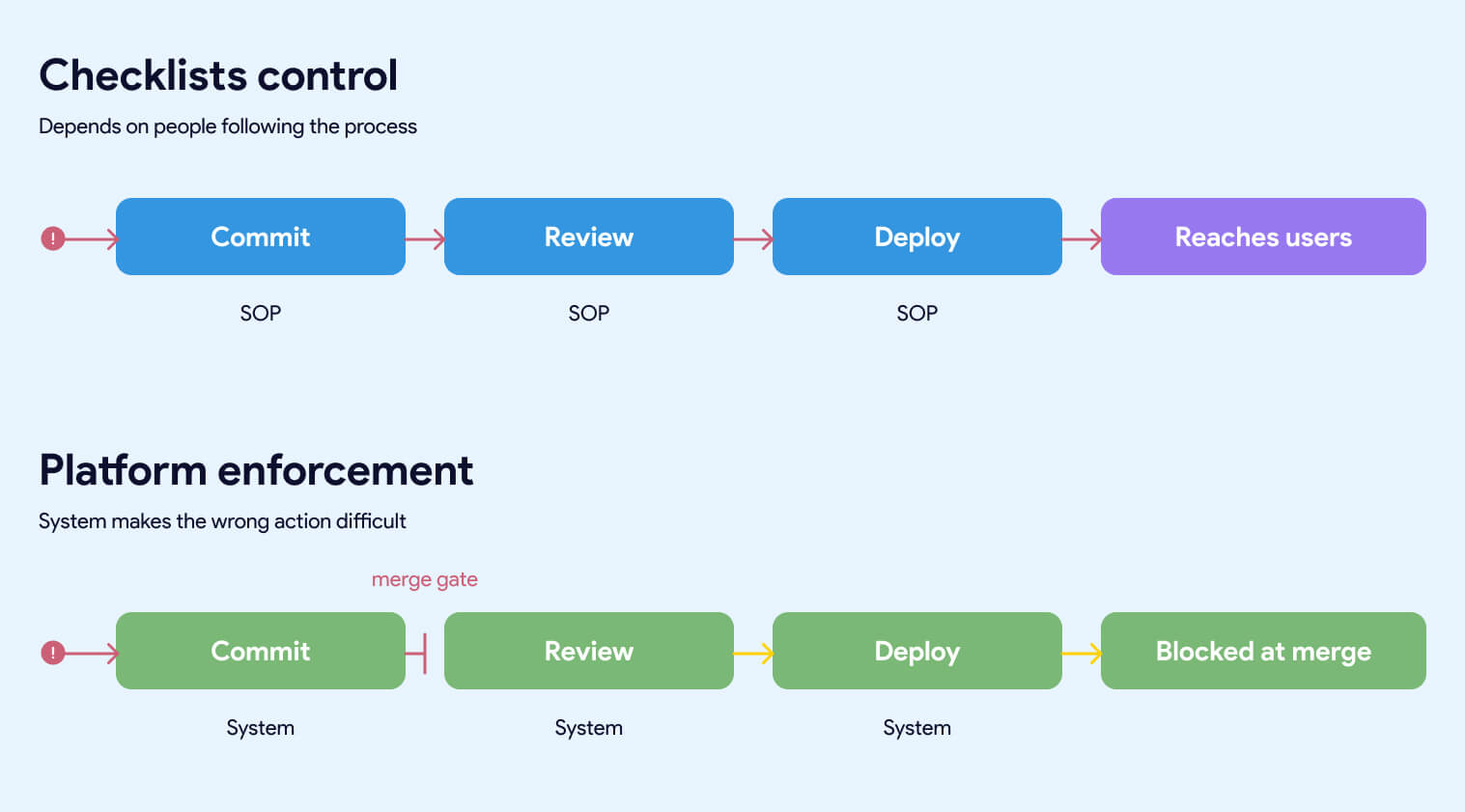
Checklist control
A checklist-controlled platform depends on people doing the right thing every time. Naming conventions live in a document that gets read once during onboarding. Access assignment requires someone to update a configuration table after creating a new object. Code quality depends on the reviewer having a good day. Dependencies get declared when the developer remembers to declare them. Documentation happens when there's time.
This works when the team is small, experienced, and under no time pressure. It degrades the moment any of those three conditions change. A new hire inherits the SOPs but not the instincts. A team lead rolls off and takes the context with them. A deadline compresses and the first thing that gets skipped is whatever depends on discipline rather than on the build itself.
Every failure in a checklist-controlled platform produces the same diagnosis: someone didn't follow the process. Which is accurate, and beside the point. The real diagnosis is that the platform was designed to require people to follow a process in a place where the system could have enforced it automatically.
Platform enforcement
A platform-enforced system makes the wrong action difficult, obvious, or impossible. Naming conventions are validated by CI/CD before a pull request can merge. Access is granted by the system based on rules, not by someone updating a table after the fact. Code quality is enforced by automated linting, testing, and review requirements that run on every commit. Dependencies are inferred from the code and validated against the actual pipeline. Documentation is required for a model to build, not requested after the fact.
The team doesn't have to remember the rules. The rules are the system.
This is the difference between a platform that scales and one that doesn't. A platform that depends on discipline gets more fragile as the team grows. A platform that enforces the rules gets stronger as the team grows, because every new engineer inherits the guardrails on day one without reading a document or asking anyone how things work.
The comparison
The comparison that matters spans five dimensions:
Who enforces the control. Checklist platforms rely on people. Enforced platforms rely on the system. People get tired, leave, and forget. Systems don't.
Why this frame is useful to an executive
The most useful test of a data platform is this: if a person fails to follow the process, does the system stop them, or does the defect propagate? If the defect propagates, the control is a checklist. It may work today. It won't work at scale.
A data leader reading a platform architecture document usually can't tell whether the platform is checklist-controlled or enforced. The document will describe controls either way. The test is to read every control and ask: "if a person fails to follow this, does the system stop them, or does the defect propagate?"
Platforms that look mature in a demo and degrade in production are almost always checklist-controlled platforms. The demo is run by the people who wrote the checklist. The production team is everyone else.
Why These Gaps Compound at Scale
The assumption behind most enterprise data platforms is that the foundational issues surfacing today are growing pains. They'll get fixed as the team matures, as the next phase of the build lands, as the governance workstream finally kicks off. This assumption is wrong.
Foundational gaps don't resolve themselves as the platform grows. They compound. Every new hire inherits the SOPs. Every new business unit multiplies the manual steps. The window to fix foundational issues cheaply closes quickly after go-live.
Four mechanisms make them worse.
New hires inherit SOPs, not guardrails
Every new engineer who joins the team inherits whatever controls are in place on their start date. If the controls are platform-enforced, they inherit the guardrails automatically. The system makes the right action easy and the wrong action difficult. Onboarding becomes a matter of learning the business, not learning which of fourteen naming conventions applies to which business unit.
If the controls are checklist-based, new engineers inherit a document. Or a wiki. Or a Slack message from someone who remembers how things worked six months ago. The quality of their work becomes a function of how thorough their onboarding was and how carefully they read a Confluence page that may or may not be up to date.
The more engineers you onboard, the more variation accumulates. Naming drift gets worse with every new hire. Documentation gaps multiply. Cross-team conventions diverge. The team isn't doing anything wrong. They're just operating in a system that produces drift as its default behavior, and the drift is proportional to team size.
New business units multiply the manual steps
A platform serving one business unit can absorb a surprising amount of process debt. The people involved know each other. Context gets shared informally. Workarounds get remembered.
A platform serving four business units cannot. Every manual step that exists in the operating model, registering a new source, assigning access to a new object, declaring a pipeline dependency, updating a config table, reviewing a model against naming conventions, has to happen four times, by four different teams, under four different sets of pressures. The error rate doesn't stay constant. It grows.
The platform was built to handle the first business unit. The second business unit stressed it. The third exposed the gaps. By the fourth, the team is spending more time coordinating across business units than building for any of them. None of this was visible in the original design. It becomes visible only at the scale where the gaps matter.
Vendor dependency deepens over time
Platforms built around a custom SI-delivered framework, a proprietary metadata layer, or a heavily customized orchestration stack produce a specific kind of debt: the debt of vendor knowledge. The people who built the system understand it. Nobody else does. As time passes, the system gets larger, the edges get more ornate, and the cost of explaining it to a new team gets higher.
The organization reaches a point where it can't extend the platform without the original builder. Every change requires a new engagement. Every new capability has a price tag attached. The open-source world is shipping new Airflow features, new dbt patterns, new CI/CD tooling, and new governance capabilities, none of which land inside the custom framework unless someone pays for the port. The gap between what's possible and what the team can actually use widens every quarter.
This is not a problem you can engineer your way out of once you're in it. The only way to solve it is to replace the custom layer with something the internal team can own, which is a second transformation program on top of the first.
Audit and compliance drift becomes undetectable
Manual processes produce manual records. Agile board tickets. IT change logs. A spreadsheet that tracks who has access to what. Each of these is updated by a person, which means each of them can drift from the actual state of the system without anyone noticing.
In a small, well-disciplined team, the drift is minor. At enterprise scale, it's structural. Documented controls say one thing. The system is configured another way. Nobody notices until a compliance review surfaces the discrepancy, or until an incident makes it obvious that the access model on paper doesn't match the access model in production.
The teams that avoid this don't have better discipline. They have infrastructure as code, automated audit trails, and platform-enforced access management. The audit log is a byproduct of the system itself, not a ledger someone has to maintain.
The time window is shorter than leaders think
The most dangerous assumption about foundational gaps is that they can be addressed later, once the delivery pressure eases. Delivery pressure never eases. The backlog grows. The business adds new use cases. The board adds an AI mandate. The team that was going to refactor the foundation in Q3 is now fighting fires through Q4.
Meanwhile, every new data product built on top of the existing foundation inherits the same gaps. Refactoring gets more expensive every month, not less. The window to fix foundational issues cheaply closes quickly after go-live. After that, every fix is a migration, and every migration competes with the delivery work the business is asking for.
The teams that treat operating model gaps as technical debt to be addressed later are making a bet about time that almost never pays off. The teams that treat operating model gaps as blockers to be addressed now are the ones that come out of the next three years with a platform the business trusts.
Why GenAI Makes the Operating Model Non-Optional
Every CEO has a GenAI mandate. Every board is asking about it. And yet a July 2025 MIT NANDA study found that 95% of enterprise GenAI pilots delivered no measurable P&L impact, despite $30–40 billion in enterprise spending. The default assumption behind those investments was that the data foundation was ready. It almost never is.
GenAI is the forcing function that makes operating model gaps impossible to hide. Wide tables, missing column descriptions, undocumented lineage, and manual access management all break AI workloads before they break human users.
Wide tables break LLMs faster than they break humans
A business analyst can work with a hundred-column table. They know what they're looking for, they skip the columns that don't matter, and they ignore the fields with unclear definitions. A large language model can't. When an LLM is given a wide table with inconsistent naming and missing column descriptions, it hallucinates. It picks the column that sounds right. It joins on a field that looks like a key and isn't. The output is confident and wrong.
The fix is narrow, purpose-built tables with clean semantics. Column names that describe what they contain. Column descriptions that explain business meaning. Consistent naming across related tables. Clear primary and foreign key relationships. These aren't data engineering niceties. They're the minimum viable inputs for AI that produces trustworthy answers.
Enterprises that spent three years building wide, denormalized operational reporting tables are now discovering that those tables can't be pointed at GenAI directly. They need a second modeling layer, often called a semantic layer, built for AI consumption. That layer takes real work to build. It's a project nobody scoped, running parallel to the existing delivery pressure.
Column-level documentation is suddenly the critical path
For years, column descriptions were a nice-to-have. Data catalogs had them when a team made the effort. Documentation quality varied by business unit, by team lead, by quarter. The business mostly worked around the gaps.
GenAI changes that math. An LLM answering a business question needs to know what every column means. If the column descriptions are missing, stale, or wrong, the model fills in the gaps with plausible-sounding guesses. The answers come back polished and authoritative. The errors are invisible until a business user acts on a wrong number.
The operating model was supposed to decide that column descriptions are a requirement, not an afterthought. Most operating models didn't. So now the team is writing three years of back-documentation under board pressure, on top of the existing delivery work, for data products that have been live for months.
Lineage becomes a trust requirement
When a business user asks an LLM "why is our Q3 revenue in the Northeast region down?", the LLM's answer is only as trustworthy as the lineage of the data it's querying. Where did the number come from? What source fed it? What transformations were applied? Which version of the transformation logic was in effect when the number was computed?
Platforms without end-to-end lineage can't answer those questions. The business user doesn't know what to trust. The data team can't validate the AI's output. The GenAI initiative produces answers that are confidently wrong, fails an executive review, and gets shelved.
Lineage is an operating model decision. Platforms that made the decision to capture lineage automatically as part of the build have it. Platforms that deferred lineage to a future governance project don't. And the second category is scrambling.
Gartner predicts that through 2026, organizations will abandon 60% of AI projects unsupported by AI-ready data. In addition, 63% of organizations either don't have or are unsure about having the right data management practices for AI. This is not a theory, it's already arriving on board agendas.
Access models break under AI workloads
Operational reporting has predictable access patterns. A business analyst queries the tables they've been granted access to. A dashboard uses a service account with a defined permission scope. Everyone knows what's authorized and what isn't.
GenAI workloads don't behave that way. An LLM with access to "the sales data" may try to answer a question by joining across tables that sit in different access tiers. Natural language queries don't respect the access boundaries that were designed for structured SQL. Platforms with manual access assignment and checklist-controlled permissions produce one of two outcomes: AI that can't answer the question because it can't access the data, or AI that answers the question by accessing data it shouldn't have seen.
Both outcomes are failures. The fix is access management that's granular, automated, and enforced by the system. The operating model was supposed to define that. If it didn't, the GenAI initiative is about to expose exactly which data is governed and which data is governed by accident.
The compressed timeline
The operating model problems that felt tolerable in 2023 are intolerable in 2026. The board isn't giving the data team three years to refactor. They're asking for GenAI pilots in six months and production AI in twelve.
Teams with a defined operating model and a platform that enforces it are shipping those pilots already. They're not scrambling to back-fill documentation, rebuild wide tables into semantic layers, or retrofit access management. The work was done during the build, because the operating model made it part of the build.
Teams without that foundation are rediscovering every gap under deadline pressure. The AI initiative is failing because the foundation underneath it was never ready, and GenAI is the first workload that refuses to work around the foundation's problems.
If your data platform has the symptoms described earlier in this article, your GenAI initiative will surface every one of them. On a timeline the business is about to compress.
What to Do If You're Already Mid-Build
Most executives reading this article are not at the start of a data platform project. They're twelve, eighteen, twenty-four months in. The warehouse is live. The framework is in production. The first business unit is using it. The symptoms are real, and the question isn't whether the operating model should have been defined earlier. It's what to do now.
The answer is not to rip everything out. It's also not to accept the current trajectory and hope the next phase of the build compensates for the gaps in the current one. There's a middle path, and it starts with changing what the team is working on, not what it's working with.
Define the operating model before you write another line of code
Decisions first. Build second. Even mid-project.
The operating model is a finite set of decisions. A working session with the right people in the room can get most of the way through the list in a week. What matters is that the decisions get made deliberately and written down, not that they get made perfectly on the first try.
The decisions that matter most, in order of impact:
Naming conventions. Pick them. Write them down. Validate them automatically in CI. Every future asset conforms. Existing assets get renamed on a defined schedule.
Ownership map. Every data product has a named owner. Every source has a named owner. Every shared model has a named owner. If ownership is unclear, that's the first decision to make, not the last.
Layering semantics. What is raw data? What is a cleaned source? What is a business entity? What is a data product? Four layers, defined crisply, consistent across business units. Not six layers with three teams using them differently.
Access and environment parity. How is access granted? How is it reviewed? What's the refresh cadence for lower environments? Are DEV and PRE_PROD in sync with PROD, and if not, is that a known and accepted limitation or a problem nobody has prioritized?
SLAs. What does the business expect? For a new KPI. For a source onboarding. For a production incident. These get documented. Trade-offs get discussed explicitly instead of assumed.
Cross-team workflows. When the second and third business units onboard, how do they request data products from the central team? How do they extend models the central team owns? How do they avoid duplicating logic that already exists? This is the workflow that scales the platform beyond its first success.
Governance. Not as a future project. As a dimension of every decision already on this list. Ownership, access, naming, and lineage are all governance. If "governance" is still on the roadmap as a separate workstream, it's already too late.
The output of this work is a document. Short, explicit, and owned by a named executive. Not a deck. Not a wiki page. A written operating model that the team can point to when decisions come up, and that the platform can enforce.
Separate the operating model from the infrastructure underneath it
The team's energy should go into operating model decisions, not rebuilding Git workflows, CI/CD, and orchestration from scratch.
If the operating model is a finite set of decisions, the infrastructure underneath it is the larger ongoing cost. Git workflows. CI/CD pipelines. Development environments. Secrets management. Orchestration. Deployment standards. Testing frameworks. Every team that builds a serious data platform eventually must build or buy all of it.
Teams that try to build the operating model and the infrastructure at the same time, with the same people, end up doing neither well. The operating model decisions get rushed because infrastructure is urgent. The infrastructure gets built without operating model clarity because decisions haven't been made yet. Both suffer.
The teams that succeed separate the two. The operating model is their work. The infrastructure underneath it is either delegated to a platform that's already built or scoped as a distinct workstream with its own ownership. When the team's meeting time is spent on operating model decisions instead of CI/CD configuration, the operating model gets defined faster, and the infrastructure stays consistent with it.
Ask the diagnostic questions
The hardest part of acting on a missing operating model is knowing where the gaps are. The executive asking, "is our operating model mature?" is usually not close enough to the platform to answer it. The people close enough to answer are often incentivized to say everything is under control.
A small set of diagnostic questions surfaces where the operating model is doing work and where it isn't. Answering them honestly takes an hour. The pattern of answers tells you where to focus first.
On enforcement. Which of your data platform controls are enforced by the system, and which depend on people following a process? If a team member fails to follow the process, does the system stop them, or does the defect reach production?
On ownership. For every data product in your platform, can you name the owner in under thirty seconds? If not, how many orphans are there, and who inherits them when something breaks?
On naming and layering. Can a new engineer look at a table name and know what layer it belongs to, which business unit owns it, and what it contains? If not, how much context do they have to ask for before they can do their job?
On vendor dependency. If the SI or original architect of your platform disengaged tomorrow, could your internal team extend the framework? If not, how much of your roadmap depends on their continued engagement, and what's the cost?
On governance. Is governance a live dimension of every decision, or is it a future project on a slide deck? If it's a future project, how long has it been there?
On GenAI readiness. Could your current platform support a GenAI product that a business user would trust with a strategic decision? If not, what specifically is missing, and how long would it take to build?
On the time window. If you did nothing to change the current trajectory, what does the platform look like in twelve months? If the answer is "worse than today," the operating model work isn't optional.
How the Platform Layer Enforces the Operating Model
The operating model is the set of decisions. The platform layer is the system that makes those decisions automatic. Separating the two is how mature data organizations move fast without degrading quality as they scale.
Datacoves exists because most enterprise data teams are spending their time on the wrong layer. They're rebuilding Git workflows, configuring CI/CD, standing up orchestration, wiring secrets management, and writing deployment conventions from scratch, on top of running the business. That work is necessary. It's also not differentiated. Every enterprise data team needs the same underlying platform capabilities, and every team that builds them in-house takes six to twelve months to get there, plus ongoing maintenance that never ends.
Datacoves delivers those capabilities preconfigured, inside the customer's private cloud, running on open-source tools the internal team can own. The operating model decisions still belong to the organization. The infrastructure underneath them is already built.
What the platform enforces out of the box
Git workflows with branching conventions, pull request requirements, and automated validation on every commit. Naming conventions, testing requirements, and documentation expectations get enforced before code merges. A missed convention doesn't reach production because the system doesn't let it.
CI/CD pipelines that run dbt tests, SQL linting, governance checks, and deployment validation automatically. Quality becomes a property of the pipeline itself, regardless of how attentive the reviewer is that morning.
Managed Airflow for orchestration. Pipeline dependencies, retries, failure alerts, and scheduling work consistently across every team. My Airflow for developer testing, Teams Airflow for production. Engineers don't rebuild orchestration conventions for each new project.
In-browser VS Code environments that come up preconfigured with dbt, Python, SQLFluff, Git integration, and every tool the team needs. A new engineer opens their environment on day one and starts writing code. Onboarding time drops from weeks to hours.
Secrets management integrated with the customer's existing vault or AWS Secrets Manager. Credentials never live in code. Access is controlled by the system itself.
Deployment standards that promote code from development through testing to production on the same workflow every time. No manual deployment steps. No scripts that only one person knows how to run.
Governance enforcement at commit time. dbt-checkpoint catches quality issues before they reach the pipeline. SQLFluff keeps SQL consistent. Naming conventions validate in CI. The team doesn't remember the rules because the system enforces them.
Why this is the platform enforcement model the article has been describing
Every control listed above is a system-enforced version of a checklist most enterprise platforms maintain manually. The difference in outcomes is structural, not incremental. A platform that enforces these controls automatically produces consistent quality at any team size. A platform that depends on discipline degrades as the team grows.
Datacoves is built around the assumption that the operating model is the customer's work, and the infrastructure that enforces the operating model should be the platform's work. That separation is what lets the customer's team spend its time on decisions that differentiate the business, not on infrastructure that every data team needs and no data team should have to build.
What this means for a mid-build team
For a team already running on Snowflake with a custom framework or an SI-built platform, Datacoves is the alternative to a second transformation program. Instead of rebuilding the infrastructure layer internally or paying the SI to port new capabilities, the team moves to a platform that already has them. The operating model foundation the team needs to do anyway becomes the focus. The infrastructure underneath it is no longer the team's ongoing cost.
The customers who've made this move describe the outcome the same way: the engineering team stopped maintaining plumbing and started shipping data products. Guitar Center onboarded in days. Johnson and Johnson described it as a framework accelerator. Those aren't luck. They're the result of a platform layer that enforces the operating model by design.
If the symptoms earlier in this article match what you're seeing, the next step is a conversation about where the gaps are and what the platform layer can take off your team's plate. Book a free architecture review. The review surfaces the operating model gaps driving the symptoms the business is already complaining about, and it's the fastest way to see whether the platform layer can shorten the path to the outcomes you expected when you started the build.
A Data Operating Model is the work most enterprises skip because nobody told them it was the work. The tool purchase felt like progress. The SI engagement felt like progress. The first use cases shipping felt like progress. By the time the symptoms surfaced, the decisions that would have prevented them had been deferred long enough to become expensive.
The executives who get this right aren't smarter than the ones who don't. They're just earlier. They define the operating model before the build starts, or they stop the build long enough to define it once they realize it was never decided. The teams that do that work once ship data products for years afterward. The teams that don't spend those same years compensating for decisions that were never made.
If the symptoms in this article match what you're seeing in your own platform, the message is simple. The tools aren't failing you. The operating model underneath them is, and it will keep failing until somebody decides to define it. That work is smaller than it looks, it's faster to do than to defer, and it's the only path to the outcomes the business was expecting when the project started.
Your team has spent eighteen months proving they can build. The next eighteen months are going to be about whether the business trusts what got built. That outcome is decided at the operating model layer, not at the tool layer. The sooner leadership treats it that way, the sooner the symptoms stop.
FAQ:
Can we fix a missing operating model after the platform is already live?
Yes, but the cost grows every month. Foundational gaps compound. New engineers inherit SOPs instead of guardrails. New business units multiply manual steps. Vendor dependency deepens. The fix doesn't require ripping the platform out. It requires defining the operating model decisions explicitly, then moving to a platform layer that enforces those decisions automatically so the team can focus on governing the model instead of rebuilding the infrastructure underneath it.
Do I really need a Data Operating Model if I already have Snowflake and dbt?
Yes. Snowflake and dbt are tools that sit inside a Data Operating Model, not substitutes for one. The operating model decides how those tools get used: who owns the data products built with them, what naming and layering conventions apply, how code gets promoted to production, and how cross-team collaboration works. Without those decisions, the tools produce drift, duplication, and workarounds.
How do I know if my data platform has a missing Data Operating Model?
The symptoms are observable without technical expertise. Naming inconsistencies across business units. Downstream teams unable to use curated data products. Unmet requirements surfacing at UAT instead of during design. Governance deferred as a future project. Framework changes that require the original builder to extend. If three or more of those patterns match what you're seeing, the operating model is missing or never fully defined.
How long does it take to define a Data Operating Model?
The decisions themselves can be made in weeks, not quarters. Naming conventions, ownership maps, layering semantics, access patterns, SLAs, cross-team workflows, and governance scope are finite decisions that a working session with the right people can resolve. The ongoing work is refining and governing them over time, not defining them once. Most enterprises are surprised by how compressed the timeline can be when leadership treats it as urgent.
What are the components of a Data Operating Model?
A mature Data Operating Model answers seven questions: who owns what, how teams are structured, how work moves through the system, what standards apply, what SLAs the business expects, how governance is enforced, and what the platform layer underneath has to automate. Every component is a decision, not a tool choice.
What is a Data Operating Model?
A Data Operating Model is the set of decisions that define how a company delivers value from data. It covers ownership, team topology, workflows, standards, SLAs, governance, and the platform layer underneath. The tools sit inside the operating model, not above it. Without a defined operating model, tools produce inconsistent outcomes regardless of how good they are individually.
What is the difference between checklist control and platform enforcement?
Checklist control means the platform's quality depends on people following standard operating procedures every time. It works in small, experienced teams and degrades under growth, turnover, and pressure. Platform enforcement means the system itself makes the wrong action difficult or impossible. Naming, access, dependencies, and testing are enforced automatically rather than remembered. Platforms that depend on discipline get more fragile at scale. Platforms that enforce the rules automatically get stronger at scale.
What's the difference between a data strategy and a Data Operating Model?
A data strategy defines the outcomes you're trying to achieve with data, such as faster insights, better forecasting, or AI-powered products. A Data Operating Model defines the decisions that determine whether the strategy produces those outcomes. Strategy is the "why." Operating model is the "how, at the organizational level."
Why does GenAI expose Data Operating Model gaps?
AI workloads depend on clean column-level documentation, consistent naming, narrow purpose-built tables, and end-to-end lineage. None of those come from the warehouse. All of them come from the operating model. Wide tables that work for operational reporting produce hallucinated outputs when pointed at an LLM. Missing column descriptions force the model to guess. Manual access assignment breaks under natural language queries. Gartner predicts that organizations will abandon 60% of AI projects unsupported by AI-ready data through 2026. The AI initiative is the forcing function that makes operating model gaps impossible to hide.

-Photoroom.jpg)




