
dbt’s built-in tests cover the fundamentals: uniqueness, nulls, referential integrity, accepted values. But as your project grows, so do the gaps. Anomalies that no one wrote a test for. Code changes that silently break downstream models. Production pipelines that look healthy until a stakeholder finds stale data in a dashboard.
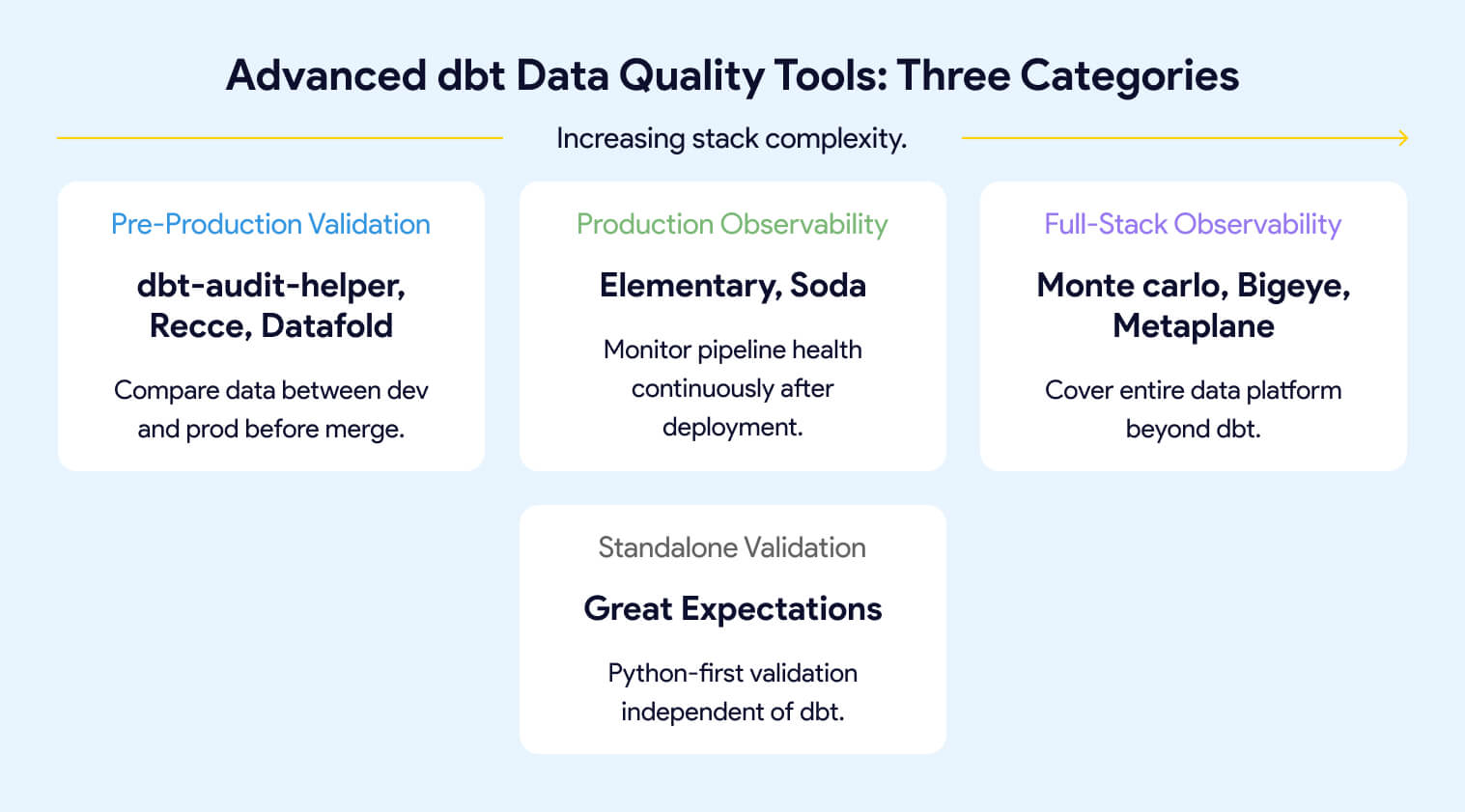
The tools in this guide pick up where basic dbt tests stop. They fall into three categories: pre-production validation (comparing data between environments before code merges), production observability (continuous monitoring of pipeline health over time), and full-stack observability (commercial platforms covering your entire data platform beyond dbt). Some tools span more than one category. The right combination depends on your team's maturity, stack complexity, and where you're losing the most time to data issues today.
This is the companion to An Overview of Testing Options for dbt, which covers everything that ships with dbt Core and the most common testing packages. If you haven’t built out your test suite yet, start there. This guide assumes you have already progressed past dbt data testing.
Where Basic dbt Tests Stop and These Tools Begin
If you’ve followed the dbt testing guide, your project already has generic tests, singular tests, and probably packages like dbt-utils or dbt-expectations for richer assertions. That coverage handles a lot. But it has a ceiling.
Rule-based tests catch what you anticipated. They won’t tell you that row volumes dropped 40% overnight, that a source table stopped arriving on schedule, that a gradual shift in null rates is slowly corrupting a downstream report, or that your “harmless” model refactor just changed 15,000 values in a column no one thought to test.
The tools in this guide fill those gaps. They fall into three categories:
Pre-production validation compares data between your development and production environments before code merges. If a model refactor changes row counts, adds or removes rows, shifts column values, or alters schema structure, these tools surface the specific differences in your PR so reviewers can see the data impact alongside the code change. Tools: dbt-audit-helper, Recce, Datafold.
Production observability monitors your pipeline health continuously after deployment. Instead of testing specific conditions, it builds statistical baselines over time and alerts you when behavior deviates: freshness failures, volume anomalies, schema changes, distribution drift. Tools: Elementary, Soda.
Full-stack observability extends monitoring beyond dbt to cover your entire data platform, including ingestion tools, warehouses, BI layers, and AI workloads. These are commercial platforms for teams where dbt is one piece of a larger stack. Tools: Monte Carlo, Bigeye, Metaplane.
A complete observability layer tracks four dimensions:
Freshness monitors whether models and sources are updating on schedule. A freshness failure often means an upstream pipeline broke before any dbt test had a chance to run.
Volume tracks whether row counts and event rates behave as expected. Sudden drops or spikes frequently signal upstream issues before any explicit test fires.
Schema detects column additions, removals, renames, and data type changes that can silently break downstream models and dashboards.
Distribution watches the statistical properties of your data over time: null rates, cardinality, value ranges. Gradual drift here can corrupt reports without triggering a single test failure.
Some tools span categories. Elementary installs as a dbt package (making it feel like an extension of your test suite) but its core value is production observability. Datafold started as a data diffing tool but now includes production monitors. The categories describe what problem you’re solving, not rigid product boundaries.
Pre-Production Validation: Catching Problems Before Merge
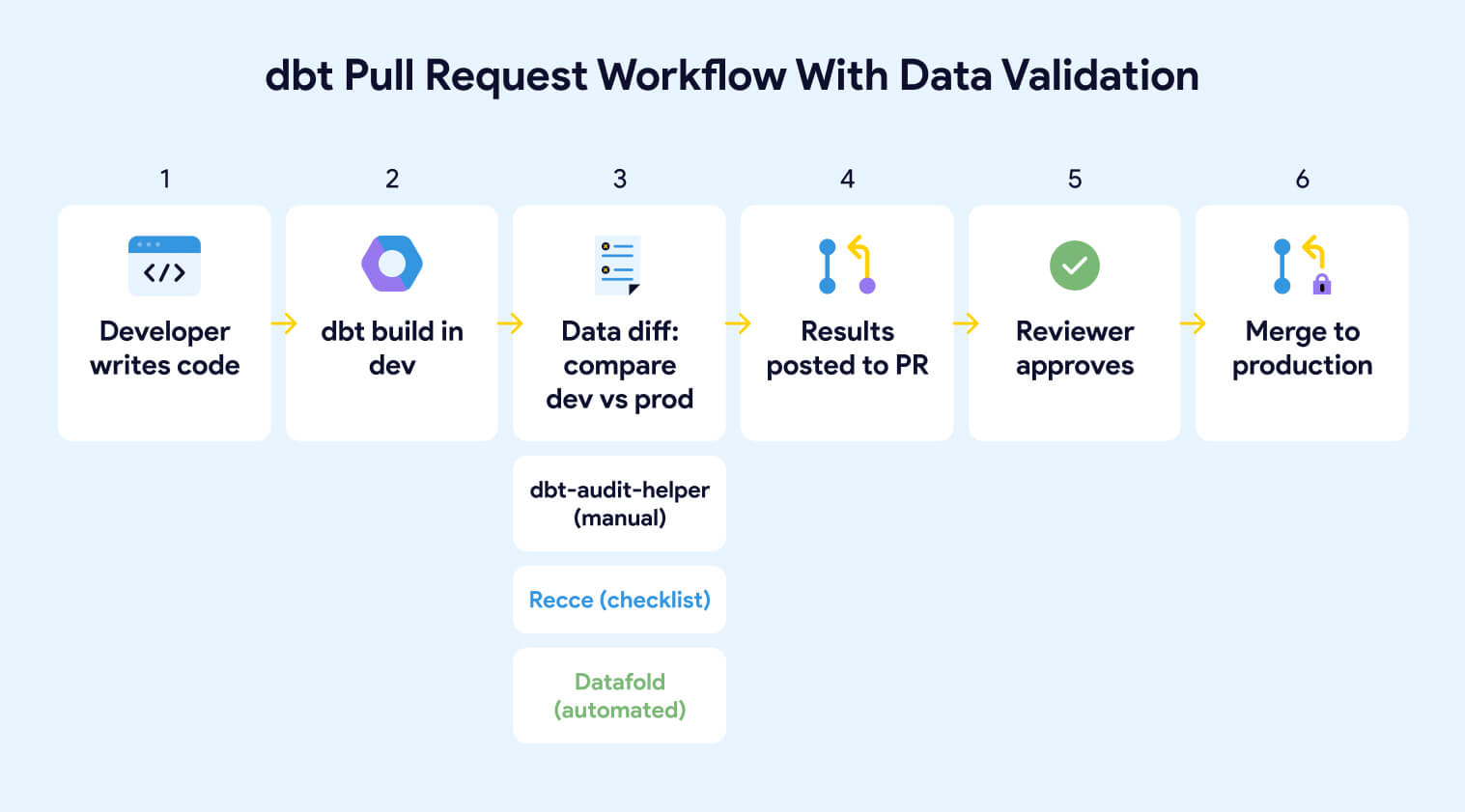
Your dbt tests pass. Your CI pipeline is green. You merge the PR. And then a stakeholder reports that revenue numbers shifted by 12% in a dashboard no one connected to the model you changed.
This happens because dbt tests validate conditions you defined, not the data impact of your code change. A model can pass every test and still produce different data than it did yesterday. Pre-production validation tools close that gap by comparing data between environments before code reaches production.
dbt-audit-helper: Data Diffing Inside Your dbt Project
dbt-audit-helper, maintained by dbt Labs, is a dbt package that compares two relations or queries row by row and column by column. It’s the simplest way to validate that a model refactor, migration, or logic change didn’t introduce unintended differences.
The package provides 10 active macros organized into four groups:
- Row-level comparison (compare_and_classify_query_results, compare_and_classify_relation_rows) classifies every row as identical, modified, added, or removed, with summary stats and sample records. These are the primary macros for most use cases.
- Column-level investigation (compare_column_values, compare_all_columns, compare_which_query_columns_differ, compare_which_relation_columns_differ) drills into which specific columns have differences and breaks down match status per column: perfect match, both null, values don't match, null in one side only, missing from one side. Use these after a row comparison reveals mismatches.
- Schema comparison (compare_relation_columns) compares column names, data types, and ordinal positions between two relations. Useful for catching structural changes during migrations or refactors.
- Quick identity check (quick_are_queries_identical, quick_are_relations_identical, compare_row_counts) provides fast yes/no answers. The quick macros use hashing for speed (currently Snowflake and BigQuery only). compare_row_counts does a simple count comparison between two relations.
A typical workflow: you refactor a model, run it against your dev environment, then use compare_and_classify_relation_rows to compare the dev output against the production version. If rows show as modified, you drill in with compare_which_relation_columns_differ to find which columns changed, then compare_column_values to understand the specific discrepancies.
dbt-audit-helper is free, open source, and runs entirely inside your dbt project. The tradeoff is that everything is manual. You write SQL files using the macros, run them one model at a time, and read the output in your terminal or warehouse. There's no UI, no PR integration, no automated detection of which models changed. For ad hoc validation during refactoring or migration, it's excellent. For ongoing change management across a team, you'll want Recce or Datafold
Recce: Data-Level PR Review for dbt Teams
Recce is an open-source data validation toolkit built specifically for dbt PR workflows. Where dbt-audit-helper requires you to write macros and run them manually, Recce automates the comparison and packages the results into a format designed for PR review.
When a developer opens a PR, Recce compares a production baseline against the development branch using a suite of checks:
- Lineage diff shows which models in the DAG were added, removed, or modified, and flags downstream models as impacted.
- Row count diff shows whether a model gained or lost rows after the change, and by how much.
- Schema diff catches column additions, removals, and data type changes in the model output.
- Value diff samples actual row values between baseline and candidate, useful for catching unintended logic changes.
- Profile diff compares the statistical shape of a model: null rates, unique value counts, min/max ranges.
As you run checks, Recce lets you add each result to a validation checklist with notes explaining your findings. When you’re ready for review, you export the checklist to your PR comment. The reviewer gets a curated summary of the data impact rather than raw output they have to interpret themselves.
Recce OSS includes all the diff tools, the checklist workflow, and a CLI for CI/CD integration. Recce Cloud (commercial version) adds an AI Data Review Agent that auto-summarizes data impact on every PR, real-time collaboration, automatic checklist sync, and PR gating. For a detailed walkthrough of the workflow, see Recce's data validation toolkit guide.
Datafold: Automated Data Diffing in CI/CD
Datafold is a commercial data engineering platform that automates data diffing as part of your CI/CD pipeline. Both Recce and Datafold run automatically on PRs, but they take different philosophies: Recce lets developers scope and choose which diffs matter, while Datafold diffs every changed model on every PR by default. Datafold's approach gives full coverage with less manual decision-making; Recce's reduces noise by keeping humans in the loop.
Datafold integrates deeply with both dbt Core and dbt Cloud. Its core capabilities:
- Data diffing in CI/CD automatically diffs changed models and their downstream dependencies on every PR, posting results as a comment
- Column-level lineage traces impact from dbt models through to BI tools like Looker and Tableau
- Production monitors track data diff, schema change, and metric anomalies via YAML configuration
- AI code review enforces SQL standards automatically on pull requests
- MCP server lets AI coding agents validate their own work against production data
- Cross-database diffing compares data across different warehouses for migrations
Datafold supports Snowflake, BigQuery, Redshift, Databricks, PostgreSQL, and DuckDB, with cross-database diffing for migrations. VPC deployment is available for teams with strict security requirements.
The open-source data-diff CLI that Datafold previously maintained was deprecated in May 2024. All diffing capabilities now require Datafold Cloud.
How dbt-audit-helper, Recce, and Datafold Compare
Production Observability: Monitoring Pipeline Health Over Time
Pre-production validation catches problems before merge. But not every data issue originates from a code change. Sources stop updating. Upstream systems introduce silent schema changes. Row volumes drift gradually over weeks until a report breaks. These are production problems, and they require tools that monitor your pipeline continuously, not just when someone opens a PR.
Elementary: Open-Source Observability for dbt
Elementary is an open-source observability tool built natively on dbt. It installs as a dbt package, runs as part of your project, and stores all observability data directly in your warehouse. No separate infrastructure, no additional warehouse connection. Elementary supports Snowflake, BigQuery, Redshift, Databricks, and PostgreSQL.
Elementary does three things:
Collects and stores test result history. Every dbt test run, including pass/fail status, failure counts, execution time, and the rows that failed, gets written to queryable tables in your warehouse. This gives you trend visibility that dbt’s native artifacts don’t provide.
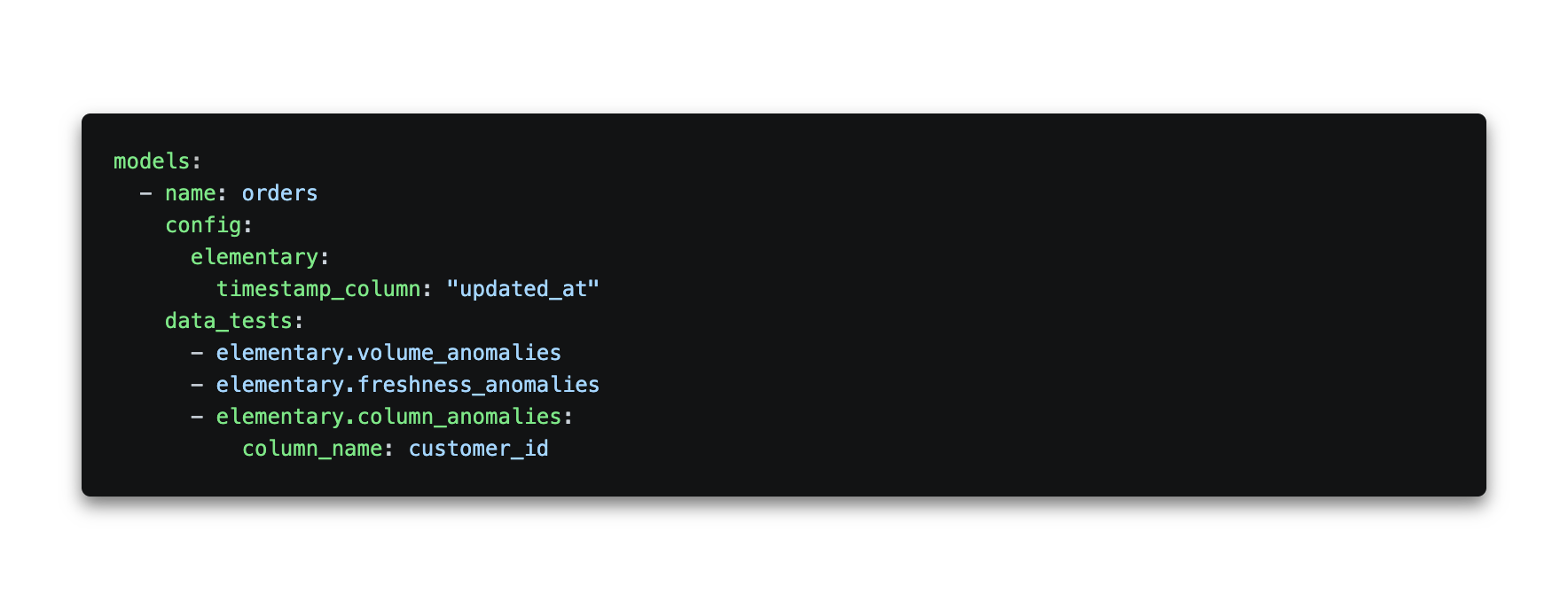
Adds anomaly detection monitors. Elementary provides dbt-native monitors you configure in YAML, covering row count anomalies, freshness, event freshness (for streaming data), null rate changes, cardinality shifts, and dimension distribution. These use Z-score based statistical detection: Elementary builds a baseline from your historical data (default 14-day training period) and flags values that fall outside the expected range. You can tune sensitivity, time buckets, and training windows per test.
Elementary OSS also includes an AI-powered test (ai_data_validation), currently in beta, that lets you define expectations in plain English. For example, expectation_prompt: "There should be no contract date in the future". Instead of running its own LLM, Elementary uses the AI functions built into your warehouse (Snowflake Cortex, Databricks AI Functions, or BigQuery Vertex AI), so your data never leaves your environment. Setup requires enabling the relevant LLM service in your warehouse first.
An Elementary monitor configuration looks like this:
Generates a self-hosted observability report. The Elementary CLI produces a rich HTML report you can host on S3, an internal server, or any static file host. It shows model lineage, test results over time, and anomaly alerts in one place. Alerts can be sent to Slack or Microsoft Teams. Full configuration options are in the Elementary docs.
Elementary also includes schema validation tests (detecting deleted or added columns, data type changes, deviations from a configured baseline, JSON schema violations) and exposure validation (detecting column changes that break downstream BI dashboards).

OSS vs. Cloud: The features above are all available in Elementary OSS. Elementary Cloud adds automated monitors that require no YAML configuration, column-level lineage extending to BI tools, a built-in data catalog, incident management, AI agents for triage and test recommendations, and a collaborative UI for non-technical users.
Elementary is the right starting point for most dbt teams because it fits inside a workflow you already have. Adding it requires a package installation and a few lines of YAML. If your needs grow beyond what OSS provides, the Cloud tier is the upgrade path.
Soda: Human-Readable Data Quality for Cross-Functional Teams
Soda is an open-core data quality platform designed so that analysts and business stakeholders can write and own quality checks alongside the engineering team. Where Elementary is built for engineers working inside dbt, Soda is built for shared ownership of data quality across roles.
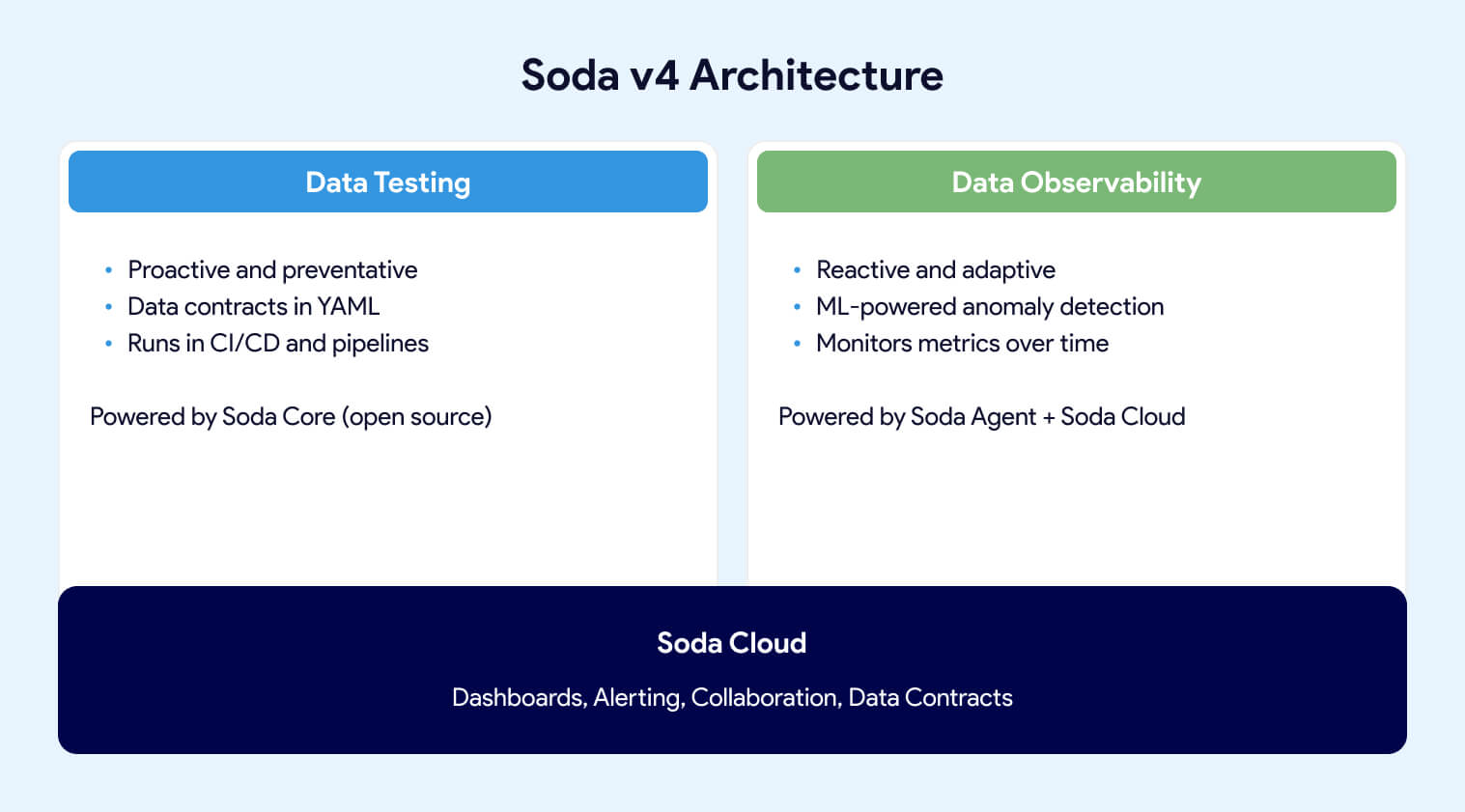
With the release of Soda v4, the platform has two pillars: Data Testing (proactive, contract-based validation) and Data Observability (reactive, ML-powered monitoring in production). This marks a shift from the earlier CLI-centric approach toward a unified data quality platform.
Soda v4 introduces a Contract Language, a YAML-based format for defining data quality expectations as enforceable agreements between data producers and consumers. A data contract looks like this:
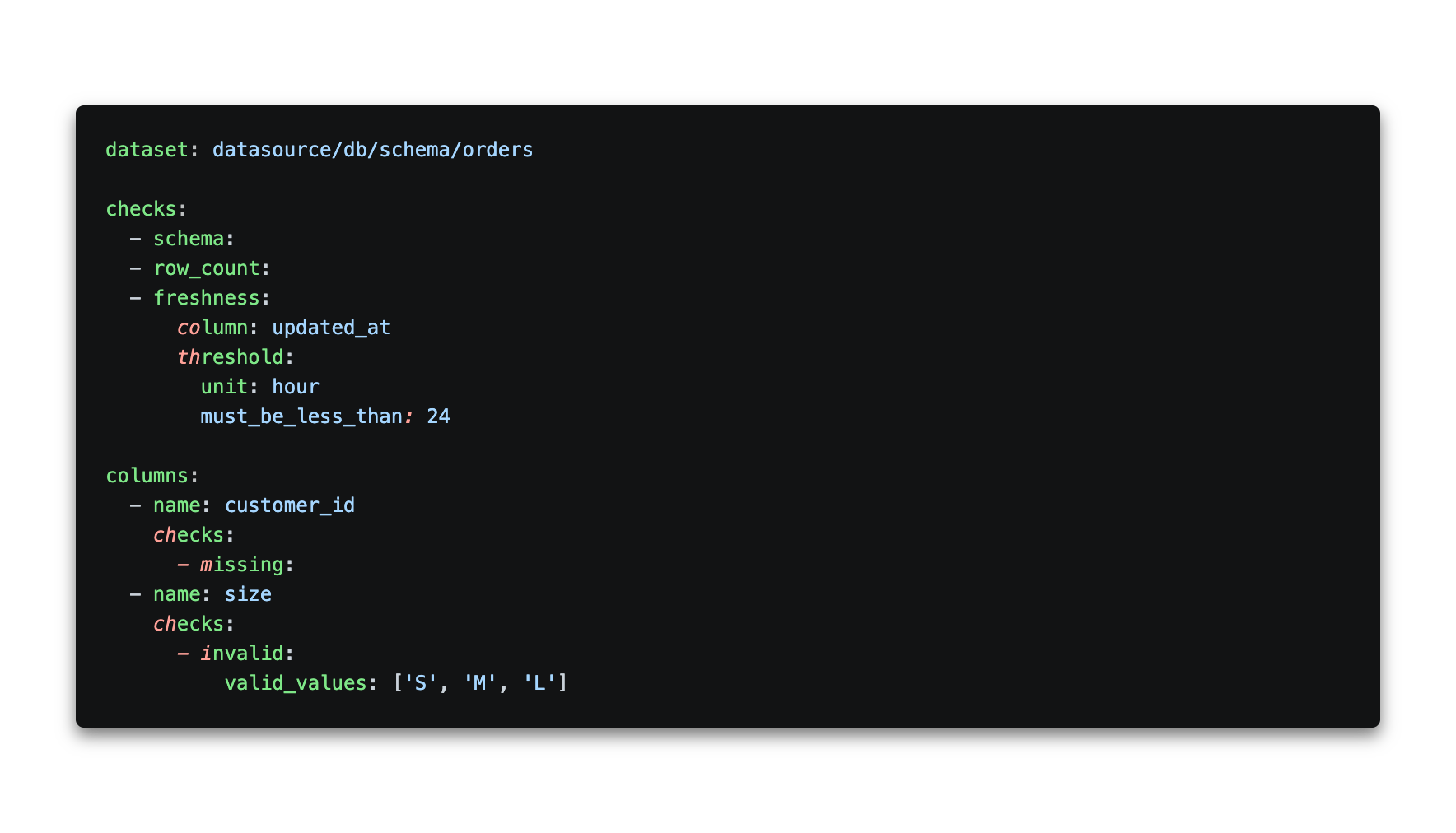
Contracts are verified using Soda Core v4, the open-source Python engine that now functions as a Data Contract Engine. It runs contract verifications locally or in pipelines and supports 50+ built-in data quality checks. Soda Core v4 does not include observability features; those require Soda Cloud or a Soda Agent.
Teams still using SodaCL (the v3 check language) can continue doing so, but new development is centered on the Contract Language. SodaCL documentation is maintained under the Soda v3 docs.
Soda's deployment model has three tiers. Soda Core (open source) runs contract verifications in your pipelines. Soda-hosted Agent is a managed runner that adds observability, scheduling, and the ability to create checks from the Soda Cloud UI. Self-hosted Agent provides the same capabilities deployed in your own Kubernetes environment. Observability features (anomaly detection, metric trending, automated monitoring) require either Agent option plus Soda Cloud.
Soda Cloud is the commercial SaaS layer that adds dashboards, alerting (Slack, MS Teams, Jira, PagerDuty, ServiceNow), collaborative data contracts with role-based ownership, and a UI for both technical and non-technical users.
Soda isn't dbt-native. It works independently and can ingest dbt test results into Soda Cloud for visualization rather than replacing your dbt tests. It integrates with Airflow, Dagster, Prefect, and Azure Data Factory for orchestration, and with Atlan, Alation, and Collibra for data cataloging. It supports Snowflake, BigQuery, Redshift, Databricks, PostgreSQL, DuckDB, and more.
If data quality ownership needs to extend beyond your engineering team, or you need a warehouse-agnostic quality layer that works both inside and outside dbt, Soda is built for that. The producer/consumer contract model is its most meaningful distinction from Elementary.
Full-Stack Observability Beyond dbt
Elementary and Soda work well when dbt is the center of your data stack. But many organizations run pipelines that span ingestion tools, multiple transformation layers, legacy ETL platforms, and BI tools that dbt never touches. When a data quality issue could originate anywhere in that chain, you need observability that covers the full stack, not just the dbt layer.
Monte Carlo: Enterprise Data + AI Observability
Monte Carlo is a commercial observability platform that connects directly to your warehouse and automatically learns the baseline behavior of your tables using ML. No manual threshold configuration, no YAML. It supports Snowflake, BigQuery, Redshift, and Databricks across all three clouds, plus data lakes via Hive and Glue metastores.
Where Elementary requires you to define each monitor, Monte Carlo deploys monitoring out of the box. It provides automated field-level lineage across your entire stack (not just dbt), integrates with Airflow, Fivetran, Azure Data Factory, Informatica, Databricks Workflows, Prefect, Looker, Tableau, and dbt, and includes centralized incident management.
In 2025, Monte Carlo launched Observability Agents: a Monitoring Agent that recommends and deploys monitors automatically based on data profiling, and a Troubleshooting Agent that investigates root causes by testing hundreds of hypotheses across related tables in parallel. Monte Carlo now also extends monitoring to AI agent inputs and outputs alongside traditional pipeline health.
Monte Carlo’s value compounds as your stack grows beyond dbt. For teams running primarily dbt workloads, the overhead and cost typically outweigh the benefits compared to Elementary. But for large, multi-tool platforms with SLA requirements and dedicated data reliability teams, Monte Carlo is purpose-built.
Bigeye: Enterprise Observability Across Modern and Legacy Stacks
Bigeye is a commercial observability platform that differentiates on lineage depth. After acquiring Data Advantage Group, Bigeye offers end-to-end column-level lineage across both modern cloud warehouses and legacy ETL platforms including Informatica, Talend, SSIS, and IBM DataStage. That makes it a strong fit for enterprises running hybrid stacks where not everything lives in Snowflake or Databricks.
Bigeye provides 70+ data quality monitoring metrics with ML-powered anomaly detection, and supports join-based rules that validate data across tables in different databases. Recent additions include customizable data quality dimensions, PII/PHI detection for sensitive data classification, and an AI Trust platform that applies runtime enforcement to AI data policies.
If your observability needs span legacy ETL systems alongside modern cloud warehouses, or you need cross-database data quality rules and sensitive data detection, Bigeye covers territory that Monte Carlo and Elementary don’t.
Bigeye: Enterprise Observability Across Modern and Legacy Stacks
Metaplane takes a different approach: self-service observability with minimal setup. Connect your warehouse, BI tool, and dbt repo, and Metaplane’s ML engine starts learning from your metadata and generating alerts within days. No manual thresholds, no engineering effort to configure. It was acquired by Datadog in 2024, positioning it as the bridge between application observability and data observability.
Metaplane provides anomaly detection, column-level lineage, schema change detection, and CI/CD support for dbt (impact previews and regression tests in PRs). It also offers a Snowflake native app that lets you pay with existing Snowflake credits.
Metaplane is optimized for modern cloud stacks. Its integrations cover the core of a typical modern data platform: Snowflake, BigQuery, Redshift, Databricks, Clickhouse, and S3 for warehouses and data lakes; PostgreSQL, MySQL, and SQL Server for transactional databases; Fivetran and Airbyte for ingestion; dbt Core and dbt Cloud for transformation; Airflow for orchestration; Census and Hightouch for reverse ETL; Looker, Tableau, PowerBI, Metabase, Mode, Sigma, and Hex for BI; Slack and Jira for notifications.
The tradeoff is scope. Metaplane doesn't cover legacy ETL systems like Informatica, Talend, or SSIS, and its orchestration support is limited to Airflow. For teams with complex hybrid stacks, Bigeye or Monte Carlo may fit better. For modern cloud-native stacks where fast setup matters more than exhaustive coverage, Metaplane is hard to beat. Pricing starts with a free tier, with team plans scaling based on usage.
Great Expectations: Python-First Data Validation
Great Expectations (GX) is the most widely used open-source Python framework for data validation. It’s not dbt-native and it’s not an observability platform. It’s a standalone validation engine for teams that need to define, execute, and document data quality checks across any Python-accessible data source.
GX Core (open source, Apache 2.0) lets you define “Expectations” (data assertions) and run them against Pandas DataFrames, Spark, or any database supported by SQLAlchemy. Results are rendered as auto-generated “Data Docs,” human-readable HTML documentation of what passed and failed. GX integrates with Airflow, Databricks, Snowflake, BigQuery, Redshift, PostgreSQL, and Microsoft Fabric.
GX Cloud (commercial) adds a web UI for managing expectations without code, scheduled validations, alerting, Data Health dashboards, and ExpectAI, which generates expectations from natural language prompts. Currently ExpectAI supports Snowflake, PostgreSQL, Databricks SQL, and Redshift.
The tradeoff is complexity. GX has a steeper learning curve than Elementary or Soda. Its architecture (DataContext, DataSources, ExpectationSuites, Checkpoints, Stores) requires more setup and conceptual overhead than adding a dbt package or writing SodaCL checks. For teams with strong Python skills who want deep, standalone validation across multiple data sources independent of dbt, it remains a solid choice. For dbt-centric teams, Elementary or Soda will get you to value faster.
How to Choose the Right Combination
The right tooling depends on where your team sits on the data quality maturity curve. A five-person analytics engineering team running 50 dbt models doesn’t need Monte Carlo. A platform team managing hundreds of models across multiple ingestion tools, transformation layers, and BI dashboards probably can’t get by with just Elementary.
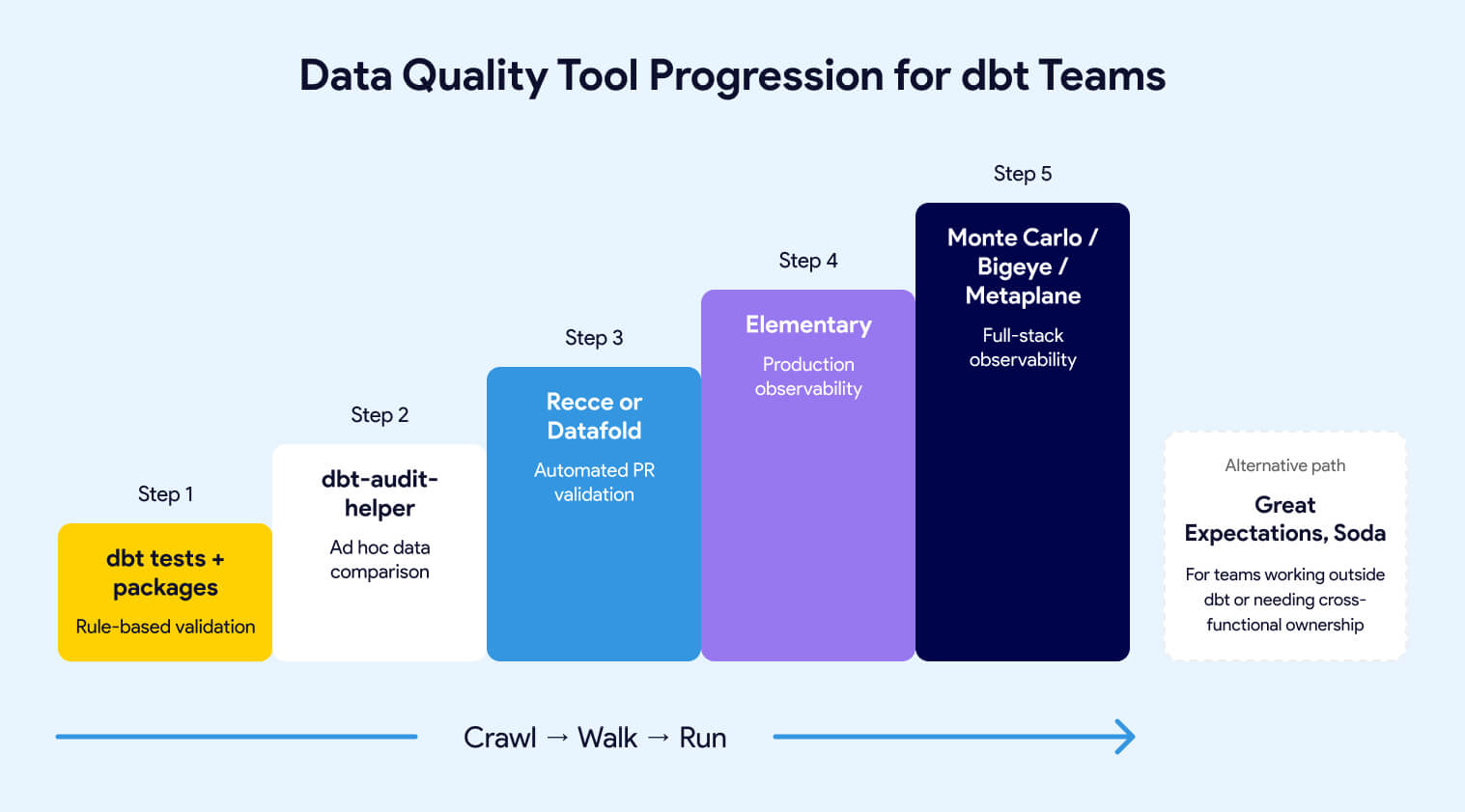
For most dbt teams, the progression looks like this:
Already have dbt tests and packages? Add dbt-audit-helper for ad hoc data comparison when you refactor models or migrate from legacy SQL. It costs nothing and runs inside your project.
Merging dbt changes regularly and want a safety net? Add Recce if you want an open-source, developer-controlled workflow. Choose Datafold if you want fully automated diffing on every PR with lineage into BI tools.
Need to know when production data goes wrong between deploys? Deploy Elementary. It covers anomaly detection, test result history, and alerting with no infrastructure outside your warehouse.
Data quality ownership extends beyond engineering? Evaluate Soda for its human-readable checks and data contracts.
Stack extends well beyond dbt? Evaluate Monte Carlo for ML-based full-stack coverage, Bigeye for hybrid modern/legacy environments, or Metaplane for fast self-service setup on modern stacks.
These tools aren’t mutually exclusive. The strongest data teams typically run two or three: one for pre-production validation, one for production observability, and sometimes a commercial platform on top for cross-stack coverage. The maturity curve gives you the order. Don’t try to run before you’ve learned to walk.
How Datacoves Supports Your Data Quality Stack
Datacoves doesn't bundle or pre-configure any of the tools in this guide. What it does is provide a managed dbt and Airflow environment that's compatible with all of them. If your team already uses Elementary, Soda, Recce, or any other package, Datacoves supports that workflow without getting in the way.
For example, if a client is running Elementary, Datacoves facilitates the continuity of that tool within its environment. The same applies to Recce in CI/CD, dbt-audit-helper in development, or any other dbt package or external integration. Datacoves doesn't own or maintain these tools, but it ensures they work within a governed, orchestrated platform where your team can connect observability data to Airflow DAG runs, version control history, and deployment pipelines.
The value isn't in pre-installing packages. It's in providing the environment where these tools run reliably alongside everything else your data team needs.
What to Take Away
If your dbt project has basic tests in place and you’re still getting surprised by data issues, you don’t need more tests. You need coverage at different points in the lifecycle.
Before merge: start with dbt-audit-helper for ad hoc comparison, then graduate to Recce or Datafold when your team needs automated PR-level validation.
After deployment: Elementary gives you production anomaly detection, test result history, and alerting inside your existing dbt workflow. It’s the lowest-friction path to observability for most teams.
Beyond dbt: if your stack spans ingestion tools, legacy ETL, and BI layers that dbt doesn’t touch, Monte Carlo, Bigeye, and Metaplane provide the cross-stack coverage. Soda and Great Expectations fit teams that need quality ownership or validation logic outside the dbt ecosystem.
The teams that build the most reliable data platforms aren’t the ones running the most tools. They’re the ones that picked the right tools for the right problems at the right stage of their maturity curve.
This guide is the companion to An Overview of Testing Options for dbt. If you haven’t built your test suite yet, start there. The tools in this article are most valuable when they sit on top of a solid testing foundation.
FAQ
How does Recce compare to Datafold?
Both validate the data impact of dbt code changes before merge. Recce is open source with a developer-driven workflow: you run checks, build a validation checklist, and export it to your PR comment. Datafold is a commercial platform that runs automatically on every PR, posts results without manual intervention, and adds column-level lineage extending to BI tools and AI-powered code review. Choose Recce for control and zero cost. Choose Datafold for full automation in CI/CD.
How do these tools work together?
They’re designed for different stages of the data lifecycle and most teams run two or three. A common combination: dbt-audit-helper or Recce for pre-production validation on PRs, Elementary for production anomaly detection and test result history, and optionally a commercial platform like BigEye, Monte Carlo or Metaplane for cross-stack coverage. The right combination depends on your team size, stack complexity, and where you’re losing the most time to data issues.
Should I use Elementary or Soda?
Elementary is the better fit for dbt-centric engineering teams that want observability inside their existing project with minimal setup. Soda is the better fit when data quality ownership needs to extend beyond engineering to analysts and business stakeholders, or when you need a warehouse-agnostic quality layer that works independently of dbt. Soda v4's data contracts and producer/consumer ownership model are its main differentiators. Note that Soda's observability features require Soda Cloud and a Soda Agent; the open-source Soda Core v4 handles contract verification only.
What is Bigeye and how is it different from Monte Carlo?
Bigeye is a commercial data observability platform that differentiates on lineage depth across both modern and legacy data stacks. After acquiring Data Advantage Group, Bigeye offers column-level lineage into ETL platforms like Informatica, Talend, SSIS, and IBM DataStage, which Monte Carlo does not cover as deeply. Bigeye also provides cross-database join rules and PII/PHI detection. Choose Bigeye when your stack includes legacy ETL systems alongside modern cloud warehouses.
What is dbt-audit-helper and when should I use it?
dbt-audit-helper is a free dbt package from dbt Labs that provides macros for comparing two relations or queries. It reports on row matches, column value differences, and schema discrepancies. Use it when you’re refactoring a model, validating a migration, or spot-checking that a logic change didn’t introduce unintended differences. It’s manual and one-model-at-a-time, making it best for ad hoc validation rather than ongoing change management.
What is Elementary and how does it work with dbt?
Elementary is an open-source dbt package that adds production observability directly inside your dbt project. It stores test results history in your warehouse, provides anomaly detection monitors configured in YAML (volume, freshness, schema, distribution), and generates a self-hosted HTML report showing model lineage, test trends, and alerts. It runs as part of your existing dbt workflow with no separate infrastructure.
What is Metaplane?
Metaplane is a self-service data observability platform acquired by Datadog in 2024. It provides ML-powered anomaly detection, column-level lineage from source to BI, and CI/CD support for dbt, with setup that takes minutes rather than days. It's optimized for modern cloud stacks and covers Snowflake, BigQuery, Redshift, Databricks, dbt Core and Cloud, Airflow, Fivetran, Airbyte, and the major BI tools. It doesn't cover legacy ETL systems like Informatica or Talend. Pricing starts with a free tier.
What is the data quality maturity curve?
The data quality maturity curve is a framework for matching your data quality tooling to your organization’s current stage. At the crawl stage, manual inspection and basic dbt tests are sufficient. At the walk stage, you add observability tools like Elementary for automated monitoring. At the run stage, you implement data contracts, governance, and SLAs.
What is the difference between pre-production validation and production observability?
Pre-production validation compares data between your development and production environments during PR review, catching unintended changes before they merge. Production observability monitors your live pipeline continuously, building statistical baselines and alerting you when freshness, volume, schema, or distribution deviate from expected behavior. They solve different problems at different points in the data lifecycle.
What tools go beyond basic dbt tests for data quality?
dbt-audit-helper adds row-by-row and column-by-column comparison between two versions of a model. Recce and Datafold validate the data impact of code changes before they merge to production. Elementary adds anomaly detection and production monitoring as a dbt package. Soda provides human-readable checks that non-engineers can write and maintain. Monte Carlo, Bigeye, and Metaplane offer full-stack observability across data platforms that extend beyond dbt.
When should I consider Monte Carlo over Elementary?
Consider Monte Carlo when your data platform extends well beyond dbt and you need observability across ingestion tools, multiple transformation layers, and BI tools with ML-based anomaly detection that requires no manual configuration. If your team is primarily running dbt workloads and wants warehouse-native observability, Elementary covers the use case at far lower cost and complexity.
Where does Great Expectations fit if I’m already using dbt?
Great Expectations is a Python-first validation framework that runs independently of dbt. It’s not the right choice if you want something that plugs into your dbt workflow directly. But for teams with strong Python skills who need validation across data sources that dbt doesn’t touch (Pandas DataFrames, Spark jobs, non-SQL pipelines), it provides deep, customizable assertion logic. For dbt-centric teams, Elementary or Soda will get you to value faster.






