.png)
The modern data stack promised to simplify everything. Pick best-in-class tools, connect them, and ship insights. The reality for most data teams looks different: months spent configuring Kubernetes, debugging Airflow dependencies, and managing Python environments before a single pipeline runs in production. Who manages the infrastructure around those tools matters more than which tools you pick.
This article breaks down the build vs. buy decision for the two tools at the core of every modern data platform: dbt Core for transformation and Apache Airflow for orchestration. Both are open source. Both are powerful. And both are significantly harder and more expensive to self-host than most teams anticipate.
In the context of the modern data stack, this decision is not about building software from scratch. dbt Core and Apache Airflow already exist. They are battle-tested, open source, and free to use under permissive licenses.
The real question is: who manages the infrastructure that makes them run in production?
Building means your team owns the infrastructure. You provision and manage Kubernetes clusters, configure Git sync for DAGs, handle Python virtual environments, manage secrets, set up CI/CD pipelines, and keep everything running as tools release new versions. The tools are free. The operational burden is not.
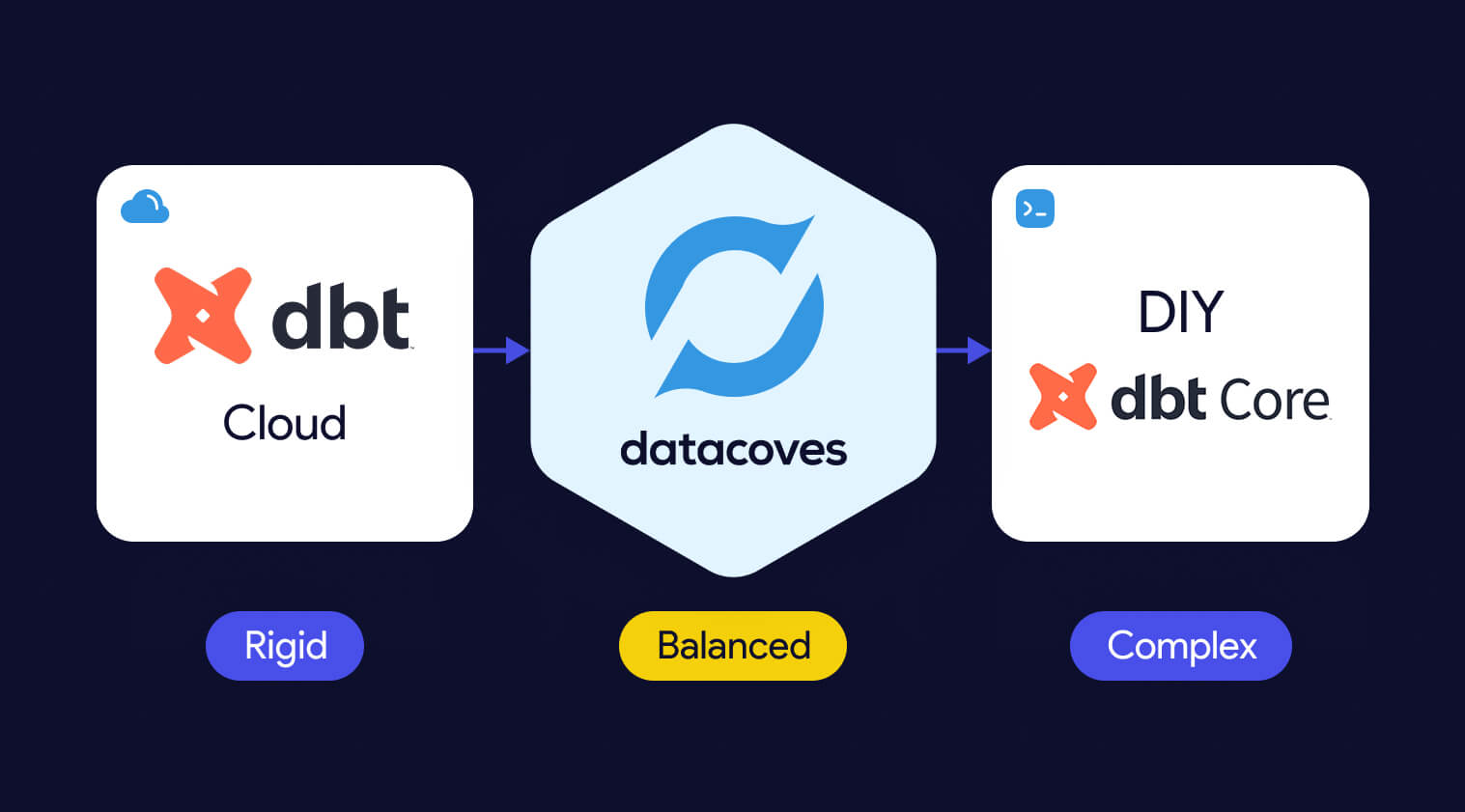
Buying means a managed platform handles that infrastructure for you. Vendors like dbt Cloud, MWAA, Astronomer, and Datacoves build on top of the open-source foundation and manage the environment so your team does not have to. For a detailed feature comparison, see dbt Core vs dbt Cloud. You trade some control for significantly less operational overhead. The key word is "some," the best managed platforms give up very little flexibility while eliminating most of the burden.
This begs the important question: Should you self-manage or pay for your open-source analytics tools?
Both options have legitimate strengths. The right call depends on your team's size, technical depth, compliance requirements, and how much platform maintenance you can absorb without slowing down delivery. Here is a look at each.
The primary argument for building is control. Your team owns every configuration decision: how secrets are stored, how DAGs are synced, how environments are structured, and how tools integrate with your existing systems. For organizations with specialized workflows that no managed platform supports, this matters.
The tradeoff is real and significant. A production-grade Airflow deployment on Kubernetes requires deep DevOps expertise. You will spend weeks on initial setup before writing a single DAG. Ongoing maintenance, dependency management, version upgrades, and security hardening become a permanent part of your team's workload. And when the engineer who built it leaves, that institutional knowledge walks out the door.
Building also means your team is running version 1 of your own platform. Edge cases, security gaps, and scaling issues will surface in production. That is not a risk with a managed solution that has been hardened across many enterprise deployments.
Managed platforms eliminate the infrastructure burden so your team can focus on what actually drives business value: building data models, delivering pipelines, and getting insights to stakeholders faster.
The common concern is flexibility. Many managed platforms lock you into standardized workflows, limit your tool choices, or make migration difficult. That concern is valid for some vendors, not the category as a whole. The right question is not "build or buy" but "which managed platform gives us the control we need without the overhead we do not want.
A well-chosen managed platform gets your team writing and running code in days, not months. It handles upgrades, secrets management, CI/CD scaffolding, and environment consistency. And unlike version 1 of your homegrown solution, it has already solved the edge cases you have not encountered yet.
Open source looks free the way a free puppy looks free. The license costs nothing. Everything that comes after it does. For most data teams, self-hosting dbt Core and Airflow on Kubernetes carries high hidden costs in engineering time alone, before infrastructure spend.
For dbt and Airflow, the real costs fall into three categories: engineering time, security and compliance, and scaling complexity. Most teams underestimate all three.
Before diving into each category, here is what self-hosting dbt Core and Airflow actually costs your team:
.svg)
Setting up a production-grade Airflow environment on Kubernetes is not a weekend project. Teams routinely spend weeks configuring DAG sync via Git or S3, managing Python virtual environments, wiring up secrets management, and debugging dependency conflicts before anything runs reliably.
Then there is the ongoing cost. Upgrades, incident response, onboarding new engineers, and keeping the environment consistent across developers all consume time that could be spent delivering data products. A senior data engineer earns between $126,000 and $173,000 per year (Glassdoor, ZipRecruiter). For a team of two to four engineers spending 25 to 50 percent of their time on platform management, that's $5,250 to $28,830 per month in engineering costs alone, before a dollar of infrastructure spend. And that's assuming no one leaves. For a deeper breakdown of what these tools actually cost to run, see what open source analytics tools really cost.
A managed platform can have your team writing and running code in days. Datacoves helped J&J set up their data stack in weeks, with full visibility and automation from day one.
With open-source tools, your team is responsible for implementing security best practices from the ground up. Secrets management, credential rotation, SSO integration, audit logging, and network isolation do not come preconfigured. Each one requires research, implementation, and ongoing maintenance.
For regulated industries like healthcare, finance, or government, compliance requirements add another layer. Meeting HIPAA, SOX, or internal governance standards through a self-managed stack is a process of iteration and refinement. Every hour spent here is an hour not spent on data products, and every gap is a potential audit finding.
Scaling a self-hosted Airflow deployment means scaling your Kubernetes expertise alongside it. As DAG count grows, as team size increases, and as pipeline complexity compounds, the operational surface area expands. Memory issues, worker contention, and environment drift become recurring problems.
Extended downtime at scale is not just an engineering problem. Business users who depend on fresh data feel it directly. The hidden cost is not just the engineering hours spent fixing it. It is the trust lost with stakeholders when the data is late or wrong.
The strongest argument for a managed platform is compounding speed, not convenience.
Every week your team spends managing infrastructure is a week not spent building data products. That gap compounds. A team that gets into production in days instead of months delivers more value, builds more trust with stakeholders, and develops faster than one still debugging Kubernetes configurations three months in.
Managed platforms handle the infrastructure layer your team should not be owning: upgrades, secrets management, environment consistency, CI/CD scaffolding, and scaling. What used to take months of setup is available on day one. And because you are running a platform that has been hardened across many enterprise deployments, the edge cases have already been solved.
The reliability argument matters too. Your homegrown solution is version 1. A mature managed platform is version 1,000. The difference shows up in production at the worst possible times.
The most common objection to buying is vendor lock-in. It is a legitimate concern, and it applies to some platforms more than others.
The risk is real when a managed platform abstracts away the underlying tools with a proprietary layer, when you do not own your code and metadata, or when switching providers requires a full rebuild. Some vendors in this space do exactly that.
The risk is low when the platform is built on open-source tooling at the core, when you retain full ownership of your code, models, and DAGs, and when the architecture is designed to be warehouse and tool agnostic. Before signing with any vendor, ask three questions: Can I see the underlying dbt Core and Airflow configurations? Do I own everything I build? Can I swap components as my stack evolves?
If the answers are yes, lock-in is not the risk. Slow delivery is.
Pipeline orchestration and transformation do not exist in isolation. For a deeper look at how dbt and Airflow work together as a unified pair, see dbt and Airflow: The Natural Pair for Data Analytics.
Not all managed platforms are built for enterprise complexity. Some are designed for fast starts, not long-term scale. The most common failure modes are rigid workflow standardization that does not match how your team actually works, SaaS-only deployment that cannot meet strict data sovereignty requirements, and limited support once the contract is signed.
MWAA, for example, manages Airflow infrastructure but still requires significant configuration to integrate with dbt and handle memory issues at scale. dbt Cloud covers the transformation layer well but uses per-seat pricing that scales steeply for larger teams and does not address orchestration. Neither covers the full data engineering lifecycle in a unified environment.
The right managed platform gives your tools a proper home.
Datacoves was designed so you don't have to sacrifice.
Datacoves is an end-to-end data engineering platform that runs entirely inside your cloud, under your security controls, and adapts to the tools your team already uses. It manages the infrastructure layer so your team does not have to, without locking you into a rigid workflow or a proprietary toolchain.
Every developer gets the same consistent workspace from day one: in-browser VS Code, dbt Core, Python virtual environments, Git integration, CI/CD pipelines, and secrets management, all preconfigured and aligned to best practices. There is no weeks-long setup. There is no "figure it out yourself" onboarding. Your team opens the environment and everything works.
Managed Airflow covers both development and production. My Airflow gives individual developers a personal sandbox for fast iteration. Teams Airflow handles shared production orchestration, with DAG syncing from Git, built-in dbt operators, and simplified retry logic. Troubleshooting across the full pipeline, from ingestion through transformation to deployment, happens in one place.
Datacoves is warehouse agnostic. It works with Snowflake, Databricks, BigQuery, Redshift, DuckDB, and any database with a dbt adapter. It supports dbt Mesh for multi-project, multi-team setups. It integrates with your existing identity provider, logging systems, and ingestion tools. You bring what you have. Datacoves manages the rest.
Unlike dbt Cloud, which is locked to its own runtime and per-seat pricing, or MWAA, which still requires significant configuration work, Datacoves covers the full data engineering lifecycle in a single environment. And because it is built entirely on open-source tooling, there is no proprietary layer trapping your code or your team.
For security-conscious and regulated organizations, Datacoves is the only managed platform in this category that can be deployed entirely within your private cloud account. Your data never leaves your environment. No VPC peering required. No external access to internal resources. Full SSO and role-based access integration with your existing security controls.
This is the difference between a platform that asks you to trust their security and one that puts security entirely in your hands. For teams in healthcare, finance, pharma, or government, that distinction is not a nice-to-have. It is a requirement.
Beyond infrastructure, Datacoves brings a proven architecture foundation. Branching standards, CI/CD enforcement, secrets management patterns, deployment guardrails, and onboarding templates are all pre-baked into the platform. Your team does not need to research and implement best practices from scratch. They inherit them on day one.
Dedicated onboarding, a Resident Solutions Architect on call, and white-glove support mean that best practices do not stay with the champion who led the evaluation. They spread across the whole team. Most tool purchases don't change how a team works. This one does.
Standardized environments and templates reduce onboarding time significantly. Guitar Center onboarded in days, not months, with their full data stack running on Datacoves from the start.
The build vs. buy question is really a resource allocation question. What should your team own, and what should be managed for you?
The answer for most data teams is clear. Own your data models, your business logic, your stakeholder relationships and your architecture decisions. Do not own Kubernetes clusters, Airflow upgrades, and CI/CD pipeline scaffolding. That work consumes engineering time without delivering business value, and it compounds the longer you wait to address it.
As Joe Reis and Matt Housley argue in Fundamentals of Data Engineering, data teams should prioritize extracting value from data rather than managing the tools that support them. The teams that move fastest are not the ones who built the most. They are the ones who made smart decisions about what not to build.
Open source isn't free, and self-hosting is harder than it looks. And the gap between a working proof of concept and a production-grade, secure, scalable data platform is wider than most teams expect until they are already in it.
Datacoves closes that gap. It gives your team the flexibility of a custom build, the reliability of a mature platform, and the security of a private cloud deployment, without the operational burden that makes building so expensive. Your team focuses on data products. Datacoves handles everything underneath them.
If your team is spending more time managing infrastructure than building pipelines, that’s the signal. See Datacoves in action and discover how teams simplify their data platform so they can focus on building, not maintaining.

The top dbt alternatives include Datacoves, SQLMesh, Bruin Data, Dataform, and visual ETL tools such as Alteryx, Matillion, and Informatica. Code-first engines offer stronger rigor, testing, and CI/CD, while GUI platforms emphasize ease of use and rapid prototyping. Teams choose these alternatives when they need more security, governance, or flexibility than dbt Core or dbt Cloud provide.
The top dbt alternatives include Datacoves, SQLMesh, Bruin Data, Dataform, and GUI-based ETL tools such as Alteryx, Matillion, and Informatica.
Teams explore dbt alternatives when they need stronger governance, private deployments, or support for Python and code-first workflows that go beyond SQL. Many also prefer GUI-based ETL tools for faster onboarding. Recent market consolidation, including Fivetran acquiring SQLMesh and merging with dbt Labs, has increased concerns about vendor lock-in, which makes tool neutrality and platform flexibility more important than ever.
Teams look for dbt alternatives when they need stronger orchestration, consistent development environments, Python support, or private cloud deployment options that dbt Cloud does not provide.
Organizations evaluating dbt alternatives typically compare tools across three categories. Each category reflects a different approach to data transformation, development preferences, and organizational maturity.
Organizations consider alternatives to dbt Cloud when they need more flexibility, stronger security, or support for development workflows that extend beyond dbt. Teams comparing platform options often begin by evaluating the differences between dbt Cloud vs dbt Core.
Running enterprise-scale ELT pipelines often requires a full orchestration layer, consistent development environments, and private deployment options that dbt Cloud does not provide. Costs can also increase at scale (see our breakdown of dbt pricing considerations), and some organizations prefer to avoid features that are not open source to reduce long-term vendor lock-in.
This category includes platforms that deliver the benefits of dbt Cloud while providing more control, extensibility, and alignment with enterprise data platform requirements.
Datacoves provides a secure, flexible platform that supports dbt, SQLMesh, and Bruin in a unified environment with private cloud or VPC deployment.
Datacoves is an enterprise data platform that serves as a secure, flexible alternative to dbt Cloud. It supports dbt Core, SQLMesh, and Bruin inside a unified development and orchestration environment, and it can be deployed in your private cloud or VPC for full control over data access and governance.
Benefits
Flexibility and Customization:
Datacoves provides a customizable in-browser VS Code IDE, Git workflows, and support for Python libraries and VS Code extensions. Teams can choose the transformation engine that fits their needs without being locked into a single vendor.
Handling Enterprise Complexity:
Datacoves includes managed Airflow for end-to-end orchestration, making it easy to run dbt and Airflow together without maintaining your own infrastructure. It standardizes development environments, manages secrets, and supports multi-team and multi-project workflows without platform drift.
Cost Efficiency:
Datacoves reduces operational overhead by eliminating the need to maintain separate systems for orchestration, environments, CI, logging, and deployment. Its pricing model is predictable and designed for enterprise scalability.
Data Security and Compliance:
Datacoves can be deployed fully inside your VPC or private cloud. This gives organizations complete control over identity, access, logging, network boundaries, and compliance with industry and internal standards.
Reduced Vendor Lock-In:
Datacoves supports dbt, SQLMesh, and Bruin Data, giving teams long-term optionality. This avoids being locked into a single transformation engine or vendor ecosystem.
Running dbt Core yourself is a flexible option that gives teams full control over how dbt executes. It is also the most resource-intensive approach. Teams choosing DIY dbt Core must manage orchestration, scheduling, CI, secrets, environment consistency, and long-term platform maintenance on their own.
Benefits
Full Control:
Teams can configure dbt Core exactly as they want and integrate it with internal tools or custom workflows.
Cost Flexibility:
There are no dbt Cloud platform fees, but total cost of ownership often increases as the system grows.
Considerations
High Maintenance Overhead:
Teams must maintain Airflow or another orchestrator, build CI pipelines, manage secrets, and keep development environments consistent across users.
Requires Platform Engineering Skills:
DIY dbt Core works best for teams with strong Kubernetes, CI, Python, and DevOps expertise. Without this expertise, the environment becomes fragile over time.
Slow to Scale:
As more engineers join the team, keeping dbt environments aligned becomes challenging. Onboarding, upgrades, and platform drift create operational friction.
Security and Compliance Responsibility:
Identity, permissions, logging, and network controls must be designed and maintained internally, which can be significant for regulated organizations.
Teams that prefer code-first tools often look for dbt alternatives that provide strong SQL modeling, Python support, and seamless integration with CI/CD workflows and automated testing. These are part of a broader set of data transformation tools. Code-based ETL tools give developers greater control over transformations, environments, and orchestration patterns than GUI platforms. Below are four code-first contenders that organizations should evaluate.
Code-first dbt alternatives like SQLMesh, Bruin Data, and Dataform provide stronger CI/CD integration, automated testing, and more control over complex transformation workflows.
SQLMesh is an open-source framework for SQL and Python-based data transformations. It provides strong visibility into how changes impact downstream models and uses virtual data environments to preview changes before they reach production. SQLMesh was originally developed by Tobiko Data, acquired by Fivetran in 2025, and donated to the Linux Foundation in March 2026.
Benefits
Efficient Development Environments:
Virtual environments reduce unnecessary recomputation and speed up iteration.
Community Governance Under the Linux Foundation:
In March 2026, Fivetran contributed SQLMesh to the Linux Foundation, establishing an open community governance model. Founding members including Benzinga, CloudKitchens, Harness, and others joined to support its ongoing development. The project remains publicly available on GitHub, which increases its neutrality and long-term independence from any single vendor.
Considerations
Governance Is New:
While Linux Foundation stewardship is a positive signal for openness, the community governance model is still in its early stages. It remains to be seen how active and independent the contributor community will become over time.
Dataform is a SQL-based transformation framework focused specifically for BigQuery. It enables teams to create table definitions, manage dependencies, document models, and configure data quality tests inside the Google Cloud ecosystem. It also provides version control and integrates with GitHub and GitLab.
Benefits
Centralized BigQuery Development:
Dataform keeps all modeling and testing within BigQuery, reducing context switching and making it easier for teams to collaborate using familiar SQL workflows.
Considerations
Focused Only on the GCP Ecosystem:
Because Dataform is geared toward BigQuery, it may not be suitable for organizations that use multiple cloud data warehouses.
AWS Glue is a serverless data integration service that supports Python-based ETL and transformation workflows. It works well for organizations operating primarily in AWS and provides native integration with services like S3, Lambda, and Athena.
Benefits
Python-First ETL in AWS:
Glue supports Python scripts and PySpark jobs, making it a good fit for engineering teams already invested in the AWS ecosystem.
Considerations
Requires Engineering Expertise:
Glue can be complex to configure and maintain, and its Python-centric approach may not be ideal for SQL-first analytics teams.
Bruin is a modern SQL-based data modeling framework designed to simplify development, testing, and environment-aware deployments. It offers a familiar SQL developer experience while adding guardrails and automation to help teams manage complex transformation logic.
Benefits
Modern SQL Modeling Experience:
Bruin provides a clean SQL-first workflow with strong dependency management and testing.
Considerations
Growing Ecosystem:
Bruin is newer than dbt and has a smaller community and fewer third-party integrations.
While code-based transformation tools provide the most flexibility and long-term maintainability, some organizations prefer graphical user interface (GUI) tools. These platforms use visual, drag-and-drop components to build data integration and transformation workflows. Many of these platforms fall into the broader category of no-code ETL tools. GUI tools can accelerate onboarding for teams less comfortable with code editors and may simplify development in the short term. Below are several GUI-based options that organizations often consider as dbt alternatives.
GUI-based dbt alternatives such as Matillion, Informatica, and Alteryx use drag-and-drop interfaces that simplify development and accelerate onboarding for mixed-skill teams.
Matillion is a cloud-based data integration platform that enables teams to design ETL and transformation workflows through a visual, drag-and-drop interface. It is built for ease of use and supports major cloud data warehouses such as Amazon Redshift, Google BigQuery, and Snowflake.
Benefits
User-Friendly Visual Development:
Matillion simplifies pipeline building with a graphical interface, making it accessible for users who prefer low-code or no-code tooling.
Considerations
Limited Flexibility for Complex SQL Modeling:
Matillion’s visual approach can become restrictive for advanced transformation logic or engineering workflows that require version control and modular SQL development.
Informatica is an enterprise data integration platform with extensive ETL capabilities, hundreds of connectors, data quality tooling, metadata-driven workflows, and advanced security features. It is built for large and diverse data environments.
Benefits
Enterprise-Scale Data Management:
Informatica supports complex data integration, governance, and quality requirements, making it suitable for organizations with large data volumes and strict compliance needs.
Considerations
High Complexity and Cost:
Informatica’s power comes with a steep learning curve, and its licensing and operational costs can be significant compared to lighter-weight transformation tools.
Alteryx is a visual analytics and data preparation platform that combines data blending, predictive modeling, and spatial analysis in a single GUI-based environment. It is designed for analysts who want to build workflows without writing code and can be deployed on-premises or in the cloud.
Benefits
Powerful GUI Analytics Capabilities:
Alteryx allows users to prepare data, perform advanced analytics, and generate insights in one tool, enabling teams without strong coding skills to automate complex workflows.
Considerations
High Cost and Limited SQL Modeling Flexibility:
Alteryx is one of the more expensive platforms in this category and is less suited for SQL-first transformation teams who need modular modeling and version control.
Azure Data Factory (ADF) is a fully managed, serverless data integration service that provides a visual interface for building ETL and ELT pipelines. It integrates natively with Azure storage, compute, and analytics services, allowing teams to orchestrate and monitor pipelines without writing code.
Benefits
Strong Integration for Microsoft-Centric Teams:
ADF connects seamlessly with other Azure services and supports a pay-as-you-go model, making it ideal for organizations already invested in the Microsoft ecosystem.
Considerations
Limited Transformation Flexibility:
ADF excels at data movement and orchestration but offers limited capabilities for complex SQL modeling, making it less suitable as a primary transformation engine
Talend provides an end-to-end data management platform with support for batch and real-time data integration, data quality, governance, and metadata management. Talend Data Fabric combines these capabilities into a single low-code environment that can run in cloud, hybrid, or on-premises deployments.
Benefits
Comprehensive Data Quality and Governance:
Talend includes built-in tools for data cleansing, validation, and stewardship, helping organizations improve the reliability of their data assets.
Considerations
Broad Platform, Higher Operational Complexity:
Talend’s wide feature set can introduce complexity, and teams may need dedicated expertise to manage the platform effectively.
SQL Server Integration Services is part of the Microsoft SQL Server ecosystem and provides data integration and transformation workflows. It supports extracting, transforming, and loading data from a wide range of sources, and offers graphical tools and wizards for designing ETL pipelines.
Benefits
Strong Fit for SQL Server-Centric Teams:
SSIS integrates deeply with SQL Server and other Microsoft products, making it a natural choice for organizations with a Microsoft-first architecture.
Considerations
Not Designed for Modern Cloud Data Warehouses:
SSIS is optimized for on-premises SQL Server environments and is less suitable for cloud-native architectures or modern ELT workflows.
Recent consolidation, including Fivetran acquiring SQLMesh and merging with dbt Labs, has increased concerns about vendor lock-in and pushed organizations to evaluate more flexible transformation platforms.
Organizations explore dbt alternatives when dbt no longer meets their architectural, security, or workflow needs. As teams scale, they often require stronger orchestration, consistent development environments, mixed SQL and Python workflows, and private deployment options that dbt Cloud does not provide.
Some teams prefer code-first engines for deeper CI/CD integration, automated testing, and strong guardrails across developers. Others choose GUI-based tools for faster onboarding or broader integration capabilities. Recent market consolidation, including Fivetran acquiring SQLMesh and merging with dbt Labs, has also increased concerns about vendor lock-in.
These factors lead many organizations to evaluate tools that better align with their governance requirements, engineering preferences, and long-term strategy.
DIY dbt Core offers full control but requires significant engineering work to manage orchestration, CI/CD, security, and long-term platform maintenance.
Running dbt Core yourself can seem attractive because it offers full control and avoids platform subscription costs. However, building a stable, secure, and scalable dbt environment requires significantly more than executing dbt build on a server. It involves managing orchestration, CI/CD, and ensuring development environment consistency along with long-term platform maintenance, all of which require mature DataOps practices.
The true question for most organizations is not whether they can run dbt Core themselves, but whether it is the best use of engineering time. This is essentially a question of whether to build vs buy your data platform. DIY dbt platforms often start simple and gradually accumulate technical debt as teams grow, pipelines expand, and governance requirements increase.
For many organizations, DIY works in the early stages but becomes difficult to sustain as the platform matures.
The right dbt alternative depends on your team’s skills, governance requirements, pipeline complexity, and long-term data platform strategy.
Selecting the right dbt alternative depends on your team’s skills, security requirements, and long-term data platform strategy. Each category of tools solves different problems, so it is important to evaluate your priorities before committing to a solution.
If these are priorities, a platform with secure deployment options or multi-engine support may be a better fit than dbt Cloud.
Recent consolidation in the ecosystem has raised concerns about vendor dependency. Organizations that want long-term flexibility often look for:
Consider platform fees, engineering maintenance, onboarding time, and the cost of additional supporting tools such as orchestrators, IDEs, and environment management
dbt remains a strong choice for SQL-based transformations, but it is not the only option. As organizations scale, they often need stronger orchestration, consistent development environments, Python support, and private deployment capabilities that dbt Cloud or DIY dbt Core may not provide. Evaluating alternatives helps ensure that your transformation layer aligns with your long-term platform and governance strategy.
Code-first tools like SQLMesh, Bruin Data, and Dataform offer strong engineering workflows, while GUI-based tools such as Matillion, Informatica, and Alteryx support faster onboarding for mixed-skill teams. The right choice depends on the complexity of your pipelines, your team’s technical profile, and the level of security and control your organization requires.
Datacoves provides a flexible, secure alternative that supports dbt, SQLMesh, and Bruin in a unified environment. With private cloud or VPC deployment, managed Airflow, and a standardized development experience, Datacoves helps teams avoid vendor lock-in while gaining an enterprise-ready platform for analytics engineering.
Selecting the right dbt alternative is ultimately about aligning your transformation approach with your data architecture, governance needs, and long-term strategy. Taking the time to assess these factors will help ensure your platform remains scalable, secure, and flexible for your future needs.

Any experienced data engineer will tell you that efficiency and resource optimization are always top priorities. One powerful feature that can significantly optimize your dbt CI/CD workflow is dbt Slim CI. However, despite its benefits, some limitations have persisted. Fortunately, the recent addition of the --empty flag in dbt 1.8 addresses these issues. In this article, we will share a GitHub Action Workflow and demonstrate how the new --empty flag can save you time and resources.
dbt Slim CI is designed to make your continuous integration (CI) process more efficient by running only the models that have been changed and their dependencies, rather than running all models during every CI build. In large projects, this feature can lead to significant savings in both compute resources and time.
dbt Slim CI is implemented efficiently using these flags:
--select state:modified: The state:modified selector allows you to choose the models whose "state" has changed (modified) to be included in the run/build. This is done using the state:modified+ selector which tells dbt to run only the models that have been modified and their downstream dependencies.
--state <path to production manifest>: The --state flag specifies the directory where the artifacts from a previous dbt run are stored ie) the production dbt manifest. By comparing the current branch's manifest with the production manifest, dbt can identify which models have been modified.
--defer: The --defer flag tells dbt to pull upstream models that have not changed from a different environment (database). Why rebuild something that exists somewhere else? For this to work, dbt will need access to the dbt production manifest.

You may have noticed that there is an additional flag in the command above.
--fail-fast: The --fail-fast flag is an example of an optimization flag that is not essential to a barebones Slim CI but can provide powerful cost savings. This flag stops the build as soon as an error is encountered instead of allowing dbt to continue building downstream models, therefore reducing wasted builds. To learn more about these arguments you can use have a look at our dbt cheatsheet.
The following sample Github Actions workflow below is executed when a Pull Request is opened. ie) You have a feature branch that you want to merge into main.

Checkout Branch: The workflow begins by checking out the branch associated with the pull request to ensure that the latest code is being used.
Set Secure Directory: This step ensures the repository directory is marked as safe, preventing potential issues with Git operations.
List of Files Changed: This command lists the files changed between the PR branch and the base branch, providing context for the changes and helpful for debugging.
Install dbt Packages: This step installs all required dbt packages, ensuring the environment is set up correctly for the dbt commands that follow.
Create PR Database: This step creates a dedicated database for the PR, isolating the changes and tests from the production environment.
Get Production Manifest: Retrieves the production manifest file, which will be used for deferred runs and governance checks in the following steps.
Run dbt Build in Slim Mode or Run dbt Build Full Run: If a manifest is present in production, dbt will be run in slim mode with deferred models. This build includes only the modified models and their dependencies. If no manifest is present in production we will do a full refresh.
Grant Access to PR Database: Grants the necessary access to the new PR database for end user review.
Generate Docs Combining Production and Branch Catalog: If a dbt test is added to a YAML file, the model will not be run, meaning it will not be present in the PR database. However, governance checks (dbt-checkpoint) will need the model in the database for some checks and if not present this will cause a failure. To solve this, the generate docs step is added to merge the catalog.json from the current branch with the production catalog.json.
Run Governance Checks: Executes governance checks such as SQLFluff and dbt-checkpoint.
As mentioned in the beginning of the article, there is a limitation to this setup. In the existing workflow, governance checks need to run after the dbt build step. This is because dbt-checkpoint relies on the manifest.json and catalog.json. However, if these governance checks fail, it means that the dbt build step will need to run again once the governance issues are fixed. As shown in the diagram below, after running our dbt build, we proceed with governance checks. If these checks fail, we need to resolve the issue and re-trigger the pipeline, leading to another dbt build. This cycle can lead to unnecessary model builds even when leveraging dbt Slim CI.

The solution to this problem is the --empty flag in dbt 1.8. This flag allows dbt to perform schema-only dry runs without processing large datasets. It's like building the wooden frame of a house—it sets up the structure, including the metadata needed for governance checks, without filling it with data. The framework is there, but the data itself is left out, enabling you to perform governance checks without completing an actual build.
Let’s see how we can rework our Github Action:

Checkout Branch: The workflow begins by checking out the branch associated with the pull request to ensure that the latest code is being used.
Set Secure Directory: This step ensures the repository directory is marked as safe, preventing potential issues with Git operations.
List of Files Changed: This step lists the files changed between the PR branch and the base branch, providing context for the changes and helpful for debugging.
Install dbt Packages: This step installs all required dbt packages, ensuring the environment is set up correctly for the dbt commands that follow.
Create PR Database: This command creates a dedicated database for the PR, isolating the changes and tests from the production environment.
Get Production Manifest: Retrieves the production manifest file, which will be used for deferred runs and governance checks in the following steps.
*NEW* Governance Run of dbt (Slim or Full) with EMPTY Models: If there is a manifest in production, this step runs dbt with empty models using slim mode and using the empty flag. The models will be built in the PR database with no data inside and we can now use the catalog.json to run our governance checks since the models. Since the models are empty and we have everything we need to run our checks, we have saved on compute costs as well as run time.
Generate Docs Combining Production and Branch Catalog: If a dbt test is added to a YAML file, the model will not be run, meaning it will not be present in the PR database. However, governance checks (dbt-checkpoint) will need the model in the database for some checks and if not present this will cause a failure. To solve this, the generate docs step is added to merge the catalog.json from the current branch with the production catalog.json.
Run Governance Checks: Executes governance checks such as SQLFluff and dbt-checkpoint.
Run dbt Build: Runs dbt build using either slim mode or full run after passing governance checks.
Grant Access to PR Database: Grants the necessary access to the new PR database for end user review.
By leveraging the dbt --empty flag, we can materialize models in the PR database without the computational overhead, as the actual data is left out. We can then use the metadata that was generated during the empty build. If any checks fail, we can repeat the process again but without the worry of wasting any computational resources doing an actual build. The cycle still exists but we have moved our real build outside of this cycle and replaced it with an empty or fake build. Once all governance checks have passed, we can proceed with the real dbt build of the dbt models as seen in the diagram below.

dbt Slim CI is a powerful addition to the dbt toolkit, offering significant benefits in terms of speed, resource savings, and early error detection. However, we still faced an issue of wasted models when it came to failing governance checks. By incorporating dbt 1.8’s --empty flag into your CI/CD workflows we can reduce wasted model builds to zero, improving the efficiency and reliability of your data engineering processes.
🔗 Watch the vide where Noel explains the --empty flag implementation in Github Actions:

Jinja templating in dbt offers flexibility and expressiveness that can significantly improve SQL code organization and reusability. There is a learning curve, but this cheat sheet is designed to be a quick reference for data practitioners, helping to streamline the development process and reduce common pitfalls.
Whether you're troubleshooting a tricky macro or just brushing up on syntax, bookmark this page. Trust us, it will come in handy and help you unlock the full potential of Jinja in your dbt projects.
If you find this cheat sheet useful, be sure to check out our Ultimate dbt Jinja Functions Cheat Sheet. It covers the specialized Jinja functions created by dbt, designed to enhance versatility and expedite workflows.
This is the foundational syntax of Jinja, from how to comment to the difference between statements and expressions.
Define and assign variables in different data types such as strings, lists, and dictionaries.
Jinja allows fine-grained control over white spaces in compiled output. Understand how to strategically strip or maintain spaces.
In dbt, conditional structures guide the flow of transformations. Grasp how to integrate these structures seamlessly.
Discover how to iterate over lists and dictionaries. Understand simple loop syntax or accessing loop properties.
These logical and comparison operators come in handy, especially when defining tests or setting up configurations in dbt.
Within dbt, you may need to validate if a variable is defined or a if a value is odd or even. These Jinja Variable tests allow you to validate with ease.
Macros are the backbone of advanced dbt workflows. Review how to craft these reusable code snippets and also how to enforce data quality with tests.
Fine-tune your dbt data models with these transformation and formatting utilities.
Please contact us with any errors or suggestions.

Implementing dbt (data build tool) can revolutionize your organization's data maturity, however, if your organization is not ready to take advantage of the benefits of dbt it might not be the right time to start. Why? Because the success of data initiatives often hinges on aspects beyond the tooling itself.
Many companies rush into implementing dbt without assessing their organization’s maturity and this leads to poor implementation. The consequences that come from a poorly implemented dbt initiative can leave the organization frustrated, overwhelmed with technical debt, and wasted resources. To avoid these pitfalls and ensure your organization is truly ready for dbt, you should complete an assessment of your organization's readiness by answering the questions presented later in this article.
Before diving into the maturity assessment questions, it’s important to understand what data maturity means. Data maturity is the extent to which an organization can effectively leverage its data to drive business value. It encompasses multiple areas, including:
Data-Driven Culture: Fostering an environment where data is integral to decision-making processes.
Data Quality: Ensuring data is accurate, consistent, and reliable.
Data Governance: Implementing policies and procedures to manage data assets.
Data Integration: Seamlessly combining data from various sources for a unified view.
A mature data organization not only ensures data accuracy and consistency but also embeds data-driven decision-making into its core operations.
By leveraging dbt's features, organizations can significantly enhance their data maturity, leading to better decision-making, improved data quality, robust governance, and seamless integration. For example:

Data-Driven Culture: By using dbt, you can improve many aspects that contribute to creating a data-driven culture within an organization. One way is by encouraging business users to be involved in providing or reviewing accurate model and column descriptions which are embedded in dbt. You can also involve them in defining what data to test with dbt. Better Data Quality will improve trust in the data. More trust in the data will always lead to more frequent use and reliance on it.
Data Quality and Observability: dbt enables automated testing and validation of data transformations. This ensures data quality by catching issues like schema changes or data anomalies early in the pipeline. As your data quality and data observability needs grow you can assess where you are on the data maturity curve. For example, in a sales data model, we can write tests to ensure there are no negative order quantities and that each order has a valid customer ID. With dbt you can also understand data lineage and this can improve impact and root cause analysis when insights don’t seem quite right.
Data Governance: dbt facilitates version control and documentation for all transformations, enhancing transparency and accountability. Organizations can track changes to data models ensuring compliance with data governance policies.
Data Integration: dbt supports the integration of data from multiple sources by providing a framework for consistent and reusable transformations. This allows for the creation of unified data models that provide a holistic view of business operations.
Now that we understand what data maturity is and how dbt can help improve it, you might be ready to jump on the dbt bandwagon. But first, we encourage you to assess your organization’s readiness for dbt. The journey to data maturity involves not only choosing the right tools but also ensuring that your organization is philosophically and operationally prepared to take full advantage of these tools. It is important to recognize that dbt’s approach requires a shift in mindset towards modern data practices, emphasizing transparency, collaboration, and automation.
To determine if your organization is mature enough for dbt or if dbt is the right fit, consider the following assessment questions:
dbt requires a philosophical alignment with its principles, such as ELT (Extract, Load, Transform) instead of the traditional ETL (Extract, Transform, Load) approach. dbt is also based on idempotency meaning that given the same input, you will always get the same output. This is different than traditional ETL that may use incompatible constructs like Auto-Incrementing Primary Keys. If your organization prefers processes that are incompatible with dbt’s methodology, you will face challenges fighting the dbt framework to make it do something it was not intended to do.
Simply migrating existing processes and code to dbt without rethinking them won’t leverage dbt’s full potential. Assess whether you’re ready to redesign your workflows to take advantage of dbt’s capabilities such as incremental tables, snapshots, seeds, etc.
dbt offers excellent features for data quality and documentation. Evaluate if your team is prepared to prioritize the utilization of these features to enhance transparency and trust in your data. Tests and model descriptions will not write themselves. When it comes to good descriptions, they shouldn't come from a data engineering team that does not know how the data is used or the best data quality rules to implement. Good descriptions must involve business user review at a minimum.
The goal of dbt is to empower various teams including IT and business users by using the same tooling. Consider if your organization is ready to foster this cross-functional collaboration. When you implement dbt correctly, you will empower anyone who knows SQL to contribute. You can have multiple teams contribute to the insight delivery process and still ensure proper governance and testing before updating production.
Automation is key to achieving efficiency with dbt. Implementing automated deployment, testing, and CI/CD pipelines can significantly improve your workflows. If you aren’t ready to automate, the benefits of dbt may not be fully realized. If you simply put in dbt without thinking about the end-to-end process and the failure points, you will miss opportunities for errors. The spaghetti code you have today didn't happen just because you were not using dbt.
dbt is a framework, not a silver bullet. Merely changing tools without altering your underlying processes will not solve existing issues. This is a huge issue with organizations that have not done the work to create a data-driven culture. Assess if your team is ready to adopt better naming conventions and more structured processes to make data more understandable.
Data immaturity might manifest as a reliance on manual processes, lack of data quality controls, or poor documentation practices. These factors can derail the effective implementation of dbt since dbt thrives in environments where data practices are robust and standardized. In other words, dbt alone will not solve these problems.
Ensuring your organization is ready for the changes that come with implementing dbt is not just best practice, it is essential for success. By thoroughly assessing your readiness, you can avoid technical debt, optimize your workflows, and fully harness the power of dbt. Remember, dbt is a powerful tool, but its effectiveness depends on the readiness of your organization to improve data practices and its alignment with dbt’s philosophy.

Digital transformation is often seen through the lens of technological advancement and process optimization. Most blog posts and guides out there revolve around implementing new software, automating tasks, and digitizing operations. Yet, there's a pivotal element that's frequently overlooked in these discussions, especially when it comes to an enterprise: the mindset and culture within an organization. This article aims to shed light on why this is crucial in achieving true digital transformation. But first, let's investigate what digital transformation is and why it is important.
Digital transformation is the integration of digital technology into all areas of a business, fundamentally changing how it operates and delivers value to customers. It is more than just a technological upgrade; it is a cultural shift that requires organizations to continually challenge the status quo, experiment, and get comfortable with failure. This often means walking away from long-standing business processes that companies were built upon to embrace new ways of working. Most organizations find this part the most challenging.
To achieve digital transformation in an enterprise 9 times out of 10 there must be a change in company culture. However, changing a company's culture is a formidable task. It is rare to hear statements like, “We need to fundamentally change our problem-solving approach.” This realization became clear to me through my past experiences as I noticed that managers often lacked the influence to drive change at the highest organizational levels. Additionally, the pressure to deliver quick results within budget cycles frequently hindered genuine cultural transformation.
During my tenure at various companies, under numerous managers, the consistent message was the need for improvement. However, I have come to understand that organizations, much like fireflies, develop their own rhythms. It is this unique rhythm that sets apart innovative and transformative companies from those that merely follow without achieving similar success. What do I mean by this? Let’s turn to nature for an explanation.
Nature is fascinating, especially when observing how hundreds or thousands of fireflies can synchronize their flashes.
In organizations, a similar phenomenon occurs. People will sync up and follow the status quo, even if it is not what is best for the organization. This dramatically hinders digital transformation because the loudest are not always right and yet they cause others to sync up with them. This will cause innovation to be stopped in its tracks.
In addition to this firefly phenomenon, often action differs from ambition. I recall a staff meeting with a former CIO discussing a future less dependent on Microsoft and more open to non-Windows devices. It was clear that iPhones were going to change the corporate landscape. Despite this, every new tool implemented was still optimized for Internet Explorer. This discrepancy between ambition and action often drives analytical people like me to frustration. To effect change, persistence is key. I have had ideas initially dismissed as “not my job,” only to see one later turn into a patented invention.
This manifests itself in other ways as well; have you ever seen a company advocate for fewer meetings while simultaneously criticizing those who do not include “everyone” in decision-making? I have been in such situations and can attest that decision-making by committee is not inherently superior. In fact, the more people involved in an initiative, the less effective it tends to be. This, I believe, is due to the Dunning-Kruger effect.
The more people you involve in a transformation initiative, the more likely the discussions will deteriorate to bike shedding discussions. When there is a disconnect between what is said and what is done, people take notice, and it breeds discontent.

Even in my most successful transformation initiatives, the radius of transformation has been limited to my sphere of influence. Sure, some of my tools and processes got global and cross-functional acceptance, but the underlying principles never took hold because they were too radical for the organization at the time. I was not part of the IT organization so the things I did were typically seen as shadow IT. Instead of focusing on what I should not be doing, it would have been more progressive for them to see how I was practicing Agile principles. They could have inquired about how my project was doing DevOps before that was in style, or how it was that this non-sanctioned product was extremely well received and people sought me out to help them improve their processes.
This means if you want the organization to be more innovative, you need to find the obstacles that hold people back from being innovative. Often politics and bureaucracy impact an initiative more than the solution itself. If you force everyone to comply with existing tools and processes, then you are imposing a constraint on the team that will limit innovation.
A typical way this manifests itself is leadership pushing the idea that one platform or process can solve every need. This can come in the form of imposing that a particular group do data transformation, or a visualization tool be the way that everyone can do analytics. I have never seen one tool that is good at everything, and you end up balancing the single solution with an unmanageable array of tools and processes. A healthy organization is a learning organization that is always open to improvement. When management encourages pushing boundaries and not taking anything as fact then the company can innovate.
A great example of driving innovation is seen in the approach of Steve Jobs, co-founder of Apple Inc. Jobs was known for his ability to challenge conventional wisdom and existing standards in the technology industry. He emphasized the importance of understanding the fundamental principles underlying a problem to innovate and create groundbreaking solutions. One notable instance was the development of the iPhone, which revolutionized the smartphone industry. Jobs and his team did not just improve on existing phones; they rethought what a phone could be, focusing on user experience and simplicity. This approach led to a product that dramatically altered how people interact with technology.
As a leader, you need to look for the fireflies who are using first principles like Steve Jobs to deliver innovative solutions and nurture, or create, a corporate culture that truly challenges what has been done without artificial constraints.
Reasoning by first principles removes the impurity of assumptions and conventions. What remains is the essentials. It’s one of the best mental models you can use to improve your thinking because the essentials allow you to see where reasoning by analogy might lead you astray.
The transformative and innovative thinkers will either comply or leave, both of which are undesirable. In my case I tended to leave. In every organization where I have worked, I have managed to make a significant impact, often through sheer determination. During my time at one such company, our goal was to introduce a data catalog. By analyzing the problem I was able to discern what was essential for our organization vs an elaborate and idealistic vision which was capable of doing everything. While the IT organization felt it would be better to create a home-grown catalog I understood that our biggest obstacle was getting people to use a catalog in the first place, so time to market was critical. I found that Alation met the needs we had and IT kept to their vision to build an all encompassing catalog, In 3 months I had deployed Alation and 1.5 years later, the home grown solution was a tenth as good. This approach of breaking down the problem to its basic elements and building up from there was critical. It is often underestimated how challenging it is to develop and maintain custom software. This experience highlights the effectiveness of first principles thinking in deploying practical and efficient solutions.
The reality is that not everyone possesses the tenacity to advocate for change, especially in the face of substantial resistance. Not only that, but I have also witnessed people being ostracized for thinking differently, while others were promoted for fitting in. It is crucial to seek out divergent thinkers and consider the validity of their perspectives, instead of forcing them to conform. This is why true digital transformation necessitates a shift in culture.
When an individual, much like a firefly that does not flash in unison with the rest, finds themselves out of sync with the collective rhythm, they face a decision: conform and synchronize with the group or venture out to find a new collective that resonates with their unique spark.
True transformational change must come from the top. Achieving enterprise digital transformation requires a deep and bold questioning of the status quo. We must critically assess our processes: Is a particular task truly necessary for a certain group? Can we identify and eliminate inefficiencies? Will adding another layer of approval or inspection genuinely enhance outcomes? It is essential to remember that human behavior often has a more profound impact than any technology or process we implement. When decision-making is centralized within one group, solutions are inevitably skewed to reflect their viewpoint. Too often, I have witnessed decisions justified by cost considerations that, upon closer inspection, proved detrimental in the broader context. An effective strategy involves analyzing the entire system, recognizing that optimizing the whole may require accepting lower efficiency in some areas.
The key is to align with the needs of users and the organization and engage leadership in this journey. With a united front, tackling the 'corporate dragons' becomes a more manageable endeavor. One practical approach is employing methodologies like the 'Job to be Done' framework.
Company culture and change management are frequently overlooked in the pursuit of process improvement. Employees operate within their limitations, while management ponders the lack of innovation and agility compared to other companies. The simpler path might seem to be increasing staff or updating technology, but the heart of transformation lies in the mindset of the organization. Leaders aiming for a lasting impact must embrace first principles thinking, ready to scrutinize and challenge established norms. Transformational change rarely stems from incremental improvements; truly innovative companies are those that dare to think and act differently. The organization thus faces a pivotal choice: will it adapt to a new rhythm, or compel its 'new fireflies' to fall in line with the existing order?
The top dbt alternatives include Datacoves, SQLMesh, Bruin Data, Dataform, and visual ETL tools such as Alteryx, Matillion, and Informatica. Code-first engines offer stronger rigor, testing, and CI/CD, while GUI platforms emphasize ease of use and rapid prototyping. Teams choose these alternatives when they need more security, governance, or flexibility than dbt Core or dbt Cloud provide.
The top dbt alternatives include Datacoves, SQLMesh, Bruin Data, Dataform, and GUI-based ETL tools such as Alteryx, Matillion, and Informatica.
Teams explore dbt alternatives when they need stronger governance, private deployments, or support for Python and code-first workflows that go beyond SQL. Many also prefer GUI-based ETL tools for faster onboarding. Recent market consolidation, including Fivetran acquiring SQLMesh and merging with dbt Labs, has increased concerns about vendor lock-in, which makes tool neutrality and platform flexibility more important than ever.
Teams look for dbt alternatives when they need stronger orchestration, consistent development environments, Python support, or private cloud deployment options that dbt Cloud does not provide.
Organizations evaluating dbt alternatives typically compare tools across three categories. Each category reflects a different approach to data transformation, development preferences, and organizational maturity.
Organizations consider alternatives to dbt Cloud when they need more flexibility, stronger security, or support for development workflows that extend beyond dbt. Teams comparing platform options often begin by evaluating the differences between dbt Cloud vs dbt Core.
Running enterprise-scale ELT pipelines often requires a full orchestration layer, consistent development environments, and private deployment options that dbt Cloud does not provide. Costs can also increase at scale (see our breakdown of dbt pricing considerations), and some organizations prefer to avoid features that are not open source to reduce long-term vendor lock-in.
This category includes platforms that deliver the benefits of dbt Cloud while providing more control, extensibility, and alignment with enterprise data platform requirements.
Datacoves provides a secure, flexible platform that supports dbt, SQLMesh, and Bruin in a unified environment with private cloud or VPC deployment.
Datacoves is an enterprise data platform that serves as a secure, flexible alternative to dbt Cloud. It supports dbt Core, SQLMesh, and Bruin inside a unified development and orchestration environment, and it can be deployed in your private cloud or VPC for full control over data access and governance.
Benefits
Flexibility and Customization:
Datacoves provides a customizable in-browser VS Code IDE, Git workflows, and support for Python libraries and VS Code extensions. Teams can choose the transformation engine that fits their needs without being locked into a single vendor.
Handling Enterprise Complexity:
Datacoves includes managed Airflow for end-to-end orchestration, making it easy to run dbt and Airflow together without maintaining your own infrastructure. It standardizes development environments, manages secrets, and supports multi-team and multi-project workflows without platform drift.
Cost Efficiency:
Datacoves reduces operational overhead by eliminating the need to maintain separate systems for orchestration, environments, CI, logging, and deployment. Its pricing model is predictable and designed for enterprise scalability.
Data Security and Compliance:
Datacoves can be deployed fully inside your VPC or private cloud. This gives organizations complete control over identity, access, logging, network boundaries, and compliance with industry and internal standards.
Reduced Vendor Lock-In:
Datacoves supports dbt, SQLMesh, and Bruin Data, giving teams long-term optionality. This avoids being locked into a single transformation engine or vendor ecosystem.
Running dbt Core yourself is a flexible option that gives teams full control over how dbt executes. It is also the most resource-intensive approach. Teams choosing DIY dbt Core must manage orchestration, scheduling, CI, secrets, environment consistency, and long-term platform maintenance on their own.
Benefits
Full Control:
Teams can configure dbt Core exactly as they want and integrate it with internal tools or custom workflows.
Cost Flexibility:
There are no dbt Cloud platform fees, but total cost of ownership often increases as the system grows.
Considerations
High Maintenance Overhead:
Teams must maintain Airflow or another orchestrator, build CI pipelines, manage secrets, and keep development environments consistent across users.
Requires Platform Engineering Skills:
DIY dbt Core works best for teams with strong Kubernetes, CI, Python, and DevOps expertise. Without this expertise, the environment becomes fragile over time.
Slow to Scale:
As more engineers join the team, keeping dbt environments aligned becomes challenging. Onboarding, upgrades, and platform drift create operational friction.
Security and Compliance Responsibility:
Identity, permissions, logging, and network controls must be designed and maintained internally, which can be significant for regulated organizations.
Teams that prefer code-first tools often look for dbt alternatives that provide strong SQL modeling, Python support, and seamless integration with CI/CD workflows and automated testing. These are part of a broader set of data transformation tools. Code-based ETL tools give developers greater control over transformations, environments, and orchestration patterns than GUI platforms. Below are four code-first contenders that organizations should evaluate.
Code-first dbt alternatives like SQLMesh, Bruin Data, and Dataform provide stronger CI/CD integration, automated testing, and more control over complex transformation workflows.
SQLMesh is an open-source framework for SQL and Python-based data transformations. It provides strong visibility into how changes impact downstream models and uses virtual data environments to preview changes before they reach production. SQLMesh was originally developed by Tobiko Data, acquired by Fivetran in 2025, and donated to the Linux Foundation in March 2026.
Benefits
Efficient Development Environments:
Virtual environments reduce unnecessary recomputation and speed up iteration.
Community Governance Under the Linux Foundation:
In March 2026, Fivetran contributed SQLMesh to the Linux Foundation, establishing an open community governance model. Founding members including Benzinga, CloudKitchens, Harness, and others joined to support its ongoing development. The project remains publicly available on GitHub, which increases its neutrality and long-term independence from any single vendor.
Considerations
Governance Is New:
While Linux Foundation stewardship is a positive signal for openness, the community governance model is still in its early stages. It remains to be seen how active and independent the contributor community will become over time.
Dataform is a SQL-based transformation framework focused specifically for BigQuery. It enables teams to create table definitions, manage dependencies, document models, and configure data quality tests inside the Google Cloud ecosystem. It also provides version control and integrates with GitHub and GitLab.
Benefits
Centralized BigQuery Development:
Dataform keeps all modeling and testing within BigQuery, reducing context switching and making it easier for teams to collaborate using familiar SQL workflows.
Considerations
Focused Only on the GCP Ecosystem:
Because Dataform is geared toward BigQuery, it may not be suitable for organizations that use multiple cloud data warehouses.
AWS Glue is a serverless data integration service that supports Python-based ETL and transformation workflows. It works well for organizations operating primarily in AWS and provides native integration with services like S3, Lambda, and Athena.
Benefits
Python-First ETL in AWS:
Glue supports Python scripts and PySpark jobs, making it a good fit for engineering teams already invested in the AWS ecosystem.
Considerations
Requires Engineering Expertise:
Glue can be complex to configure and maintain, and its Python-centric approach may not be ideal for SQL-first analytics teams.
Bruin is a modern SQL-based data modeling framework designed to simplify development, testing, and environment-aware deployments. It offers a familiar SQL developer experience while adding guardrails and automation to help teams manage complex transformation logic.
Benefits
Modern SQL Modeling Experience:
Bruin provides a clean SQL-first workflow with strong dependency management and testing.
Considerations
Growing Ecosystem:
Bruin is newer than dbt and has a smaller community and fewer third-party integrations.
While code-based transformation tools provide the most flexibility and long-term maintainability, some organizations prefer graphical user interface (GUI) tools. These platforms use visual, drag-and-drop components to build data integration and transformation workflows. Many of these platforms fall into the broader category of no-code ETL tools. GUI tools can accelerate onboarding for teams less comfortable with code editors and may simplify development in the short term. Below are several GUI-based options that organizations often consider as dbt alternatives.
GUI-based dbt alternatives such as Matillion, Informatica, and Alteryx use drag-and-drop interfaces that simplify development and accelerate onboarding for mixed-skill teams.
Matillion is a cloud-based data integration platform that enables teams to design ETL and transformation workflows through a visual, drag-and-drop interface. It is built for ease of use and supports major cloud data warehouses such as Amazon Redshift, Google BigQuery, and Snowflake.
Benefits
User-Friendly Visual Development:
Matillion simplifies pipeline building with a graphical interface, making it accessible for users who prefer low-code or no-code tooling.
Considerations
Limited Flexibility for Complex SQL Modeling:
Matillion’s visual approach can become restrictive for advanced transformation logic or engineering workflows that require version control and modular SQL development.
Informatica is an enterprise data integration platform with extensive ETL capabilities, hundreds of connectors, data quality tooling, metadata-driven workflows, and advanced security features. It is built for large and diverse data environments.
Benefits
Enterprise-Scale Data Management:
Informatica supports complex data integration, governance, and quality requirements, making it suitable for organizations with large data volumes and strict compliance needs.
Considerations
High Complexity and Cost:
Informatica’s power comes with a steep learning curve, and its licensing and operational costs can be significant compared to lighter-weight transformation tools.
Alteryx is a visual analytics and data preparation platform that combines data blending, predictive modeling, and spatial analysis in a single GUI-based environment. It is designed for analysts who want to build workflows without writing code and can be deployed on-premises or in the cloud.
Benefits
Powerful GUI Analytics Capabilities:
Alteryx allows users to prepare data, perform advanced analytics, and generate insights in one tool, enabling teams without strong coding skills to automate complex workflows.
Considerations
High Cost and Limited SQL Modeling Flexibility:
Alteryx is one of the more expensive platforms in this category and is less suited for SQL-first transformation teams who need modular modeling and version control.
Azure Data Factory (ADF) is a fully managed, serverless data integration service that provides a visual interface for building ETL and ELT pipelines. It integrates natively with Azure storage, compute, and analytics services, allowing teams to orchestrate and monitor pipelines without writing code.
Benefits
Strong Integration for Microsoft-Centric Teams:
ADF connects seamlessly with other Azure services and supports a pay-as-you-go model, making it ideal for organizations already invested in the Microsoft ecosystem.
Considerations
Limited Transformation Flexibility:
ADF excels at data movement and orchestration but offers limited capabilities for complex SQL modeling, making it less suitable as a primary transformation engine
Talend provides an end-to-end data management platform with support for batch and real-time data integration, data quality, governance, and metadata management. Talend Data Fabric combines these capabilities into a single low-code environment that can run in cloud, hybrid, or on-premises deployments.
Benefits
Comprehensive Data Quality and Governance:
Talend includes built-in tools for data cleansing, validation, and stewardship, helping organizations improve the reliability of their data assets.
Considerations
Broad Platform, Higher Operational Complexity:
Talend’s wide feature set can introduce complexity, and teams may need dedicated expertise to manage the platform effectively.
SQL Server Integration Services is part of the Microsoft SQL Server ecosystem and provides data integration and transformation workflows. It supports extracting, transforming, and loading data from a wide range of sources, and offers graphical tools and wizards for designing ETL pipelines.
Benefits
Strong Fit for SQL Server-Centric Teams:
SSIS integrates deeply with SQL Server and other Microsoft products, making it a natural choice for organizations with a Microsoft-first architecture.
Considerations
Not Designed for Modern Cloud Data Warehouses:
SSIS is optimized for on-premises SQL Server environments and is less suitable for cloud-native architectures or modern ELT workflows.
Recent consolidation, including Fivetran acquiring SQLMesh and merging with dbt Labs, has increased concerns about vendor lock-in and pushed organizations to evaluate more flexible transformation platforms.
Organizations explore dbt alternatives when dbt no longer meets their architectural, security, or workflow needs. As teams scale, they often require stronger orchestration, consistent development environments, mixed SQL and Python workflows, and private deployment options that dbt Cloud does not provide.
Some teams prefer code-first engines for deeper CI/CD integration, automated testing, and strong guardrails across developers. Others choose GUI-based tools for faster onboarding or broader integration capabilities. Recent market consolidation, including Fivetran acquiring SQLMesh and merging with dbt Labs, has also increased concerns about vendor lock-in.
These factors lead many organizations to evaluate tools that better align with their governance requirements, engineering preferences, and long-term strategy.
DIY dbt Core offers full control but requires significant engineering work to manage orchestration, CI/CD, security, and long-term platform maintenance.
Running dbt Core yourself can seem attractive because it offers full control and avoids platform subscription costs. However, building a stable, secure, and scalable dbt environment requires significantly more than executing dbt build on a server. It involves managing orchestration, CI/CD, and ensuring development environment consistency along with long-term platform maintenance, all of which require mature DataOps practices.
The true question for most organizations is not whether they can run dbt Core themselves, but whether it is the best use of engineering time. This is essentially a question of whether to build vs buy your data platform. DIY dbt platforms often start simple and gradually accumulate technical debt as teams grow, pipelines expand, and governance requirements increase.
For many organizations, DIY works in the early stages but becomes difficult to sustain as the platform matures.
The right dbt alternative depends on your team’s skills, governance requirements, pipeline complexity, and long-term data platform strategy.
Selecting the right dbt alternative depends on your team’s skills, security requirements, and long-term data platform strategy. Each category of tools solves different problems, so it is important to evaluate your priorities before committing to a solution.
If these are priorities, a platform with secure deployment options or multi-engine support may be a better fit than dbt Cloud.
Recent consolidation in the ecosystem has raised concerns about vendor dependency. Organizations that want long-term flexibility often look for:
Consider platform fees, engineering maintenance, onboarding time, and the cost of additional supporting tools such as orchestrators, IDEs, and environment management
dbt remains a strong choice for SQL-based transformations, but it is not the only option. As organizations scale, they often need stronger orchestration, consistent development environments, Python support, and private deployment capabilities that dbt Cloud or DIY dbt Core may not provide. Evaluating alternatives helps ensure that your transformation layer aligns with your long-term platform and governance strategy.
Code-first tools like SQLMesh, Bruin Data, and Dataform offer strong engineering workflows, while GUI-based tools such as Matillion, Informatica, and Alteryx support faster onboarding for mixed-skill teams. The right choice depends on the complexity of your pipelines, your team’s technical profile, and the level of security and control your organization requires.
Datacoves provides a flexible, secure alternative that supports dbt, SQLMesh, and Bruin in a unified environment. With private cloud or VPC deployment, managed Airflow, and a standardized development experience, Datacoves helps teams avoid vendor lock-in while gaining an enterprise-ready platform for analytics engineering.
Selecting the right dbt alternative is ultimately about aligning your transformation approach with your data architecture, governance needs, and long-term strategy. Taking the time to assess these factors will help ensure your platform remains scalable, secure, and flexible for your future needs.

SQL databases are great for organizing, storing, and retrieving structured data essential to modern business operations. These databases use Structured Query Language (SQL), a gold standard tool for managing and manipulating data, which is universally recognized for its reliability and robustness in handling complex queries and vast datasets.
SQL is so instrumental to database management that databases are often categorized based on their use of SQL. This has led to the distinction between SQL databases, which use Structured Query Language for managing data, and NoSQL databases, which do not rely on SQL and are designed for handling unstructured data and different data storage models. If you are looking to compare SQL databases or just want to deepen your understanding of these essential tools, this article is just for you.
Open source databases are software systems whose source code is publicly available for anyone to view, modify, and enhance. This article covers strictly open source SQL databases. Why? Because we believe that they bring additional advantages that are reshaping the data management space. Unlike proprietary databases that can be expensive and restrictive, open source databases are developed through collaboration and innovation at their core. This not only eliminates licensing fees but also creates a rich environment of community-driven enhancements. Contributors from around the globe work to refine and evolve these databases, ensuring they are equipped to meet the evolving demands of the data landscape.
Cost-effectiveness: Most open source databases are free to use, which can significantly reduce the total cost of ownership.
Flexibility and Customization: Users can modify the database software to meet their specific needs, a benefit not always available with proprietary software.
Community Support: Robust communities contribute to the development and security of these databases, often releasing updates and security patches faster than traditional software vendors.
When selecting a database, it is important to determine your primary use case. Are you frequently creating, updating, or deleting data? Or do you need to analyze large volumes of archived data that doesn't change often? The answer should guide the type of database system you choose to implement.
In this article we will be touching on OLTP and OLAP open source SQL databases. These databases are structured in different ways depending on the action they wish to prioritize analytics, transactions, or a hybrid of the two.
OLTP or Online Transaction Processing databases are designed to manage and handle high volumes of small transactions such as inserting, updating, and/or deleting small amounts of data in a database. OLTP databases can handle real-time transactional tasks due to their emphasis on speed and reliability. The design of OLTP databases is highly normalized to reduce redundancy and optimizes update/insert/delete performance. OLTP databases can be used for analytics but this is not recommended since better databases suited for analytics exist.
Use OLTP if you are developing applications that require fast, reliable, and secure transaction processing. Common use cases include but are not limited to:
E-commerce: Order placement, payment processing, customer profile management, and shopping cart updates.
Banking: Account transactions, loan processing, ATM operations, and fraud detection.
Customer Relationship Management (CRM): Tracking customer interactions, updating sales pipelines, managing customer support tickets, and monitoring marketing campaigns.
OLAP or Online Analytical Processing databases are designed to perform complex analyses and queries on large volumes of data. They are optimized for read-heavy scenarios where queries are often complicated and involve aggregations such as sums and averages across many datasets. OLAP databases are typically denormalized, which improves query performance but come with the added expense of storage space and slower update speeds.
Use OLAP if you need to perform complex analysis on large datasets to gather insights and support decision making. Common use cases include but are not limited to:
Retail Sales Data Analysis: A retail chain consolidates nationwide sales data to analyze trends, product performance, and customer preferences.
Corporate Performance Monitoring: A multinational uses dashboards to track financial, human resources, and operational metrics for strategic decision-making.
Financial Analysis and Risk Management: A bank leverages an OLAP system for financial forecasting and risk analysis using complex data-driven calculations.
In practice, many businesses will use both types of systems: OLTP systems to handle day-to-day transactions and OLAP systems to analyze data accumulated from these transactions for business intelligence and reporting purposes.
Now that we are well versed in OLTP vs OLAP, let's dive into our open source databases!
A row-oriented database, often considered the world’s most advanced open source database. PostgreSQL offers extensive features designed to handle a range of workloads from single machines to data warehouses or web services with many concurrent users.
Best Uses: Enterprise applications, complex queries, handling large volumes of data.
SQLite is a popular choice for embedded database applications, being a self-contained, high-reliability, and full-featured SQL database engine. This database is a File-based database which means that they store data in a file (or set of files) on disk, rather than requiring a server-based backend. This approach has several key characteristics and advantages such as being lightweight, portable, easy to use, and self-contained.
Best Uses: Mobile applications, small to medium-sized websites, and desktop applications.
A columnar database and offshoot of MySQL. MariaDB was created by the original developers of MySQL after concerns over its acquisition by Oracle. It is widely respected for its performance and robustness.
Best Uses: Web-based applications, cloud environments, or as a replacement for MySQL.
Firebird is a flexible relational database offering many ANSI SQL standard features that run on Linux, Windows, and a variety of Unix platforms. This database can handle a hybrid approach of OLTP and OLAP due to its multi-generational architecture and because readers do not block writers when accessing the same data.
Best Uses: Small to medium enterprise applications, particularly where complex, customizable database systems are required.
Known for its speed, ClickHouse is an open-source column-oriented, File-based database management system that is great at real-time query processing over large datasets. As mentioned earlier in the article, File-based databases bring many benefits They make use of data compression, disk storage of data, parallel processing on multiple cores, distributed processing on multiple servers and more.
Best Uses: Real-time analytics and managing large volumes of data.
Similar to SQLite, DuckDB is an embedded file-based database, however, DuckDB is a column-oriented database that is designed to execute analytical SQL queries fast and efficiently. This database has no dependencies making it a simple, efficient, and portable database. Since it is file-based this means DuckDB runs embedded within the host process, which allows for high-speed data transfer during analytics.
Best Uses: Analytical applications that require fast, in-process SQL querying capabilities.
StarRocks is a performance-oriented, columnar distributed data warehouse designed to handle real-time analytics. StarRocks also supports hybrid row-column storage. It is known for its blazing-fast massively parallel processing (MPP) abilities. Data can be ingested at a high speed and updated and deleted in real time making it perfect for real-time analytics on fresh data.
Best Uses: Real-time analytical processing on large-scale datasets.
Doris is an MPP-based, column-oriented data warehouse, aimed at providing high performance and real-time analytical processing. Doris can support highly concurrent point query scenarios and high-throughput complex analytic scenarios. Its high speed and ease of use despite working with large amounts of data make it a great option.
Best Uses: Real-time OLAP applications and scenarios demanding fast data processing and complex aggregation.
Even though Trino is not a database, but rather a query engine that allows you to query your databases, we felt it is a powerful addition to this open source list. Originally developed by Facebook and known as PrestoSQL, Trino is designed to query large data warehouses and big data systems rapidly. Since it is great for working with terabytes or petabytes of data it is an alternative to tools such as Hive or Pig. However, it can also operate on traditional relational databases and other data sources such as Cassandra. One major benefit is that Trino allows you to perform queries across different databases and data sources. This is known as query federation.
Best Uses: Distributed SQL querying for big data solutions.
While this is not a separate open source database, we felt it was a good addition to the list because Citus is an extension to PostgreSQL that that transforms your Postgres database into a distributed database. This enables it to scale horizontally.
Best Uses: Scalable PostgreSQL applications, especially those needing to handle multi-tenant applications and real-time analytics over large datasets.
Open source SQL databases provide a variety of options for organizations and developers seeking flexible, cost-effective solutions for data management. Whether your needs are for handling large data sets, real-time analytics, or robust enterprise applications, there is likely an open source database out there for you.

Data is in the spotlight as companies everywhere realize data's true potential. With big initiatives like GenAI and sophisticated data ecosystems, ensuring data quality is not just a necessity but a mandatory investment for businesses and analysts worldwide. Some people are learning the hard way that you need stable data foundations to get the results these initiatives promise.

While there are many great tools out there, the spotlight on open source tools has never been brighter. Open source software offers transparency, adaptability, and community-driven enhancements that are crucial in the rapidly evolving data landscape. This article covers 5 open source data quality tools and is current as of April 2024, so if that is something that interests you, stick around.
First things first, what is data quality? There are many definitions of data quality, but data is considered high quality if it is fit for its intended uses in operations, decision-making, and planning. In other words, data quality refers to the data's accuracy, completeness, reliability, relevance, and how up-to-date it is. In the context of data-driven decision-making, high-quality data is crucial as it directly impacts the accuracy of insights and the effectiveness of decisions. Our data foundation.
Accurate: Data that is free from errors and discrepancies.
Complete: Data that covers the necessary breadth and depth needed by the business.
Reliable: Data that has no missing elements and is consistently represented and sourced.
Relevant: Data that is applicable to the context and purposes for the business.
Current: Data that is up-to-date and timely for its purpose.
Understanding what is needed for data quality is the first step toward recognizing the importance of these tools and practices that maintain or enhance this quality.
Now we know what constitutes high quality data but what do we need to monitor to ensure that our data is high quality? The good news is these metrics tend to be universal. For maintaining high data quality, several metrics and elements should be monitored regularly:
Accuracy: Ensure that your data correctly represents reality or the source from which it came.
Completeness: Check for missing values or data segments that could lead to incorrect analysis or conclusions.
Consistency: Data across different systems or platforms should match and be consistent.
Timeliness: Data should be updated and available in a timeframe that aligns with its intended use.
Validity: Data should adhere to the relevant rules, such as data formats and value ranges.
Uniqueness: No duplicates should be present unless necessary, ensuring each entry is unique.
Integrity: There should be a relationship between datasets and records that maintains data accuracy and consistency.
By tracking these metrics, organizations can set up the essential data foundation and significantly improve the trustworthiness and utility of their data. This will lead to better outcomes and insights that can support great data initiatives of the future.
Since it is essential to track these metrics, companies are on the search for the best tool to help them improve their data quality. Here is a list of open source tools that can be leveraged to improve data quality.
Before we jump into the tool list you may have noticed that a quick google search for this topic will give me many different lists. How is our list different? Well, we are focusing on open source tools. There are many great tools out there both paid and “free” and we put quotes around free because there is no such thing as free; there are always hidden costs (hours worked) for setup and maintenance. However, we wanted to make this open source tool list because regardless of the hidden costs we believe in the following benefits of open source tools:
Transparency: Open source tools offer complete transparency in their operations and algorithms. Users can inspect, modify, and improve the code, which enhances trust and reliability.
Community: Open source projects benefit from the collective intelligence of a global community. This not only accelerates innovation and bug resolution but also provides a large pool of knowledge and support.
Flexibility: With open source, organizations are not locked into proprietary systems, allowing them to tailor tools to their specific needs and integrate them seamlessly into their existing environments.
Cost-effectiveness: While open source doesn't always mean free, it significantly reduces costs associated with licensing fees and vendor lock-in, making cutting-edge tools accessible to everyone.
Quality and Security: Continuous contributions and scrutiny by the community mean that open source tools often meet high standards of quality and security, with issues being identified and addressed rapidly.
Our selection of open source data quality tools is grounded in rigorous open source criteria. We believe that the strength of an open source project lies not just in its ability to solve complex problems but also in its community, transparency, and commitment to ongoing improvement. When compiling this list, we considered factors such as active community engagement, frequency of updates, the quality of the documentation, and ease of contribution. This ensures that the tools recommended not only meet high standards of performance and reliability but also embody the principles that make open source software a valuable asset to the data quality landscape. So without further ado, let's jump into our list.
Primary Language: SQL / YAML
Purpose & Features: dbt core is an open source tool that allows data analysts and engineers to transform data in their data warehouses by writing dynamic SQL queries, which dbt then converts into tables and views. It also supports version control, testing, and documentation, which helps maintain data integrity and reliability.
For data quality, dbt Core has some out of the box data tests which can be extended through custom made test, or by using libraries such as dbt-expectations and elementary. Testing is easily done by configuring macros in YAML files or by writing custom SQL tests. However, integrating dbt Core into your data stack can be a big task especially when it comes to scheduling. A managed dbt Core platform such as Datacoves could be a great option for saving time and money. While dbt handles only the 'T' in ELT, Datacoves’ managed dbt Core Platform ensures that the entire ELT process is smooth and interconnected, allowing your team to concentrate on deriving insights from the data. There are other dbt alternatives on the market that can also be explored which handle the "T" in the ELT process.
Who it is for: Best for teams using SQL who want to transform data directly in the warehouse and who want to follow software development best practices including unit testing in their data pipelines.


Primary Language: YAML
Purpose & Features: Soda Core is the open source component that allows users to define data quality checks in code and integrate them into workflows.
Who it's for: Teams that need data quality checks integrated into their existing Python workflows or data pipelines.

Primary Language: Python
Purpose & Features: This tool is a data quality platform that allows you to create data tests, documentation, and profiles automatically. It easily integrates into existing data processing pipelines to ensure data validation against expectations (unit tests). You can collaborate with nontechnical stakeholders by sharing the Data Docs. Data docs are Expectations, Validation Results, and other metadata translated into a human readable format as seen in the image below.
Who it's for: Data teams looking for a Pythonic way to enforce data quality rules and create automated data documentation.

Primary Language: Scala (for Apache Spark)
Purpose & Features: Deequ is an open source tool by Amazon with which you can define "unit tests" (columnar or row level) for large-scale data within the Spark ecosystem. It allows for automated checks of data quality metrics such as completeness, uniqueness, and conformity. This enables data teams to find errors early before they are consumed downstream. You can use Deequ to define your assumptions about the data in unit tests to catch any data that does not meet your assumptions. This tool works on tabular data such as CSV files, databases tables, logs and flattened JSON files.
Who it's for: Data engineers and scientists working with big data in Spark (billons of rows), particularly those focused on maintaining data quality at scale.

Primary Language: You don’t manually write data quality tests but as you make changes to your SQL data diff will work its magic.
Purpose & Features: This tool is a little different from the rest because you're not exactly writing tests to catch data quality issues. Instead, this open source Python package by Datafold lets you do development testing by spotting the differences between tables whenever you tweak your code. It's a great way to compare what's happening in your production data against your development changes, helping you see directly how those code changes are playing out in the data.
Who it's for: Data engineers and teams who need to ensure that changes in data processing and ETL logic do not negatively affect data quality.

The concept of "the best" for data quality tools is inherently tied to specific use cases. What might be an ideal solution for one organization could be less effective for another, depending on the unique challenges and requirements each face.
Before you dive into a tool, it's crucial to understand your organization's specific data quality challenges. Are you dealing with high volumes of data, requiring scalability? Or are your main issues related to data consistency and accuracy in a smaller, more controlled dataset? Identifying your primary use case will help you navigate through our top 10 tools and select the one that best fits your situation.
1. Assess Your Data Quality Needs:
Identify the primary issues you're facing with your data. Are you struggling with incomplete data, inconsistencies, outdated information, or data that's not in the right format? Understanding your main challenges will guide you toward a tool that specializes in addressing those specific problems. Once you understand your data quality challenges and objectives, match these with the strengths of the tools listed above
2. Consider Your Technical Environment:
Evaluate the technical stack you are currently using. Some data quality tools are better suited for certain environments or integrate more seamlessly with specific databases, data lakes, or processing frameworks. Choose a tool that aligns with your existing infrastructure to reduce integration headaches.
3. Evaluate Community and Support:
The strength of an open-source tool lies in its community. Look for a tool with an active community, which is evident through regular updates, vibrant forums, and extensive documentation. A strong community can provide invaluable support, from troubleshooting to best practices.
4. Check for Flexibility and Scalability:
Your data needs will evolve, so it’s important to choose a tool that is flexible and can scale with your business. Assess the tool’s ability to handle different data volumes, types, and sources. A good open-source tool should not only solve your current data quality issues but also adapt to future challenges.
5. Review Security and Compliance Features:
Data security and compliance are imperative. Be sure the tool complies with data protection regulations and offers security features to protect your data. This is especially important if you're dealing with sensitive or personal information.
6. Test Drive the Tool:
Finally, don’t hesitate to get your hands dirty. Most open-source tools are free to use, so take advantage of this by testing the tool with your data. This will give you a clear idea of the tool’s usability, effectiveness, and fit with your use case. Be sure to go into this with an open mind to get the most out of the tool.
In the era of generative AI and other lofty initiatives high-quality data is not just an option but a necessity, and embracing these open-source data quality tools can significantly enhance the reliability and accuracy of your data. Remember, the "best" tool is one that aligns closely with your specific use case offering the features and flexibility your team needs to effectively tackle your data quality challenges; it very well could be a combination of these tools. Whether you are in the world of SQL, Python, or any other programming language, there is a tool tailored to your needs. Consider factors such as ease of integration into your current data ecosystem, the learning curve for your team, and the level of community support available.
.webp)
There is no doubt about the transformative potential of big data and analytics. This is particularly true for the Life Science sector as implementing technologies and ideologies can revolutionize drug development, tailor medicines to individual needs, dramatically improve patient care and more. The data supports this, with the longest running report of Fortune 1000 CIOs by Wavestone, showing 87.9% of companies believe “investments in Data & Analytics are a Top Organizational Priority.”
Such great promise and high buy in should mean easy cultural adoption, right? Well not exactly. The 2024 report shows there has been a notable improvement; the percentage of top executives facing significant challenges in culture, people, and process/organization decreased from a staggering 90% in 2020 to 77.6% in 2024. While this reduction signifies a positive trend towards addressing these issues, the fact that more than three-quarters of leaders still encounter these problems underscores the widespread nature of these challenges. The persistently high percentage highlights the need for continued and focused efforts to overcome these barriers.
In an effort to help further lower the 77.6%, this article aims to cover the benefits of data in the Life Science sector, highlight common culture issues, and provide some solutions to the problem. If your organization is among those facing these struggles, know that you are not alone.
The life science sector stands on the brink of a digital transformation, powered by the strategic use of data. It's clear that its impact is far-reaching, transforming every facet from research and development to patient care and beyond. Below are some examples of what this data-driven culture can improve.
As we identified earlier in this article, culture, people, and process/organization challenges are the biggest obstacles for companies to achieve digital transformation and become data-driven. Identifying specific challenges is key to developing a solution.
Pharma companies tend to be risk averse due to the nature of the data they are responsible for. This leads to limitations and constraints to innovative solutions. These constraints are often accepted without understanding the rationale behind these constraints or challenging them. New technology offers new ways to manage data that were not available in the past. If a company remains the most risk averse and the most conservative this will stifle innovation. The key takeaway is that it is not only about technology but about the new process potential that this new tech provides.
This goes back to the foundation. Technology changes, initiatives change, but data truths do not. These truths involve thinking about end-to-end processes, data quality, documentation, good guidelines conventions, data governance, reducing points of failure ect. It is easy to get swept up by the latest trend and want to jump in, but you cannot build a house on quicksand; new trends like Gen AI still require these things underneath.

This starts with aligning the team. Alignment is one of the 3 core pillars to a data-driven culture. People will start out thinking they are on the same page because they are using the same terminology. But we all have different ideas influenced by our experiences. So, it is important to gather all stakeholders and go through a true alignment process which includes figuring out the current state, pain points, and aligning on the solution.
Fundamental alignment includes adopting a top-down approach. The efforts one team is making are sure to affect the efforts of another. Leadership must align and connect the dots between all moving parts and understand that things are not living in isolation. This will solve headaches downstream and ensure a smoother process.

Alignment alone won’t be enough to combat culture challenges. True alignment can lead to overly ambitious projects that may prove difficult to execute. This is the classic trap of trying to do too much at once. It is important to start with manageable, small-scale projects that can provide immediate benefits. These quick wins are vital for positively influencing the organizational culture. Additionally, they help maintain momentum: if a larger initiative is slow to yield results, these smaller successes ensure continuous progress. By allowing for ongoing adjustments and reprioritizations, these projects help prevent initiatives from being abandoned.
While the potential of big data and analytics in transforming the Life Science sector is undeniable, and investment in data is on the rise, the journey towards a data-driven culture remains one of the biggest challenges for data integration. The path forward requires a balanced approach that combines technology with fundamental changes in culture and processes. By embracing these changes, the life sciences sector can overcome existing barriers and fully harness the power of data to advance medical science and improve patient outcomes. At Datacoves we are passionate about helping companies achieve a data-driven culture. See how Datacoves helped Johnson&Johnson innovate their tech stack.
This article was inspired by RAN BioLinks’ podcast episode “Why Life Science Organizations Fail to Implement Effective Data Strategies”. The detailed conversation with Noel Gomez, a seasoned expert in data management within the life science industry, explores the critical challenges and innovative solutions for effective data strategies in healthcare.
